Hallucinations
One well-documented challenge in generative AI is hallucination. This phenomenon occurs when the model generates entirely fabricated content that appears accurate and credible. For example, if an AI lacks sufficient data on the Great Wall of China, it might invent details—for instance, stating that the Wall is lined with watchtowers every 500 feet—even though such information is not factual.

Copyright and Intellectual Property Concerns
Using copyrighted content without proper authorization poses a serious legal risk. When models are trained on copyrighted material without permission, it can lead to violations of intellectual property laws and potential litigation. For instance, Getty Images filed a lawsuit against Stable Diffusion for using millions of copyrighted images without proper consent. This scenario highlights the critical importance of monitoring training data sources and implementing robust sourcing protocols.

Regularly review and update data sourcing standards and permissions to safeguard against unintentional copyright infringements.
Bias in AI Systems
Bias in AI systems raises both legal and ethical concerns, especially when these models are integrated into decision-making processes such as hiring. If the training data is biased, the AI might produce discriminatory outcomes. For example, an AI hiring tool once automatically rejected women over 55 and men over 60, resulting in legal action from the Equal Employment Opportunity Commission. Regular audits and the use of explainability tools, such as SageMaker Clarify, are essential to detect and mitigate bias in AI systems.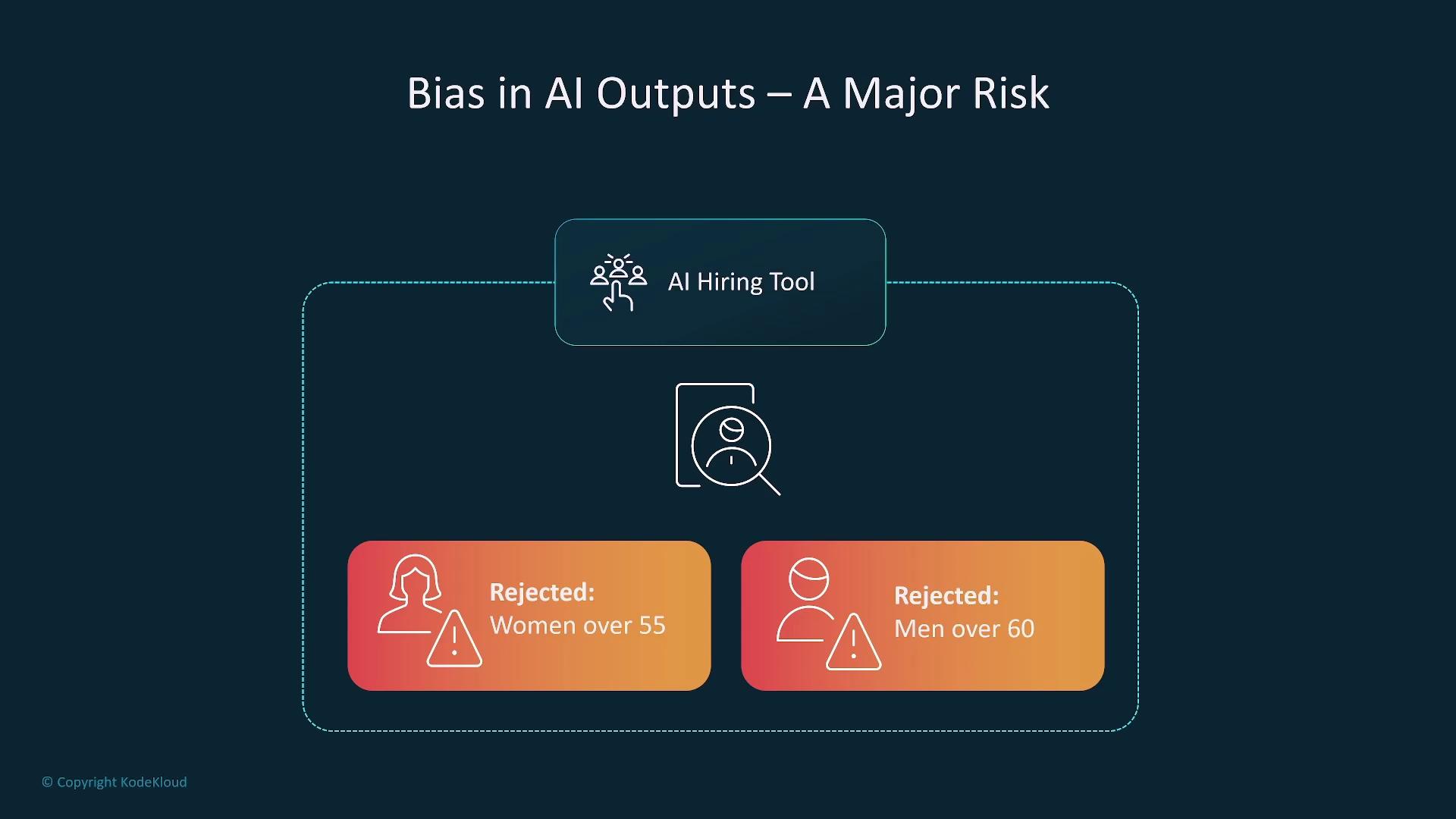

