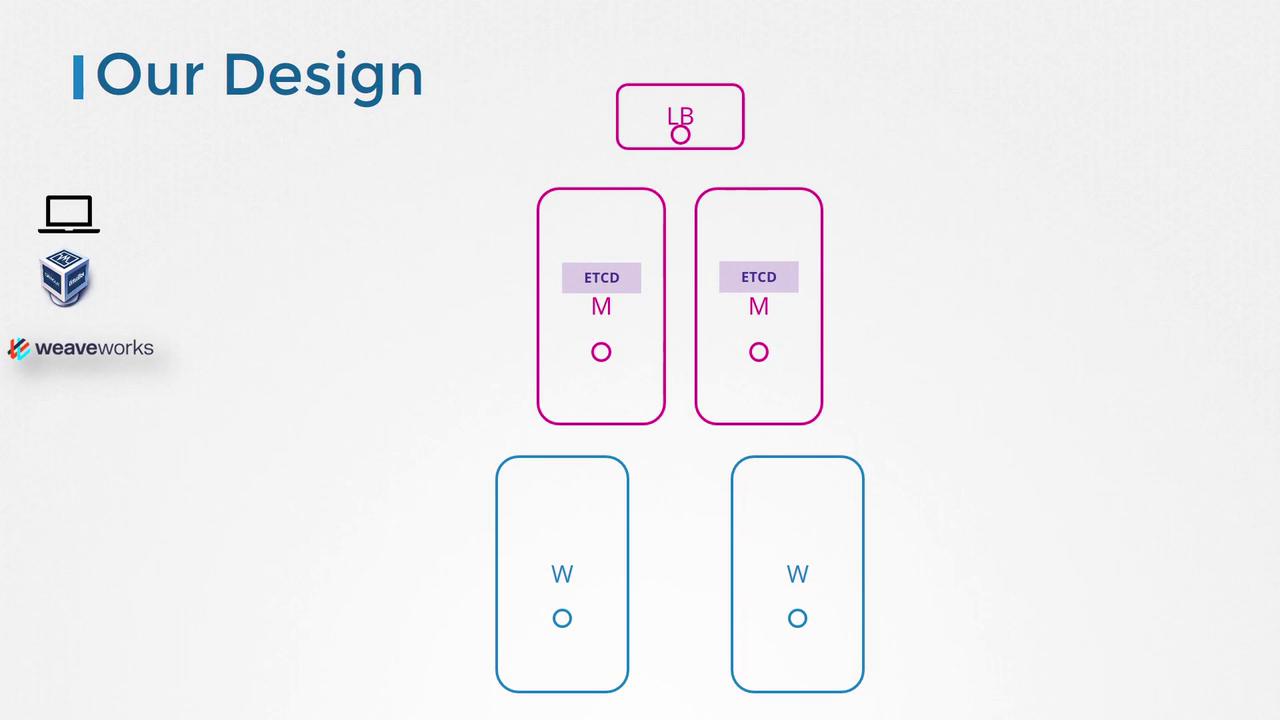
To mitigate this single point of failure, it is essential to deploy multiple master nodes in a high availability configuration. This setup builds redundancy across all critical components—from the master nodes and control plane components to the worker nodes and applications managed by replica sets and services.
