- Data scientist (code-first): Trains models, registers versions programmatically via SDKs/CLI, and links artifacts and container images for inference.
- Governance officer (UI-first): Reviews explainability, bias reports, metadata, and audit trails in SageMaker Studio, then approves or rejects models for production.
Code-based persona (data scientist)
- Typical tools: SageMaker Python SDK, Boto3, CI/CD pipelines.
- Common workflow: create a Model Package Group, register model packages (versions), attach metadata/metrics, and set an initial approval state.
I am using Boto3 here because older codebases (before the SageMaker SDK added native model registry support around 2021–2022) often used Boto3 for model registry operations. If you are starting fresh today, you can use the SageMaker Python SDK which now includes first-class model registry support.
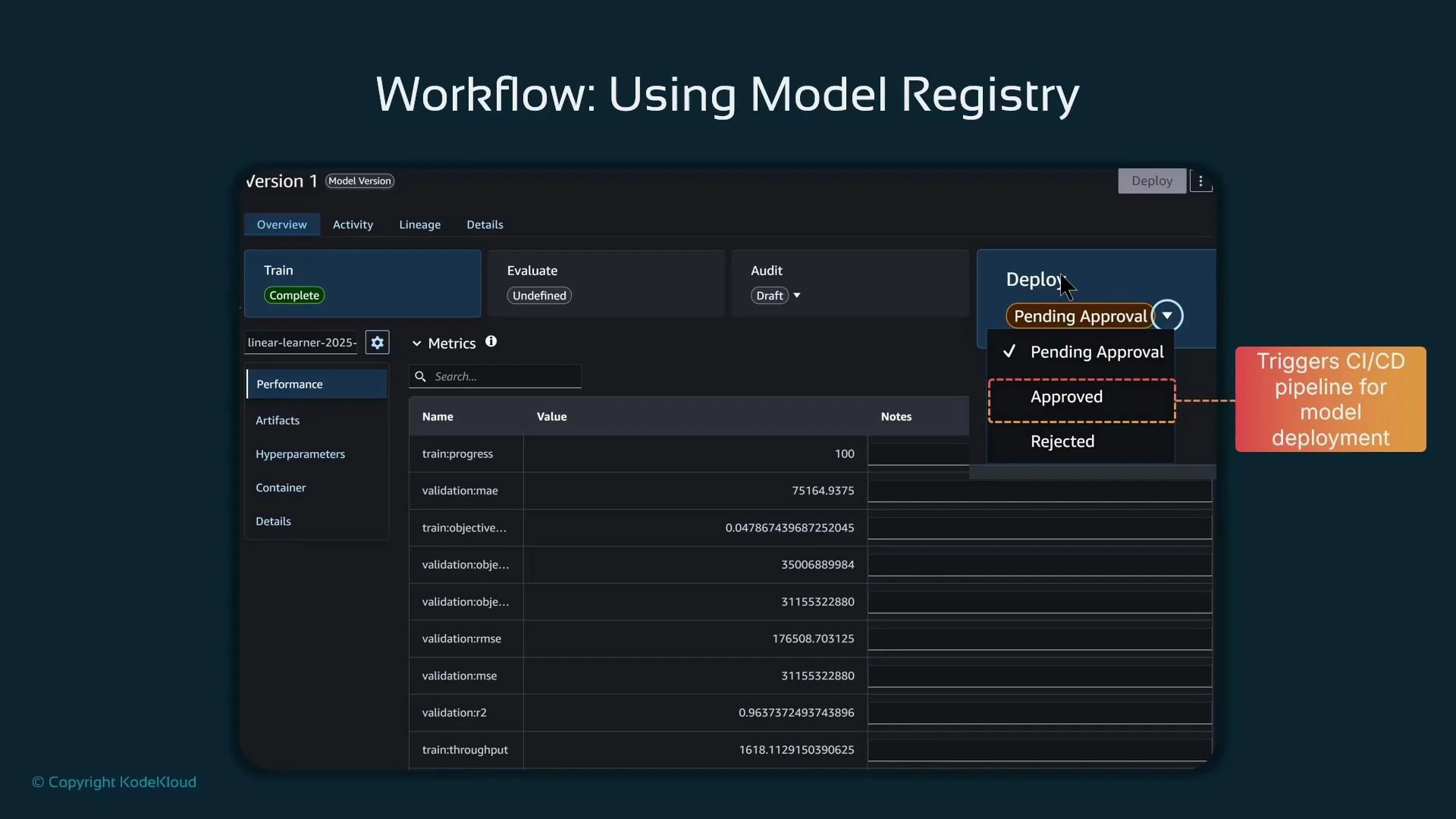
- After creating a model package with ModelApprovalStatus=“PendingManualApproval”, a governance reviewer inspects the model in SageMaker Studio (explainability, bias, metrics, lineage).