Offensive and Inappropriate Content
Generative AI may inadvertently produce offensive or inappropriate outputs, such as hate speech or graphic violence, particularly when trained on unsanitized data. Filtering mechanisms are critical to prevent the dissemination of such content and protect users from potential harm. Organizations should implement robust content guardrails to filter harmful language and manage user-generated input effectively. This approach is especially important when leveraging platforms like Amazon Bedrock.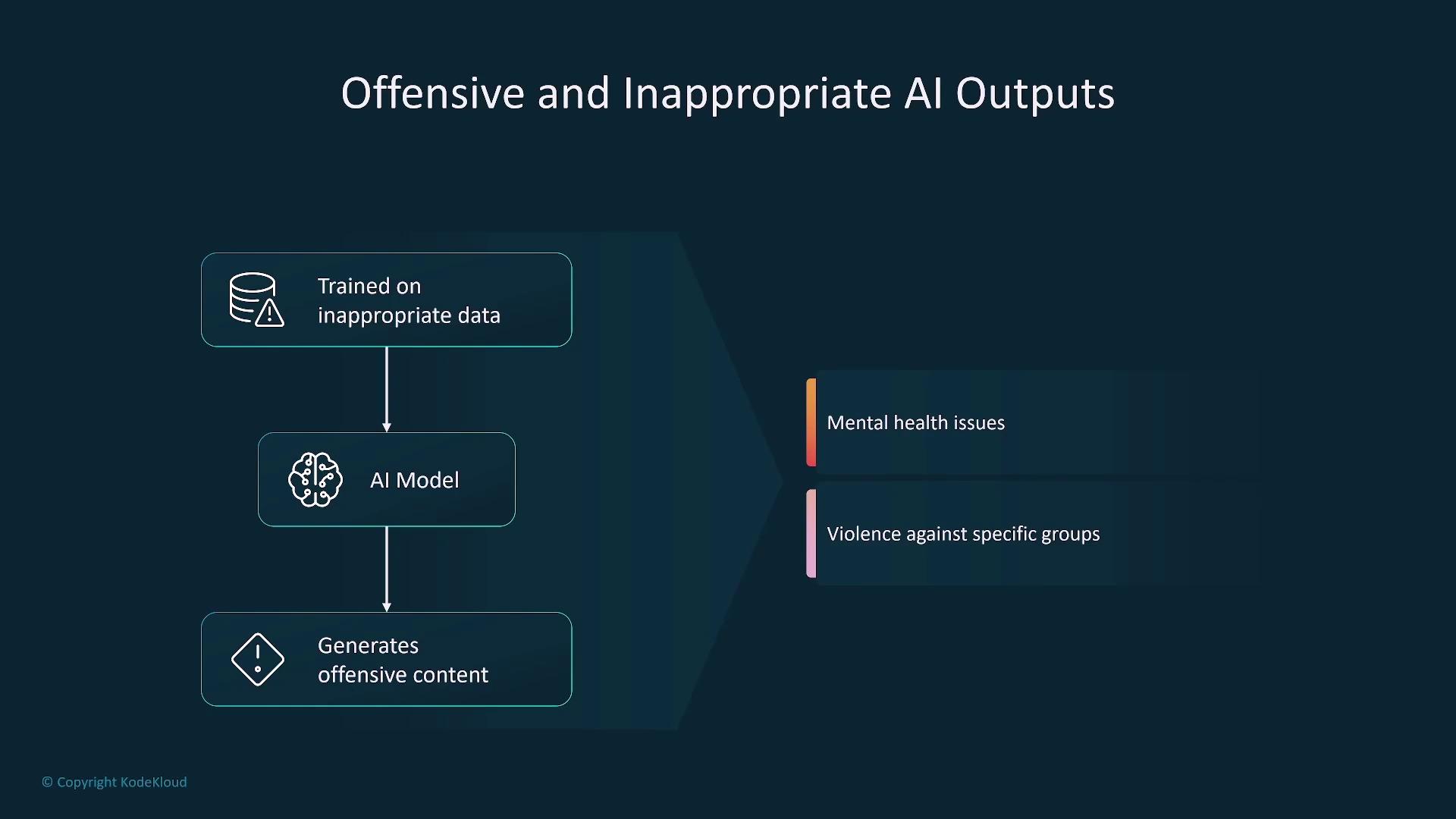
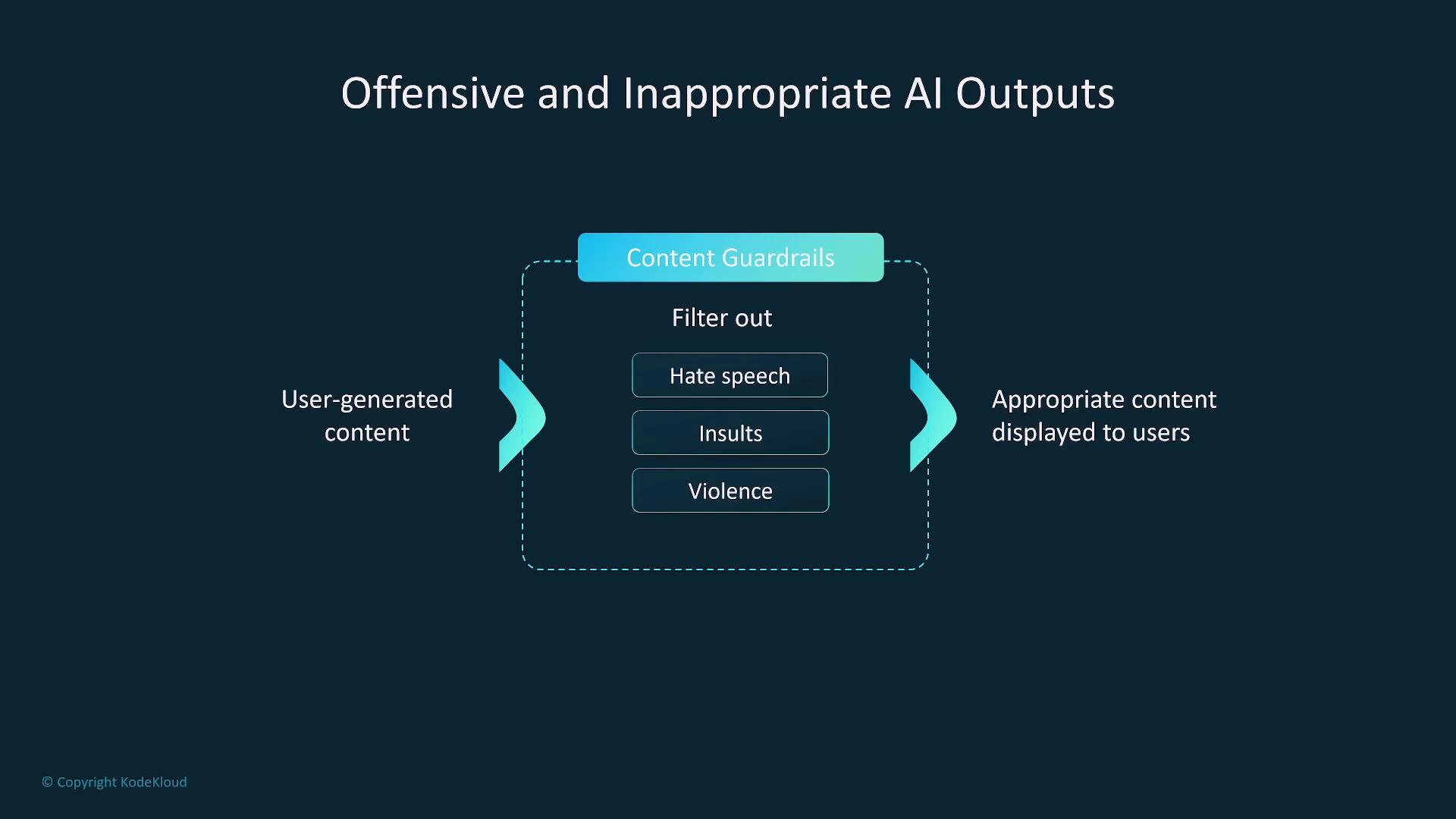
Ensure that content filtering and sanitization pipelines are continuously updated to cope with evolving language and emergent forms of harmful content.
