Prepare the demo database
I created an Aurora PostgreSQL cluster with one writer instance and made it accessible from my network. I copied the username, password, and endpoint to a secure note so I can connect using the Query Editor or a client. Open a new SQL script in the Query Editor (or use psql) and run the following statements in sequence: first run the CREATE TABLE statements, then run the INSERT statements. This will give you a simple Customers/Orders dataset to exercise queries.Performance Insights overview
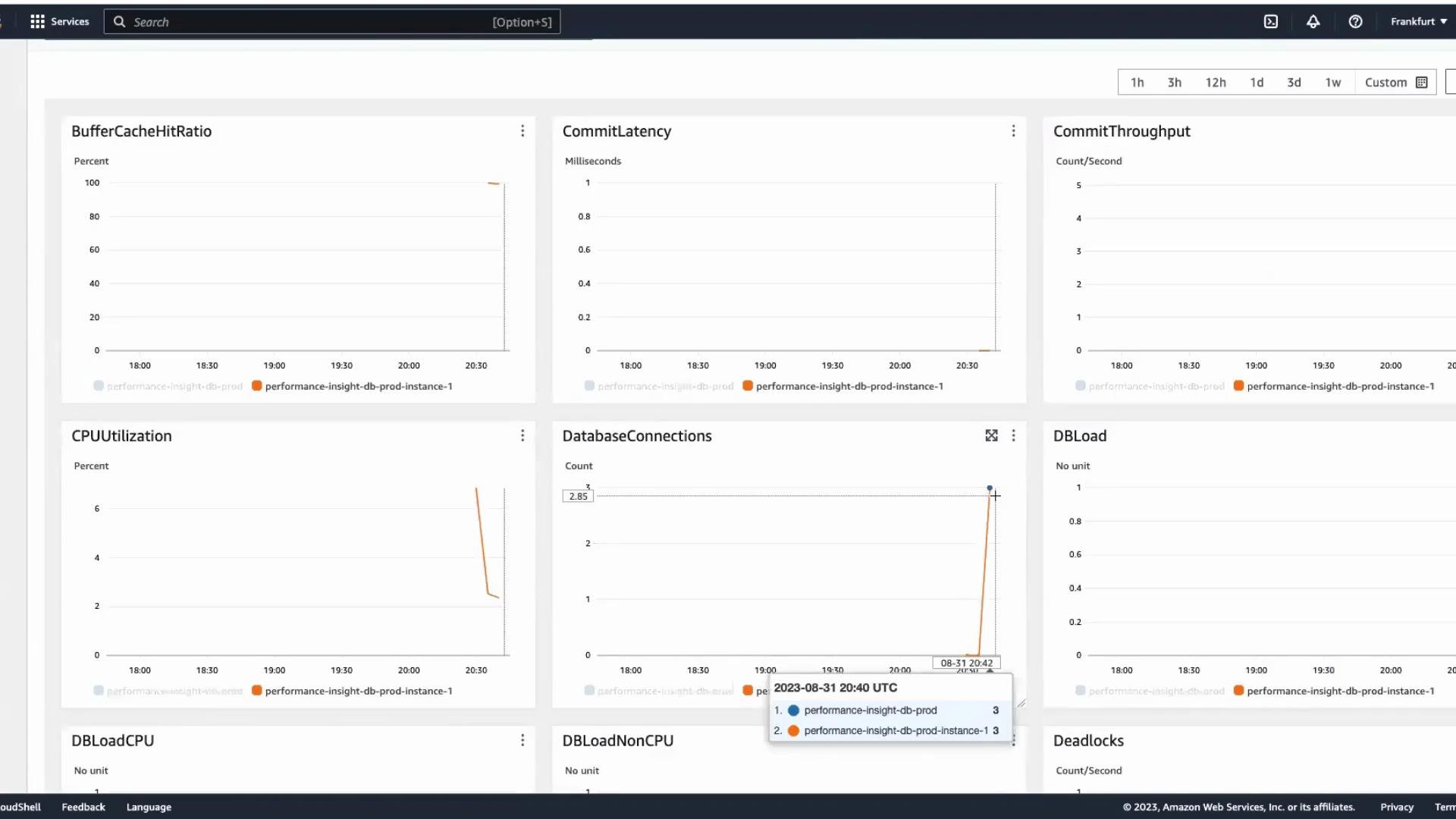
Performance Insights gives a dimensional view of database load at the SQL level. It surfaces top SQL by load, execution time, and average active sessions (AAS), and it shows which users, hosts, or applications are issuing those queries. Performance Insights must be enabled for your DB instance (either at creation or enabled later). Note that enabling Performance Insights can affect costs depending on retention and usage.Before continuing: ensure Performance Insights is enabled for your instance and review pricing/retention options. See the AWS docs for details on enabling Performance Insights and storage costs.
