Decoupling compute and storage
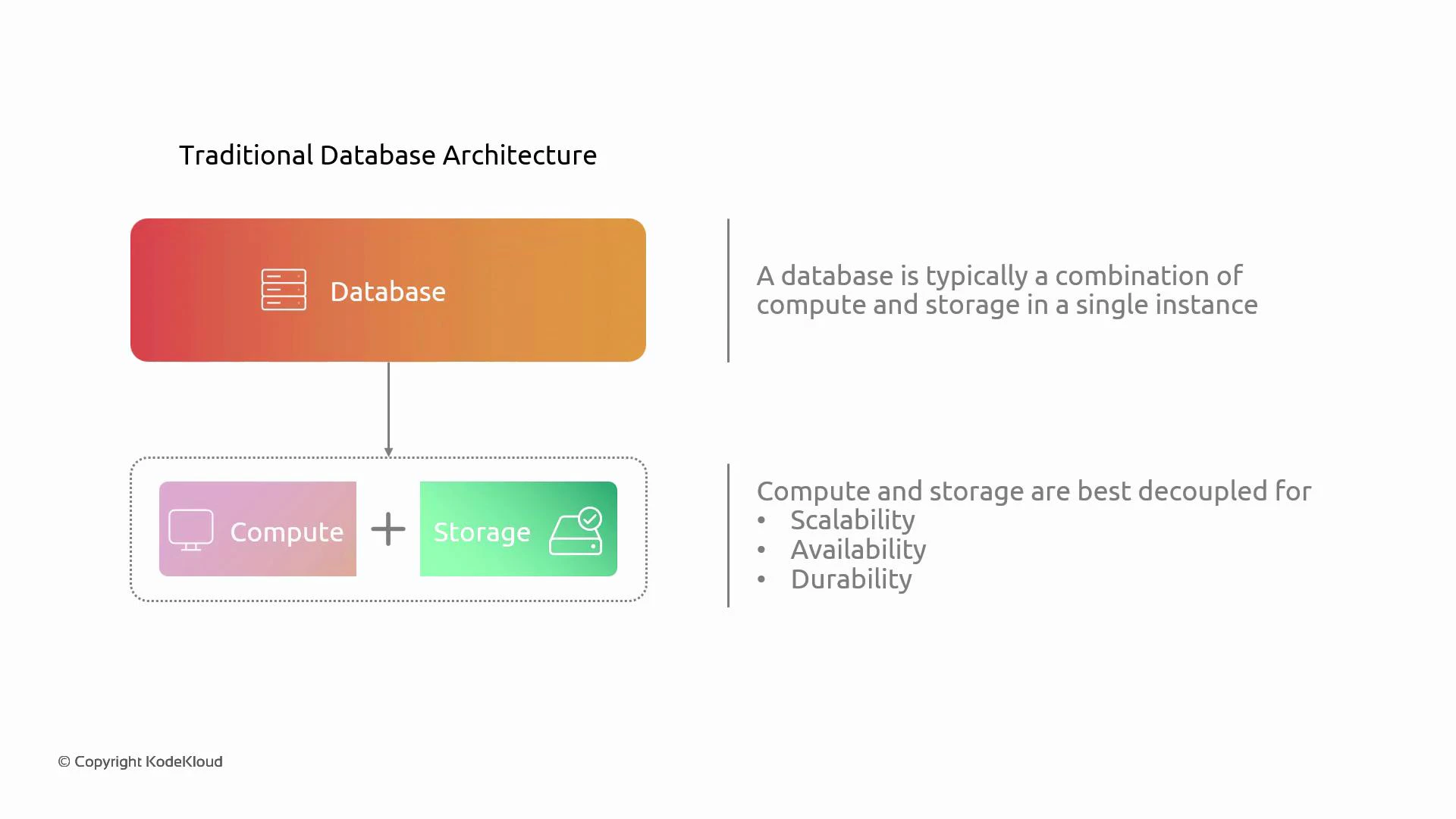
Traditional single-instance databases combine compute and storage on the same server. That approach ties two different lifecycles together:- Compute is often ephemeral and scaled independently (you may replace or resize instances).
- Storage must remain durable and highly available across failures and AZ outages.
This lesson explains Aurora’s distributed, log-structured storage architecture and how it uses replication and quorum rules to provide high durability and low-latency access.
