1. Start with the business problem (and validate that ML is appropriate)
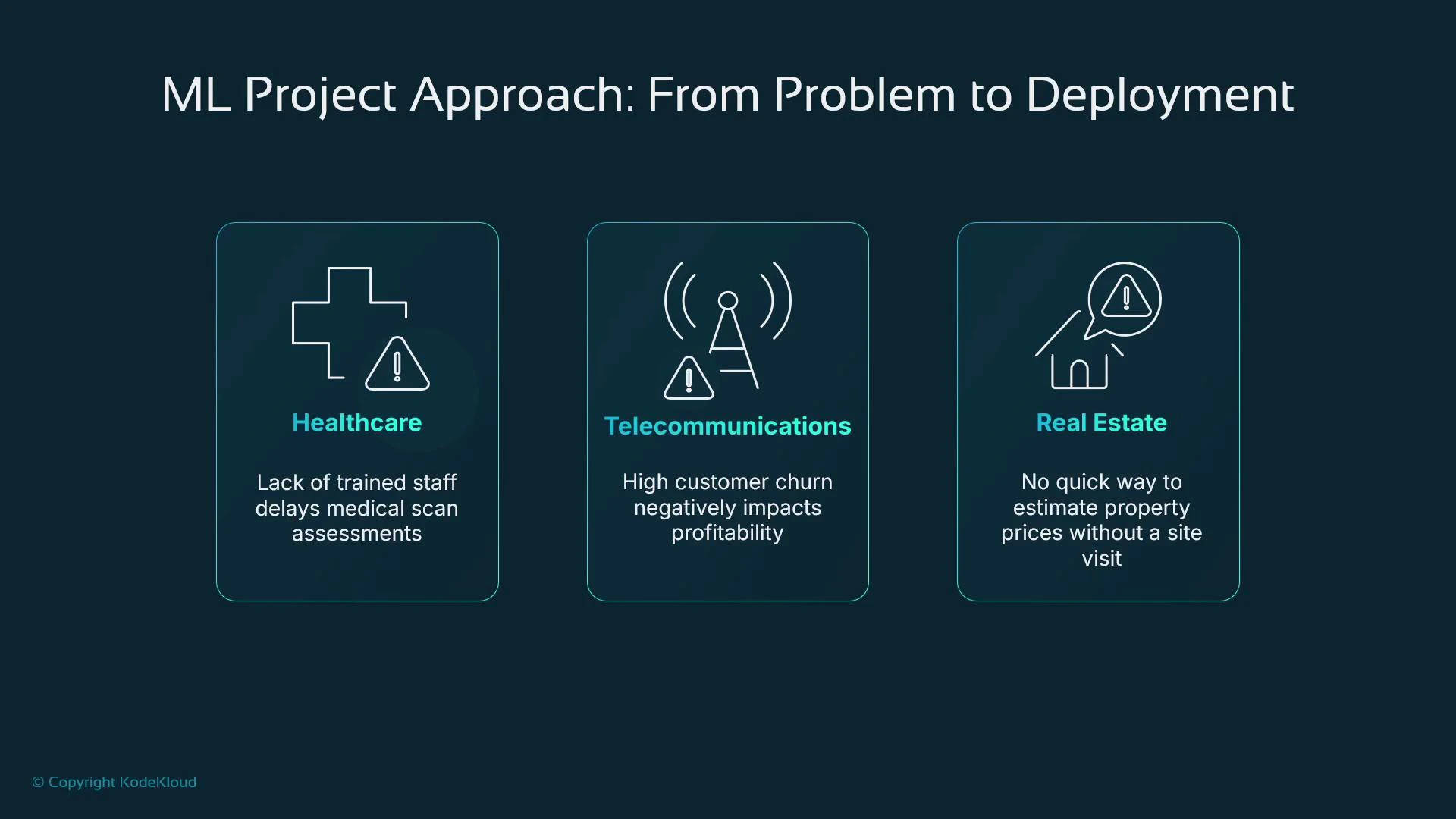
Before any data is collected, define the business question and evaluate whether ML is the right approach. Sometimes deterministic rules or traditional software solve the problem better; in other cases, ML offers cost-effective automation or higher accuracy. Common business domains and ML motivations:- Healthcare — automate medical image review when clinician resources are constrained to reduce diagnostic delays.
- Telecommunications — predict customer churn so you can make targeted retention offers before contracts expire.
- Real estate — estimate property prices quickly from structured features when an on-site valuation is impractical.