High Availability Master Components
In a standard three-node cluster, you start with one master and two worker nodes. The master node hosts the core control plane components, including the API server, controller manager, scheduler, and etcd server. When you add a second master node for high availability, the same components are deployed on the new master.API Server in Active-Active Mode
The Kube API server processes requests and provides cluster information. It runs in an active-active mode; multiple API servers can operate concurrently on different nodes. In a typical configuration, the kubectl utility contacts the master node on port 6443 as specified in the kubeconfig file. However, when multiple master nodes are present, you must avoid sending duplicate requests to all of them. Instead, use a load balancer to distribute traffic evenly among the API servers.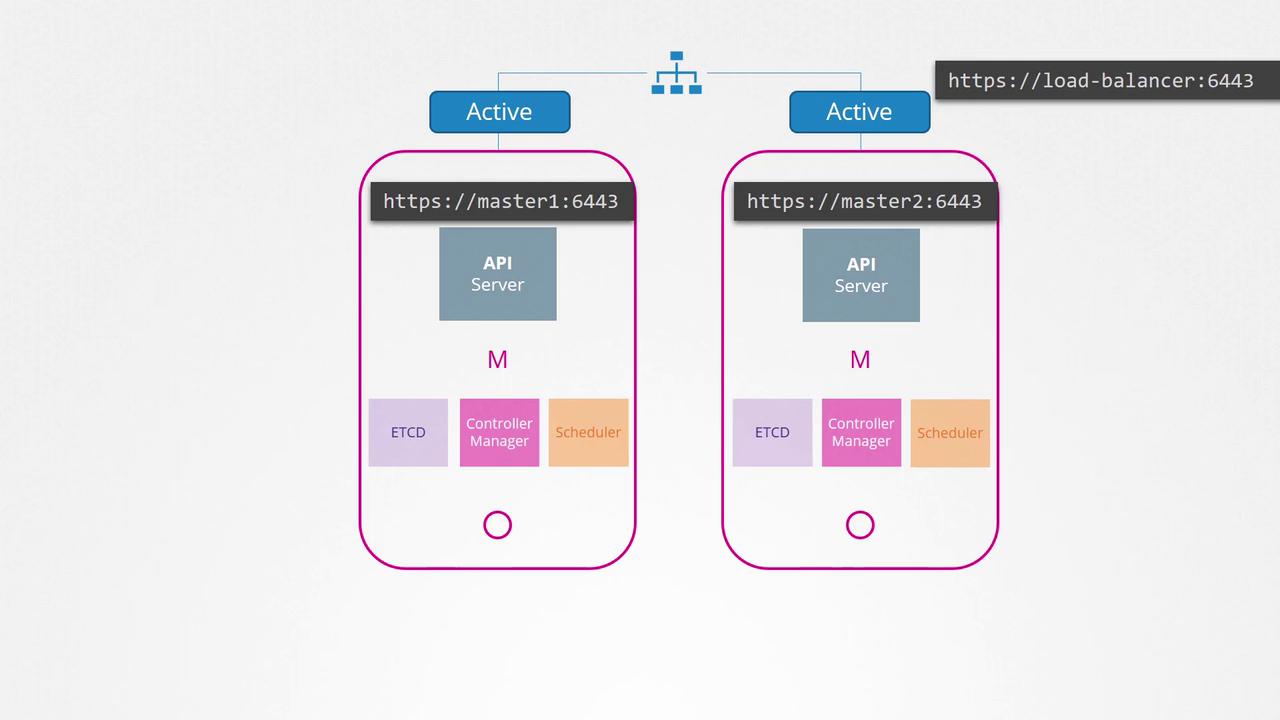
Scheduler and Controller Manager in Active-Standby Mode
Both the scheduler and controller manager continuously monitor the cluster state to perform required actions. Running multiple instances of these components simultaneously could lead to duplicate operations, like launching extra pods. To prevent this, they should run in an active-standby mode. A leader election process ensures that only one instance manages the operations at a time. For instance, the controller manager uses leader election (enabled by default) to secure a lock on a specific Kubernetes endpoint known as the “kube-controller-manager” endpoint. The first instance to update this endpoint becomes active, while the others remain passive. The active process holds the lock for