Overview — What makes Aurora storage different
Aurora separates the storage layer from compute and implements a purpose-built, log-structured distributed storage system optimized for cloud scale and fast recovery. Key characteristics at a glance:How the distributed storage is organized
When the database writes data, Aurora divides the cluster volume into 10 GB segments (protection groups). Each segment is replicated six times across the region — typically implemented as two copies per Availability Zone across three AZs (2 × 3 = 6). This six-way replication across multiple AZs protects against individual storage node failures and AZ-level outages while enabling parallel I/O and fast rebuilds of damaged copies.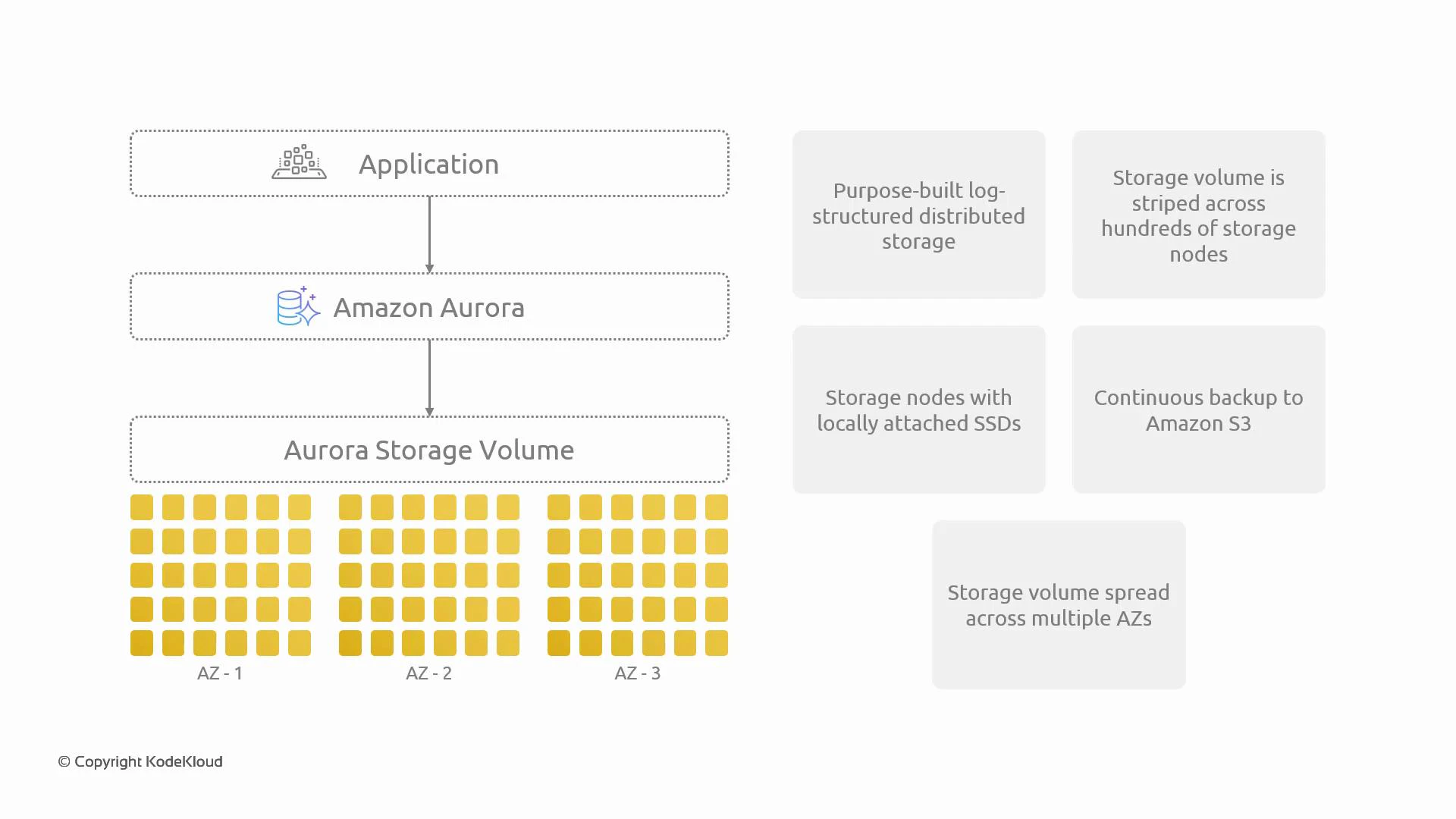
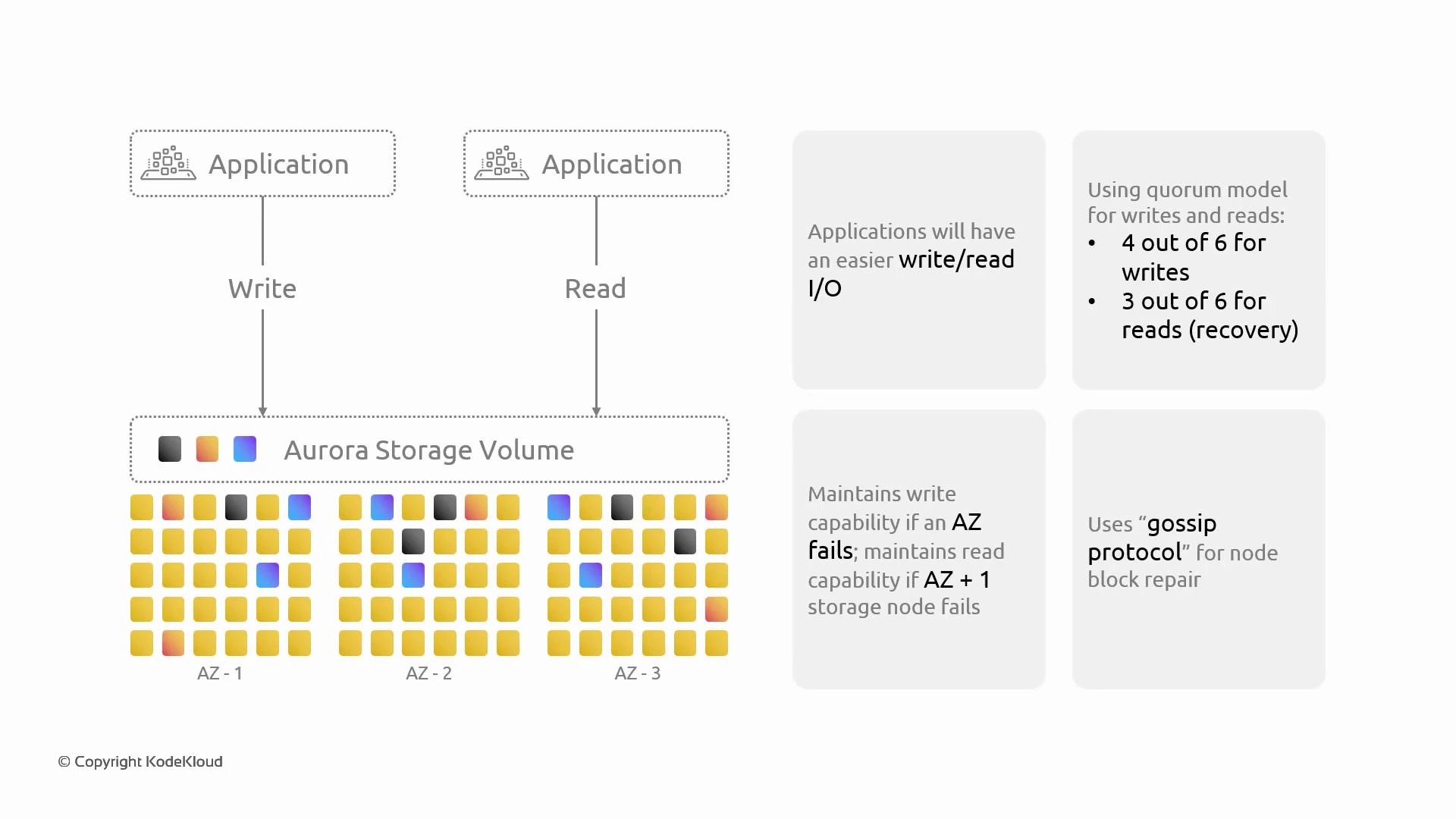
Reads, writes, and quorum behavior
Aurora uses quorum-based rules to balance durability with low-latency I/O. The cluster maintains six copies of each 10 GB segment and applies the following rules:
This design allows Aurora to acknowledge writes quickly (once 4 replicas persist the log record), while still tolerating up to two replica failures without losing durability guarantees.
Replication, consistency, and repair
Aurora’s storage layer handles replication, integrity checking, and automated repair:- Replication: Updates are propagated to the storage nodes that host the segment copies.
- Integrity: Checksums and metadata detect corruption or mismatch among copies.