2. Frame the ML task
Translate the business requirement into an ML problem type and confirm that the available data can support it. Below is a quick reference mapping of task types to typical algorithms and example outputs.
If the business task is, for example, multi-class medical-scan classification, the problem maps to image classification. Predicting churn is a classification task (often binary). Estimating prices is usually regression.
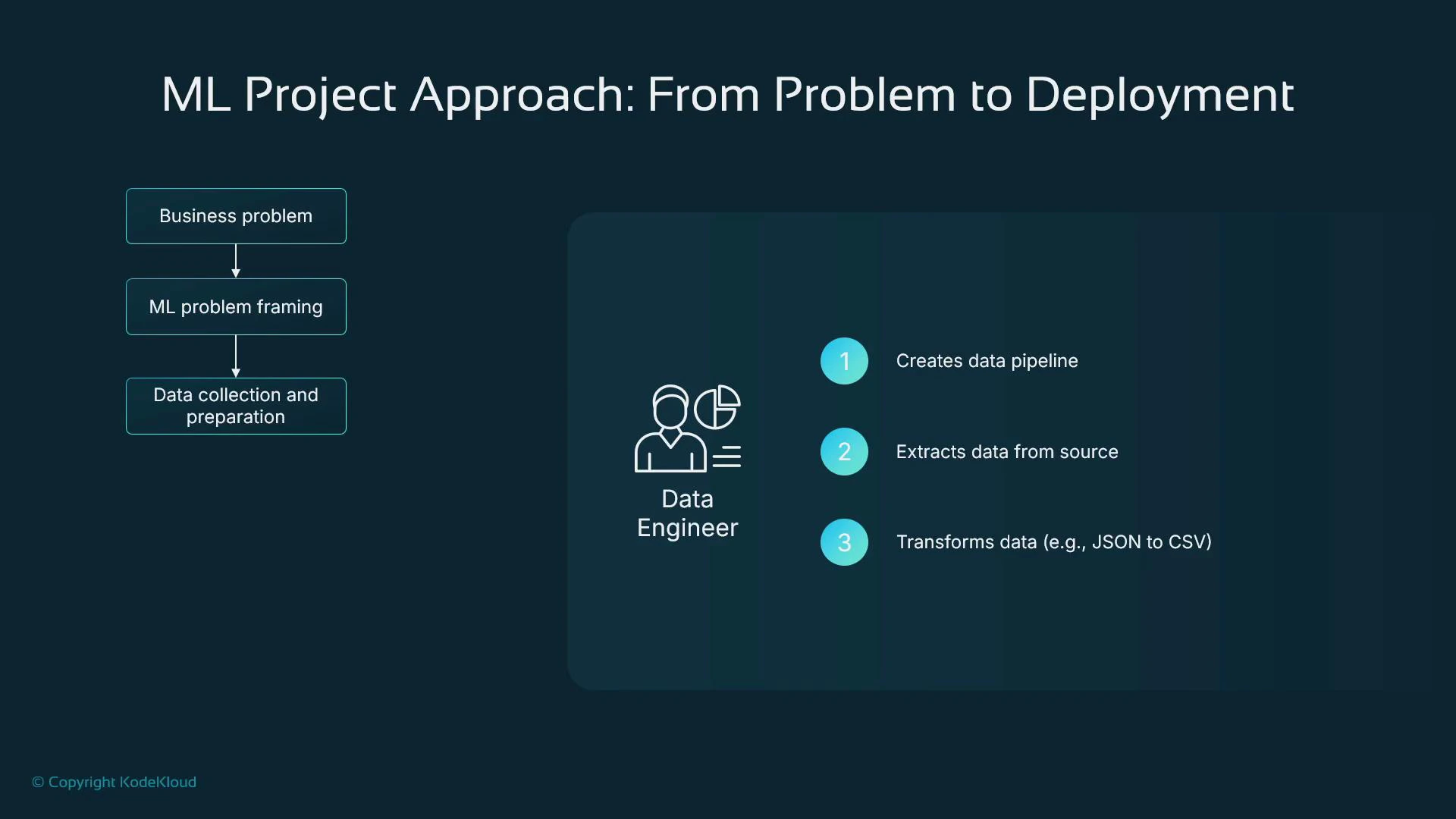
3. Source and prepare data (data engineering)
Data pipelines and reliable data collection are foundational. Roles and responsibilities typically split as:- Data engineers: build ETL/ELT pipelines, extract from databases/logs/object stores, clean and transform source data, and automate scheduled delivery for training/retraining.
- Data scientists: explore data, create features, prototype models.
- ML engineers: productionize pipelines, training jobs, and serving infrastructure.