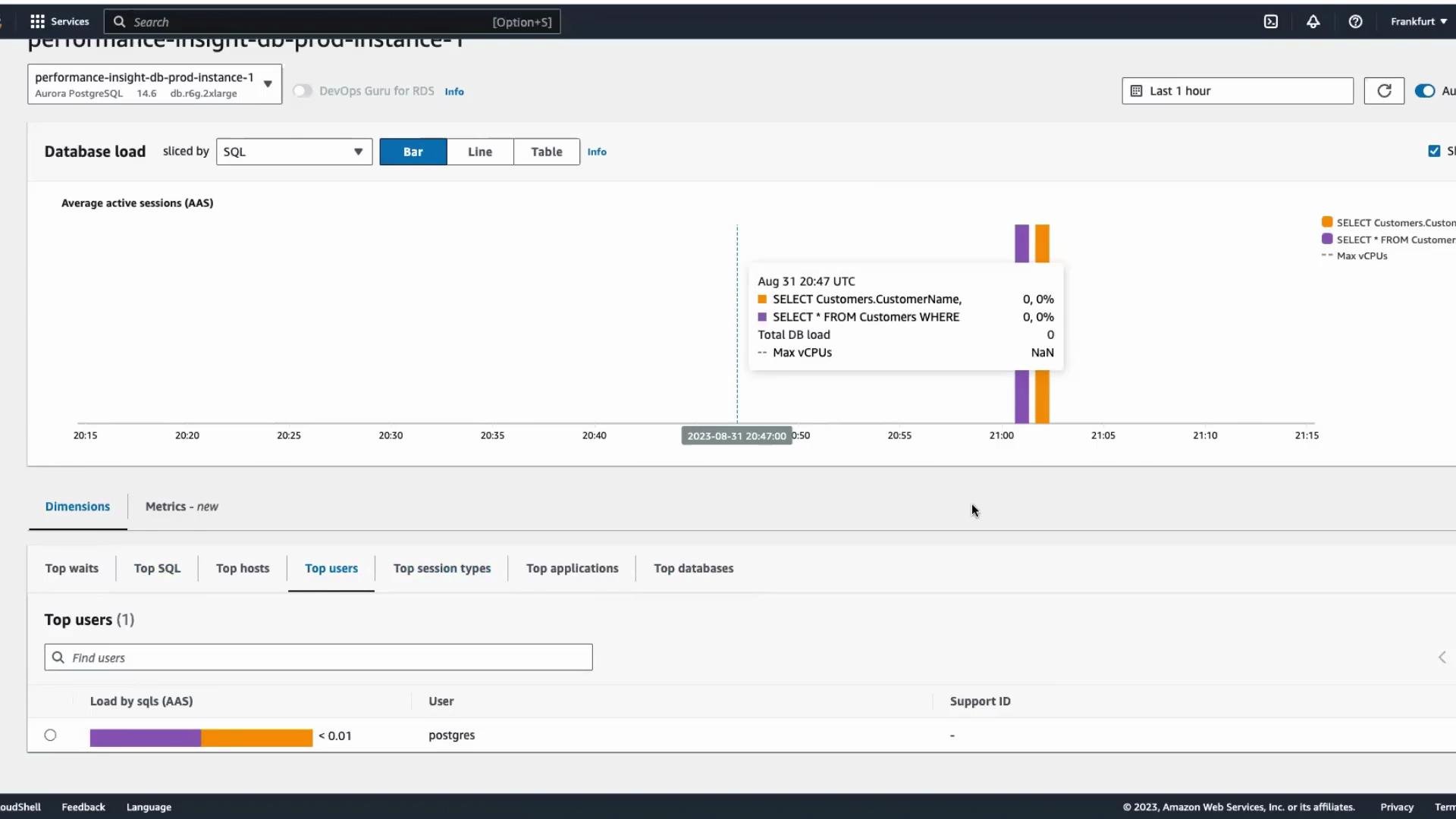
- Top SQL statements by load (AAS).
- SQL text and execution samples.
- Which database user, host, or application issued the query.
- A timeline of DBLoad so you can correlate spikes with specific queries or clients.
Quick reference — what to look for in Performance Insights
Generate load to observe query activity
To demonstrate Performance Insights capturing query activity, generate concurrent load that mixes simple point selects and heavier aggregation queries. The Python script below creates multiple threads; each thread opens a persistent connection and repeatedly runs a simple SELECT and a JOIN+aggregation.Replace the db_params values (dbname, user, password, host, port) with the connection details for your own Aurora instance before running the script.
- Default is 10 concurrent threads (adjust with main(thread_count=N)).
- Each thread opens one persistent connection and alternates between a simple point-select and a JOIN+GROUP BY aggregation.
- Random short sleeps create staggered query timing so load is spread out.
- Threads are daemonized in this example; for graceful shutdown in production use non-daemon threads with a stop flag and join.
- Identify the queries contributing most AAS.
- See which user/host is causing load spikes.
- Inspect SQL text and execution samples to plan optimizations (rewrite, indexing, or parameterization).
- Correlate DBLoad spikes with instance-level metrics like CPUUtilization or DatabaseConnections.
Further reading and references
- AWS Performance Insights documentation
- Amazon Aurora (PostgreSQL) documentation
- RDS Monitoring and metrics