How the classical double-write buffer works (high level)
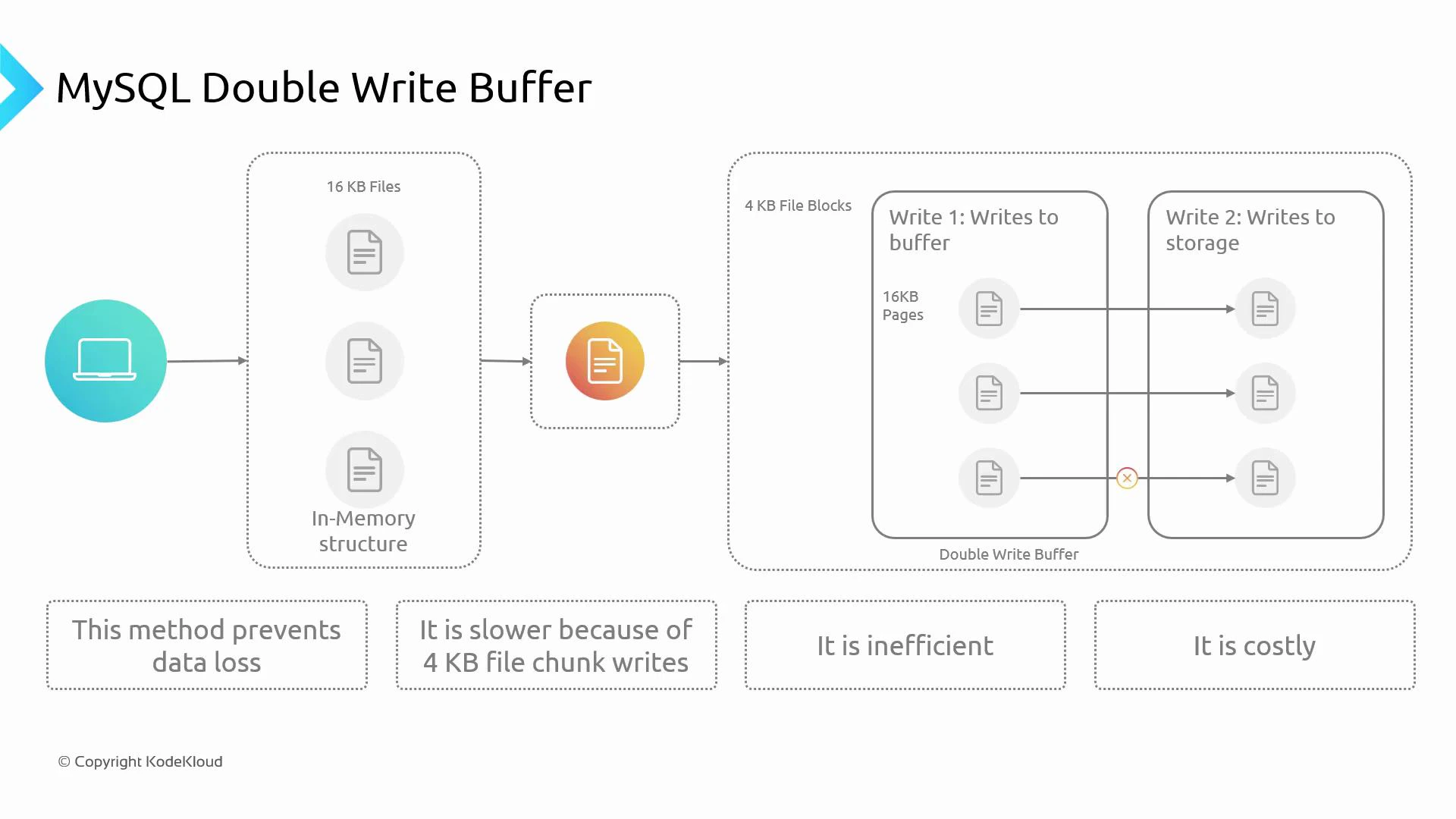
When an application writes to a relational database, several internal steps ensure durability and consistency. InnoDB uses a double-write buffer to protect data against partial page writes. At a high level:- InnoDB manages data in memory pages (default page size is 16 KB).
- Modified pages become “dirty” in the buffer pool. InnoDB writes a write-ahead redo log to guarantee durability before page flushes.
- Before flushing dirty pages to their final tablespace locations, InnoDB writes them to a double-write buffer. This buffer guards against partial-page corruption caused by hardware, firmware, or OS crashes.
- Typical storage devices use 4 KB sectors/blocks. Writing a full 16 KB page directly to a device composed of 4 KB blocks risks partial-page corruption if a failure interrupts the write. The double-write buffer writes contiguous full pages first, then copies them to their final disk locations.
- Advantage: strong protection against partial-page corruption and data loss. Drawback: extra I/O (pages are written twice), which increases write latency and affects cost on write-heavy workloads.