- Extract data from operational stores, logs, or object storage.
- Normalize/transform formats (e.g., JSON → CSV, Parquet).
- Ensure reproducibility and lineage for training and retraining.
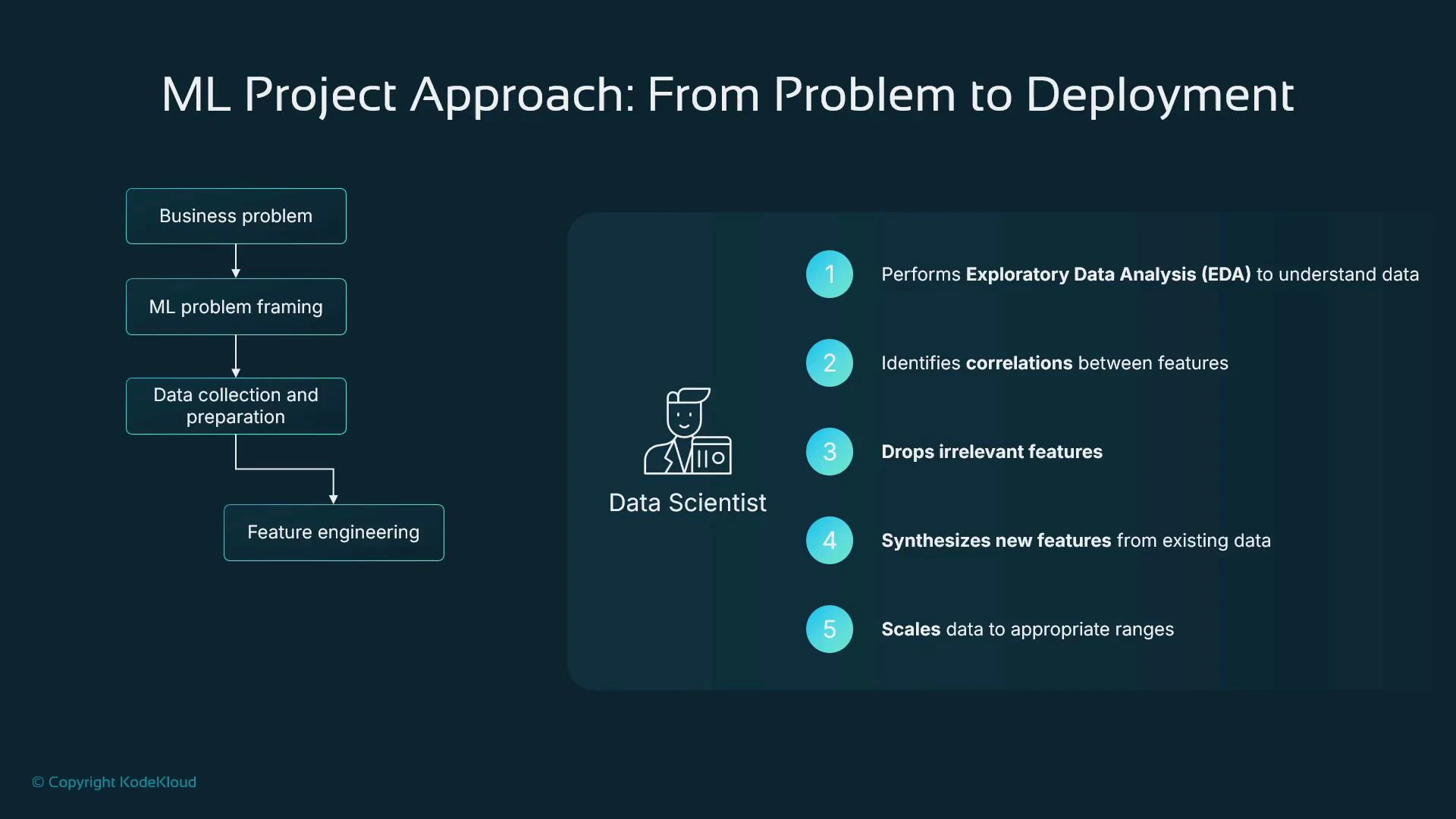
4. Feature engineering and exploratory data analysis (EDA)
Data scientists perform EDA and create features that improve model performance. Typical activities:- Inspect dataset composition, distributions, data types, and missing values.
- Identify correlated or redundant features and reduce dimensionality when appropriate.
- Remove irrelevant or privacy-sensitive columns (PII, account numbers).
- Create derived features (e.g., account_age_days from account_creation_date).