a defined lease duration (default is 15 seconds) and renews it every 10 seconds, while all instances attempt to acquire leadership every 2 seconds. If the active instance fails, a passive instance can quickly take over. Below is an example command to start the controller manager with leader election enabled:etcd Topologies in High Availability
etcd is the Kubernetes component that stores all cluster data. There are two common topologies for its deployment:-
Stacked Control Plane Nodes Topology:
In this model, etcd runs on the same nodes as the Kubernetes control plane. This configuration simplifies deployment and management since it requires fewer nodes. However, a failure on one node results in losing both the etcd member and the corresponding control plane components. -
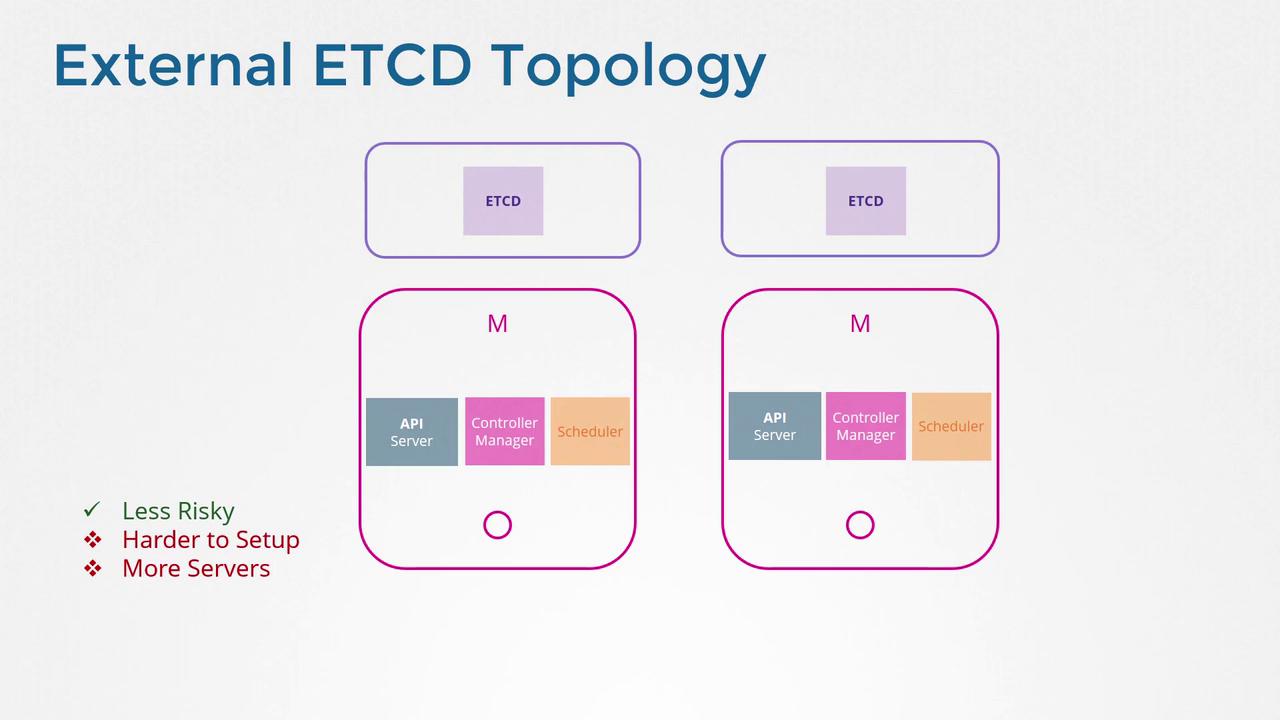
External etcd Servers Topology:
Here, etcd is deployed on separate servers independent of the control plane nodes. This design minimizes risk since a control plane node failure does not directly affect the etcd cluster. The trade-off is that this setup demands twice as many servers compared to the stacked topology.
In upcoming articles, we will delve deeper into how etcd operates within a cluster and outline best practices for determining the optimal number of nodes in your etcd cluster.
Cluster Design Summary
Originally, many clusters were designed with a single master node. With high availability in mind, modern configurations deploy multiple master nodes and incorporate a load balancer for the API servers. This design typically results in a cluster with five nodes: multiple masters, an external load balancer, and worker nodes.