Data Privacy and Security
Data privacy and security are paramount concerns when sensitive information, such as Personally Identifiable Information (PII), is inadvertently included in training data. Once the model retains sensitive data, it becomes exceedingly difficult to purge, resulting in long-term security risks. A strict data governance policy combined with effective data cleansing practices is essential in mitigating these risks before model training begins.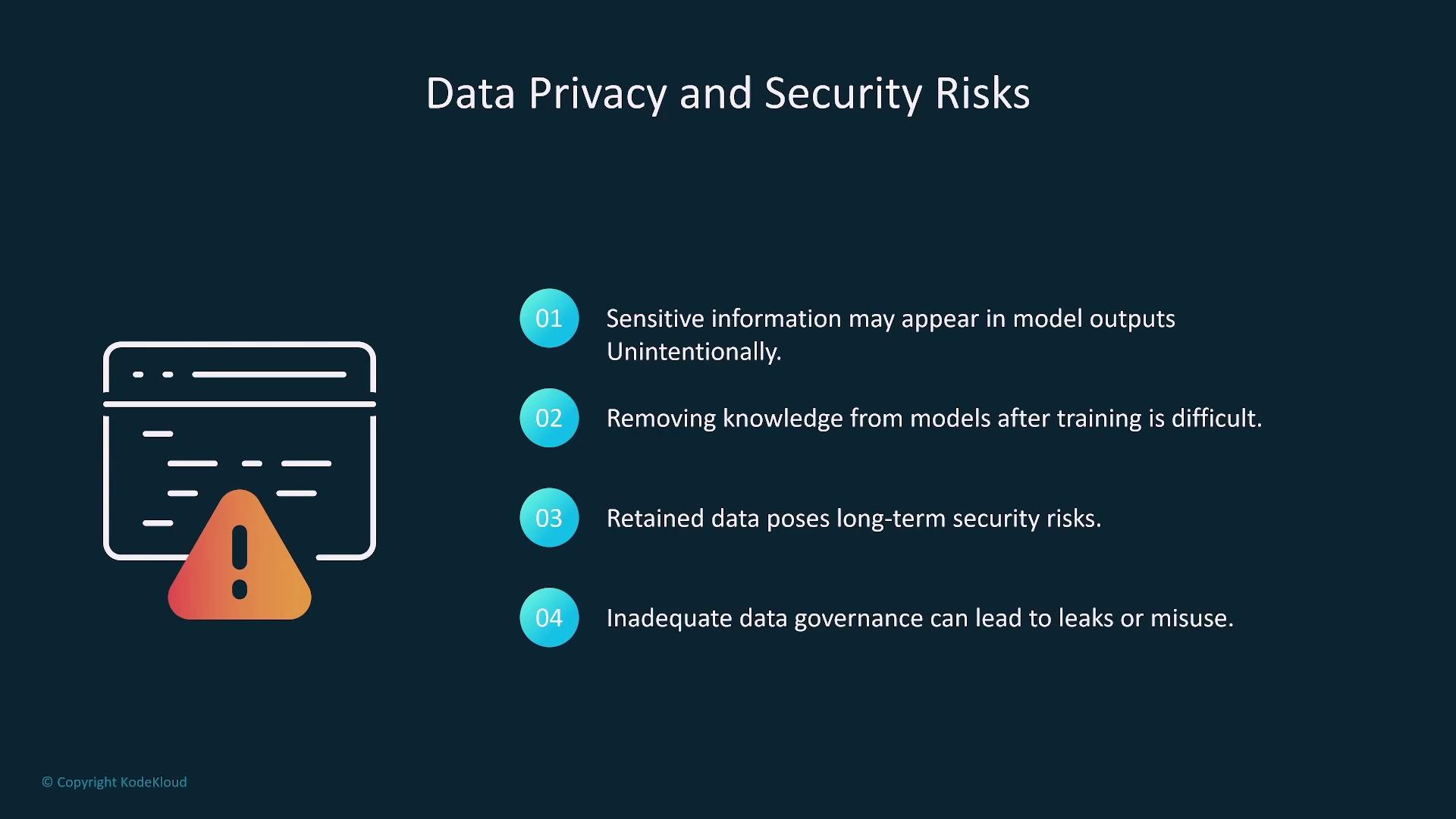
Adopt rigorous data cleansing and governance practices to ensure that no sensitive data is used during the training process.