- Scale or normalize numeric features when magnitudes differ widely.
- Encode categorical variables (one-hot, ordinal, learned embeddings).
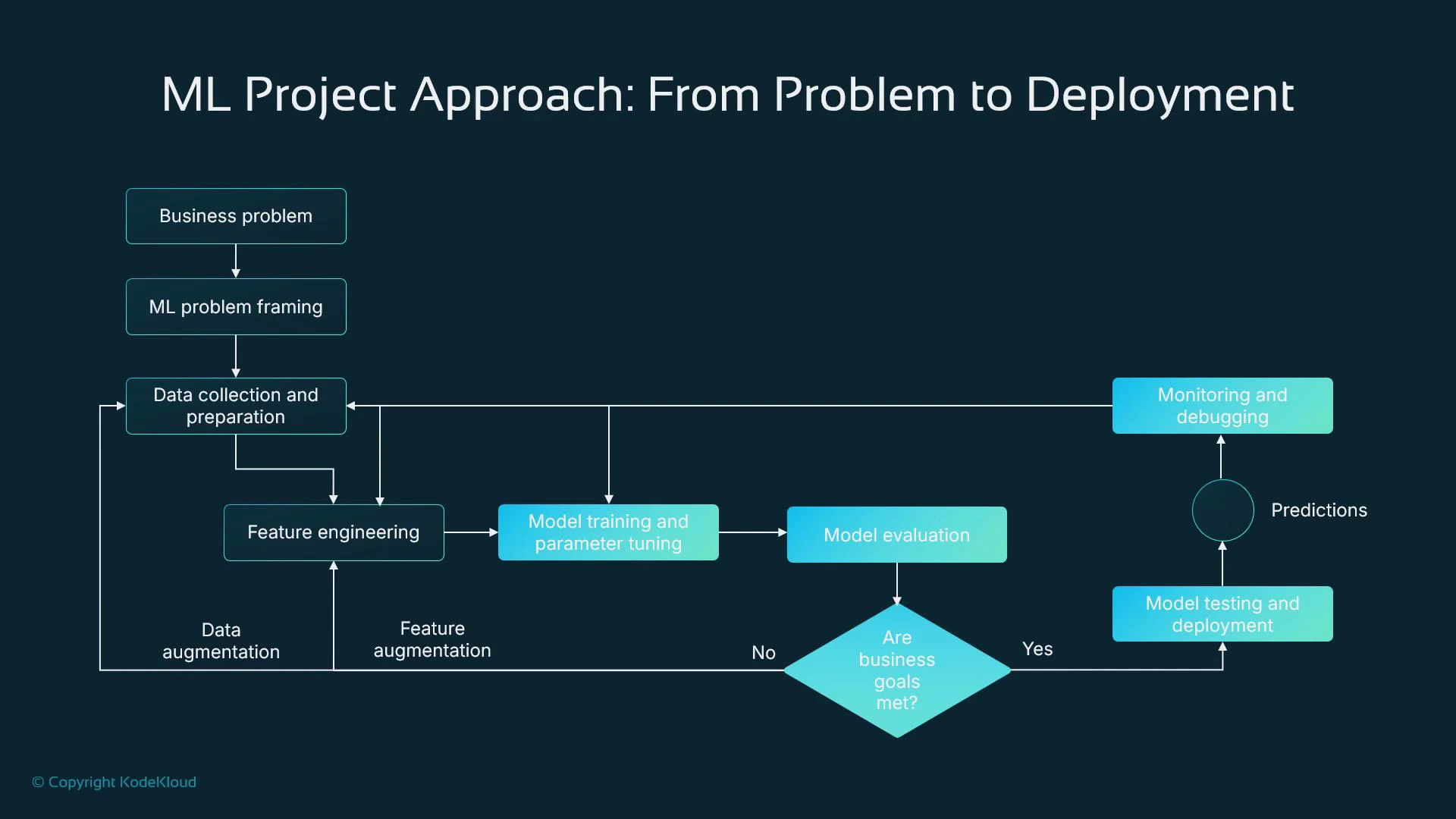
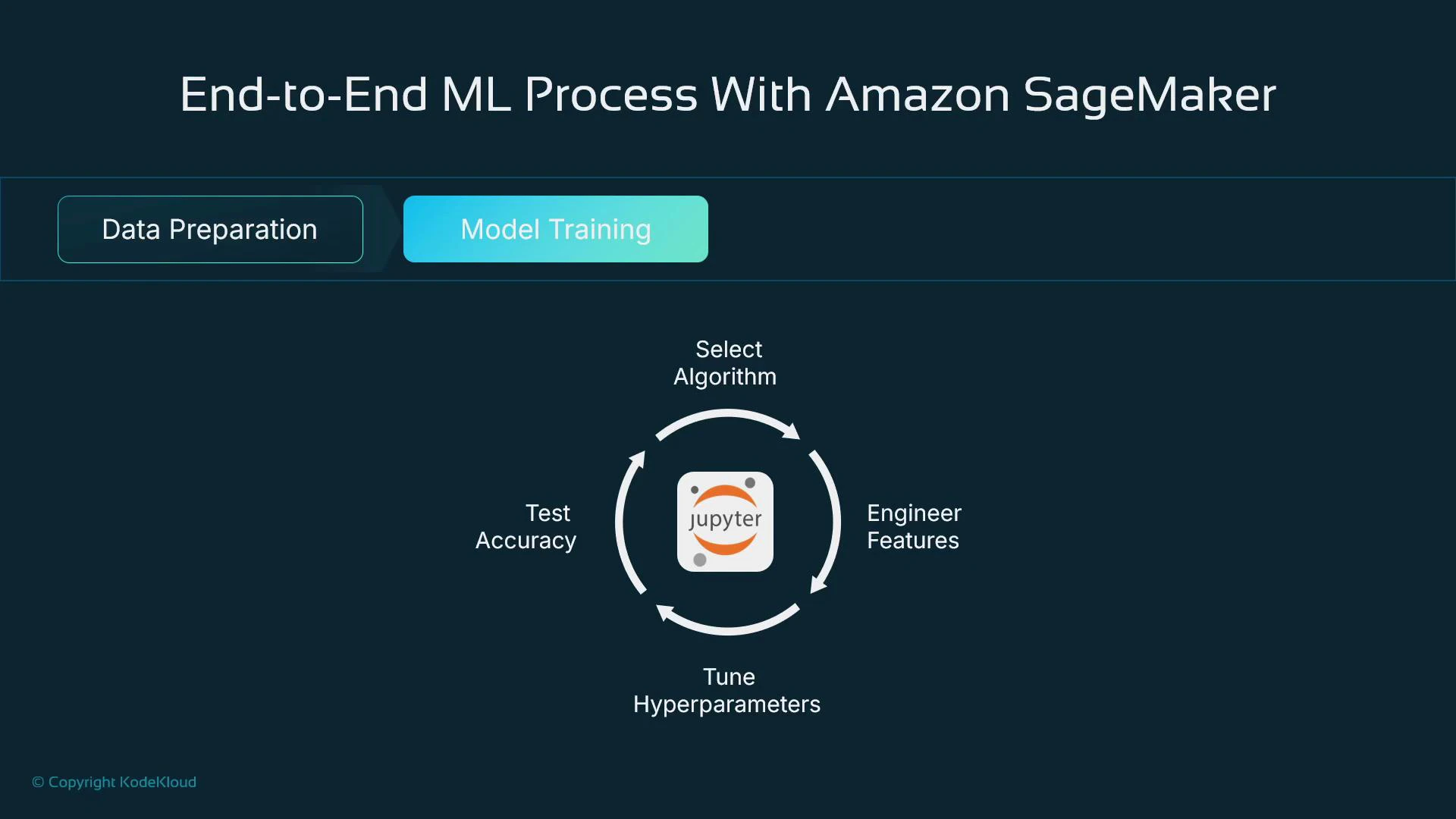
5. Model training: iterate, evaluate, and choose
Model training tunes parameters (e.g., weights and biases) using optimizers like gradient descent. The process is iterative: test algorithms, adjust features and hyperparameters, and evaluate results. Important choices during training:- Algorithm selection (linear models, gradient-boosting, neural nets, etc.).
- Feature set and preprocessing pipeline.
- Hyperparameters (learning rate, epochs, regularization, etc.).
- Split data into training, validation, and test sets (example ratios: 70% train / 20% validation / 10% test).
- Train on the training set, tune on validation, measure final performance on the test set.
- Never leak test data into training or hyperparameter tuning.