- Repair: If a copy is corrupt or a node fails, Aurora copies data from healthy replicas to rebuild the missing/corrupt copy automatically.
Security and transport
- Replication traffic between storage nodes travels over the AWS network and is protected by internal integrity checks.
- Client connections to Aurora support TLS for transport-level encryption.
- When you enable encryption for an Aurora cluster, data at rest is encrypted across the storage layer, and internal replication respects those protections.
Why this design matters
Decoupling compute from a distributed, log-structured storage layer enables several operational and performance benefits:- Independent scaling: Compute instances can be added or replaced without copying the whole dataset.
- Fast failover: Failover is faster because compute can reattach to the same durable storage without a costly sync.
- High durability: Six-way replication across AZs and automatic repair reduce the risk of data loss.
- Low-latency I/O: SSD-backed striping and quorum rules let Aurora serve reads and acknowledge writes with minimal latency.
Summary
Amazon Aurora’s distributed storage is a core contributor to its performance and durability profile. The key elements are:- Log-structured append-only storage
- 10 GB protection segments
- Six-way replication across multiple AZs (typically 2 copies per AZ × 3 AZs)
- Quorum rules (4/6 writes for durability; reads from healthy replicas)
- Continuous backups to Amazon S3
- Automated detection and repair of corrupted or missing copies