Rethinking where the temporary/working I/O happens
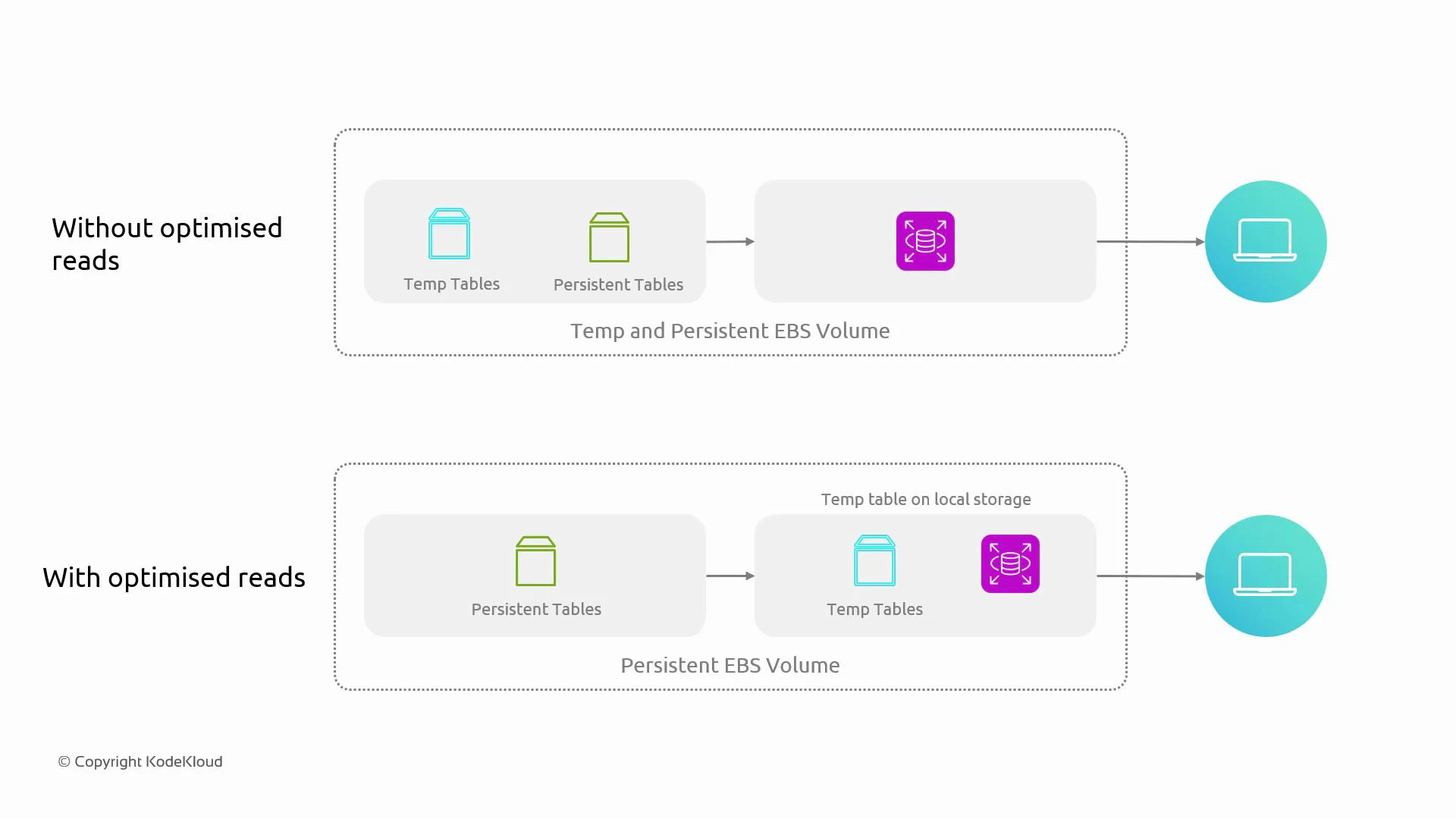
To reduce latency caused by multiple writes, we can change where intermediate I/O occurs. Instead of sending all intermediate writes to remote or network-attached volumes, place temporary and working files on storage that is physically attached to the database host (local instance store / NVMe). The pattern:- Keep transient I/O (temporary tables, sort/merge files, caches, spill files, some redo or double-write temporary areas when supported) on local, low-latency media.
- Keep authoritative persistent data (tablespaces, primary data files) on durable network storage such as EBS for backups, snapshotting, and multi-AZ replication.
How RDS applies this idea
- On RDS instance types that provide local instance store or NVMe (and where the RDS engine/configuration supports it), RDS can place temporary database files on local storage instead of EBS.
- Persistent data—authoritative tablespaces and backups—remain on EBS volumes to preserve durability and restore capability.
- This split reduces effective I/O latency for transient operations while maintaining the durability guarantees of network storage for persistent data.
- The 16 KB page vs 4 KB block concerns still apply, but local NVMe reduces the latency of intermediate steps and mitigates the performance cost of double writes.
Durability considerations
Local instance store (including NVMe) is typically ephemeral. It improves latency for temporary/working I/O but is not a durable replacement for EBS. RDS keeps persistent data on durable EBS volumes and relies on EBS for backups and restores. Before changing storage settings, ensure your backup/replication strategy and instance replacement processes account for ephemeral storage behavior.
Do not store authoritative, single-copy data on instance store. If an instance is stopped, terminated, or fails, instance-store data is lost. Always preserve durability by keeping persistent data on EBS and using regular snapshot/replication strategies.
Key points to remember
- Use local instance store / NVMe for transient, high-I/O temporary/working files when supported on the RDS instance type.
- Keep persistent data on durable EBS volumes for backup/restore and multi-AZ replication guarantees.
- Moving transient I/O to local NVMe reduces EBS I/O pressure, lowering read/write latency and improving throughput for I/O-bound workloads.
- Best suited for workloads that generate heavy temporary/working I/O (large sorts, temporary tables, spill files, heavy buffer pool flushes).

Quick comparison
When to consider optimized reads/writes
- Profiling shows heavy temporary table usage, sorts, or frequent buffer-pool flushes.
- Your workload is I/O-bound and sensitive to write latency.
- You can tolerate ephemeral local storage for temporary files and keep all persistent state on EBS.
- Your architecture includes robust backups, snapshots, or replication to handle instance replacement.
Links and references
- Amazon RDS documentation on storage and instance types
- AWS EBS introduction
- MySQL InnoDB storage engine
- MySQL InnoDB doublewrite buffer
- MySQL InnoDB redo log (write-ahead log)
- NVMe specification and resources