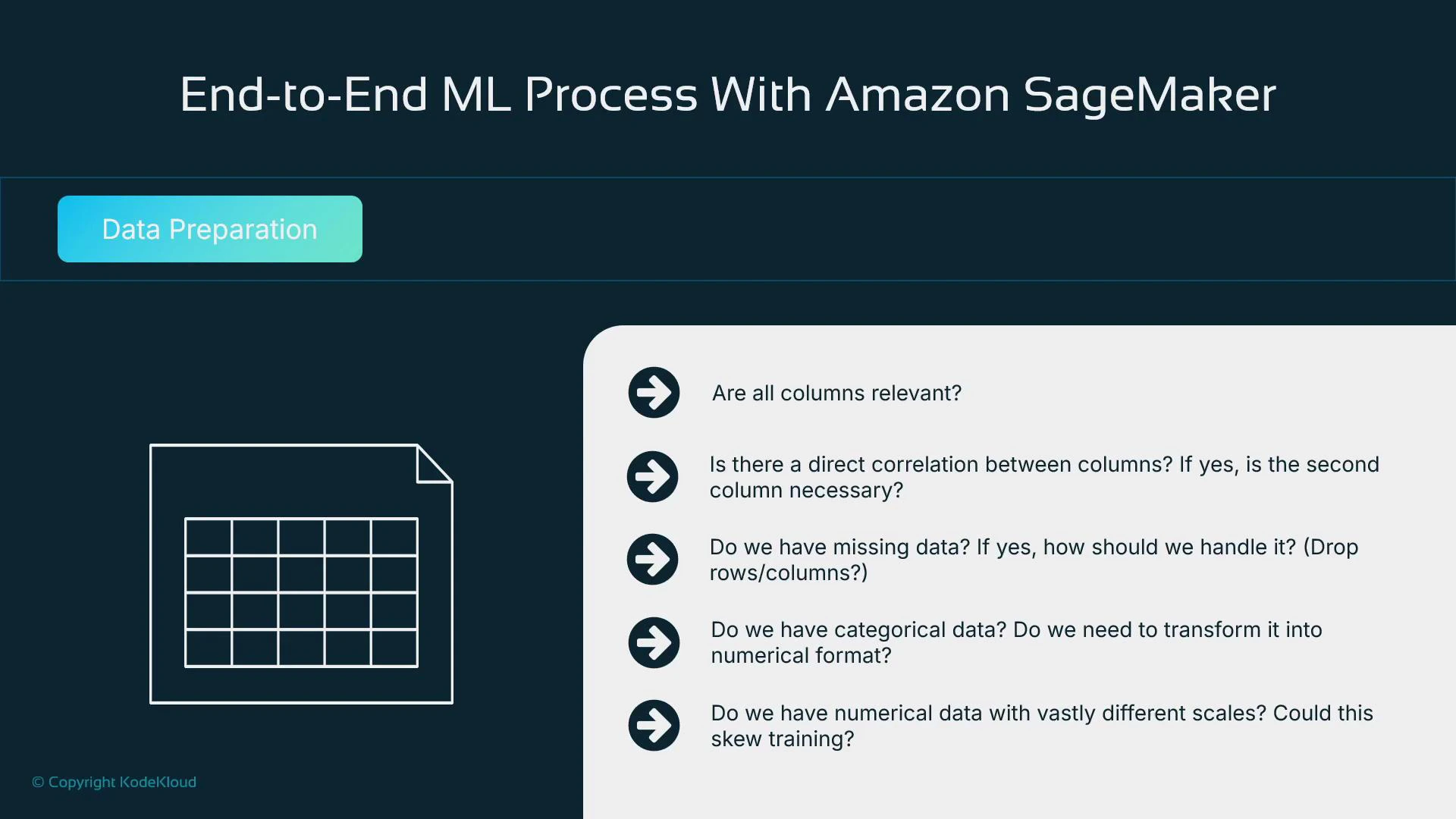
6. Data-preparation checklist (practical questions to answer)
When preparing data, explicitly resolve these questions:- Are all columns relevant or privacy-sensitive? What can be dropped?
- Are features highly correlated or likely to introduce multicollinearity?
- How will you handle missing values (drop, impute, or flag missingness)?
- How will categorical variables be encoded for the chosen algorithms?
- Do numerical features require scaling?
7. Training at scale with Amazon SageMaker
For prototyping, Jupyter notebooks are ideal: they enable EDA, quick experiments, and iterative development. For heavier training workloads, use managed training infrastructure. How SageMaker helps:- Prototype locally or in SageMaker notebooks and then submit managed training jobs that run on scalable CPU/GPU instances.
- Use built-in algorithms (XGBoost, Linear Learner, KNN, etc.) or bring your own training code and frameworks.
- Obtain reproducible training artifacts that can be deployed to hosting endpoints.

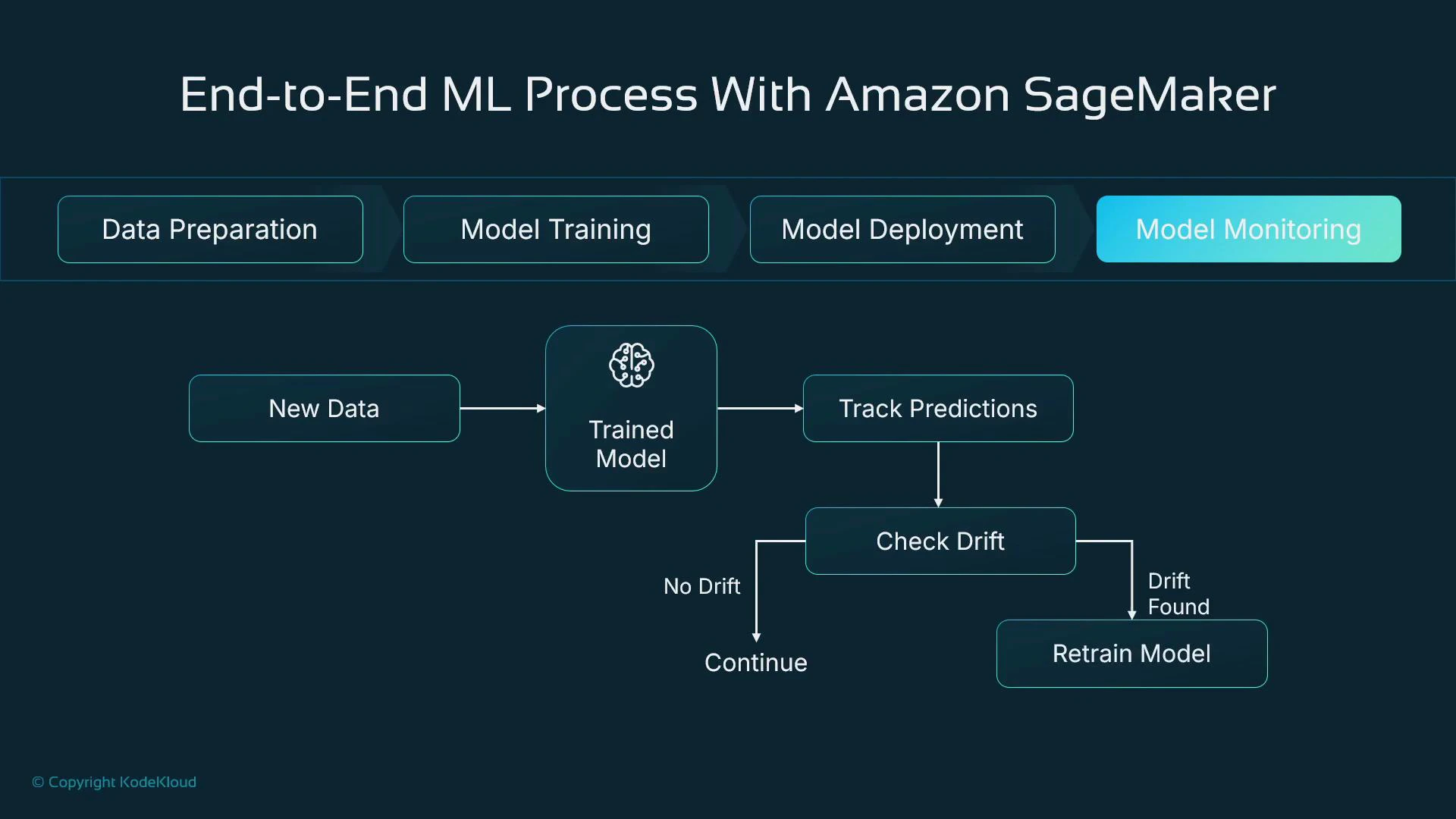
8. Deployment and continuous monitoring
When a model artifact meets your success criteria, host it to serve predictions. SageMaker simplifies hosting by deploying your model and inference code into a managed container running behind an endpoint. Monitoring and lifecycle management:- Log inference inputs and outputs for auditing and root-cause analysis.
- Compare predictions to ground-truth labels as they become available to measure real performance.
- Detect data and concept drift and trigger alerts or automated retraining pipelines.
- Automate retraining when drift or performance degradation crosses defined thresholds.
Always define success criteria with your business stakeholders before deployment (e.g., target accuracy, acceptable error margins, latency/SLA targets). These criteria decide whether a model is production-ready.
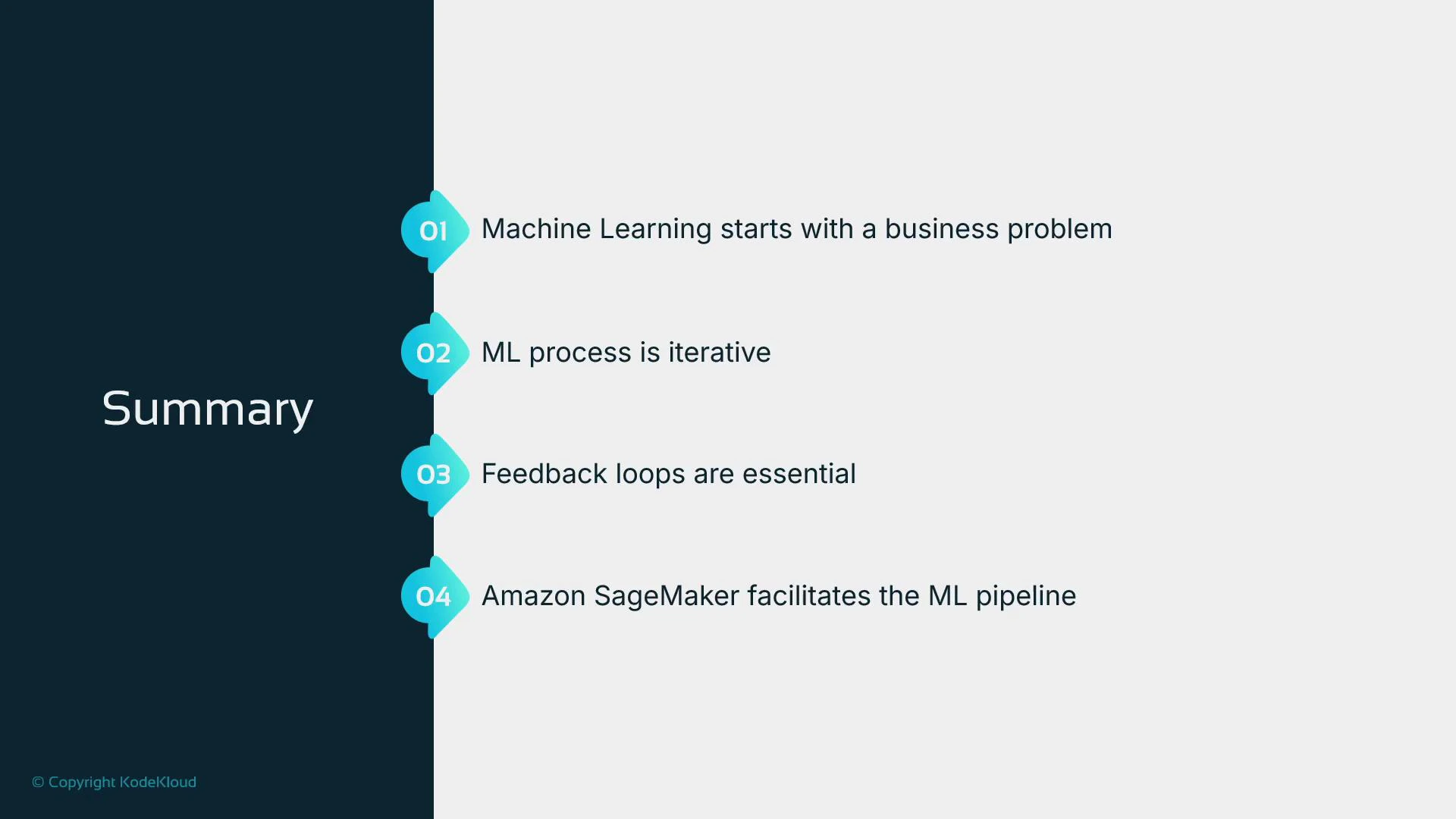
Summary
- Begin with a clear business problem and validate whether ML is the right solution.
- The ML pipeline is iterative: collect and prepare data, engineer features, experiment with models and hyperparameters, and evaluate on held-out data.
- Production models require monitoring and retraining to address drift and maintain performance.
- Amazon SageMaker provides tools across this pipeline: notebooks, scalable training jobs, managed endpoints, and monitoring capabilities.
Links and references
- Amazon SageMaker documentation: https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html
- Machine learning basics: https://developers.google.com/machine-learning/crash-course
- scikit-learn documentation: https://scikit-learn.org/stable/
- XGBoost: https://xgboost.readthedocs.io/
- Practical guide to feature engineering: https://feature-engine.readthedocs.io/