- If approved, Studio can change the approval state to “Approved”, which you can wire into CI/CD (for example, a pipeline triggered on approval to deploy the approved model).
- If rejected, the version can be blocked from deployment, or a rollback/alternative version can be selected.
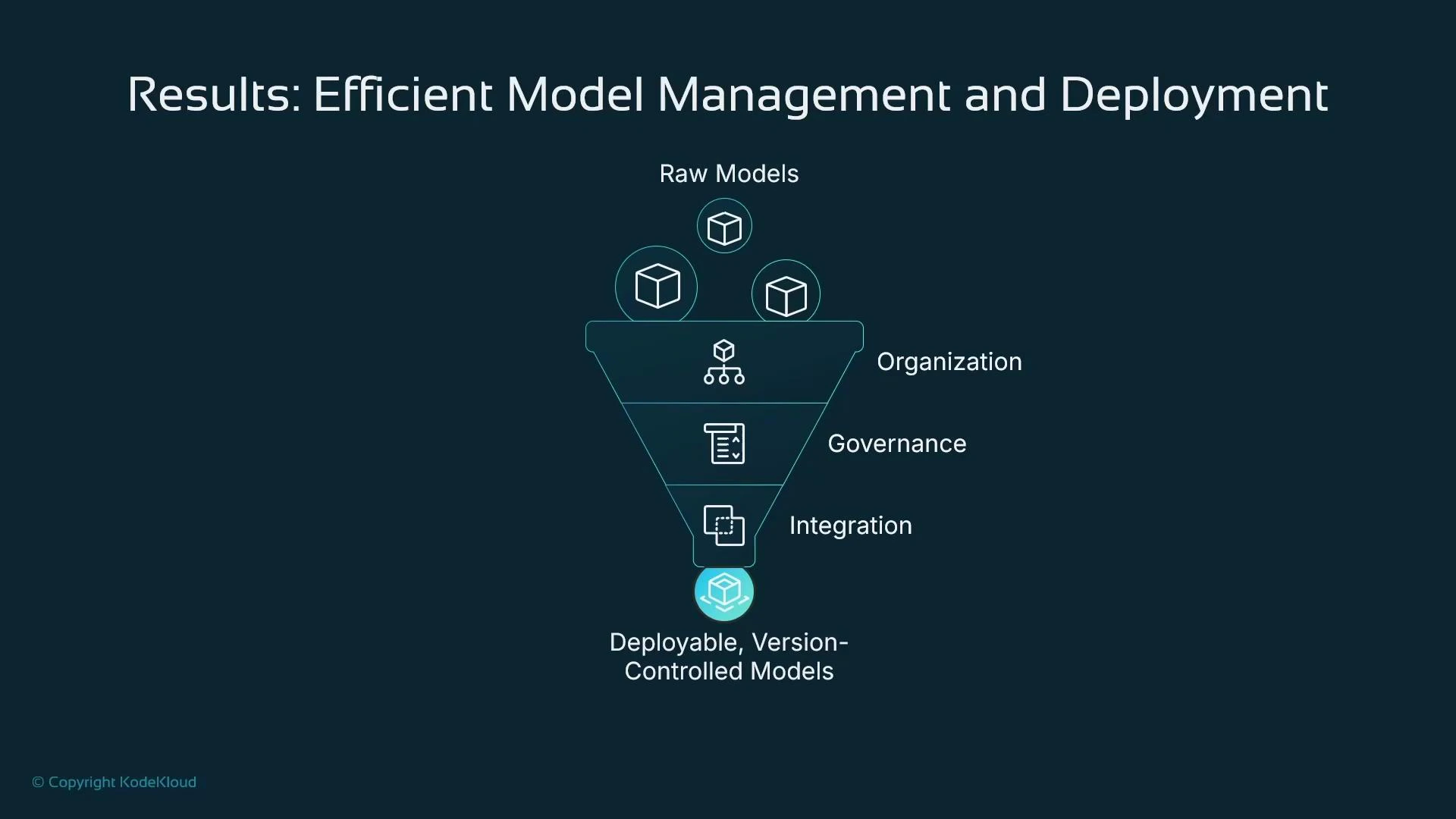
- Organization: Group related models by function, project, or product to reduce clutter.
- Versioning: Keep each model version with its artifacts, metrics, and metadata for traceability.
- Governance: Separate development and review responsibilities; reviewers can validate explainability and bias before approval.
- Integration: Use approval-state events to trigger CI/CD pipelines for automated rollout or controlled deployment.
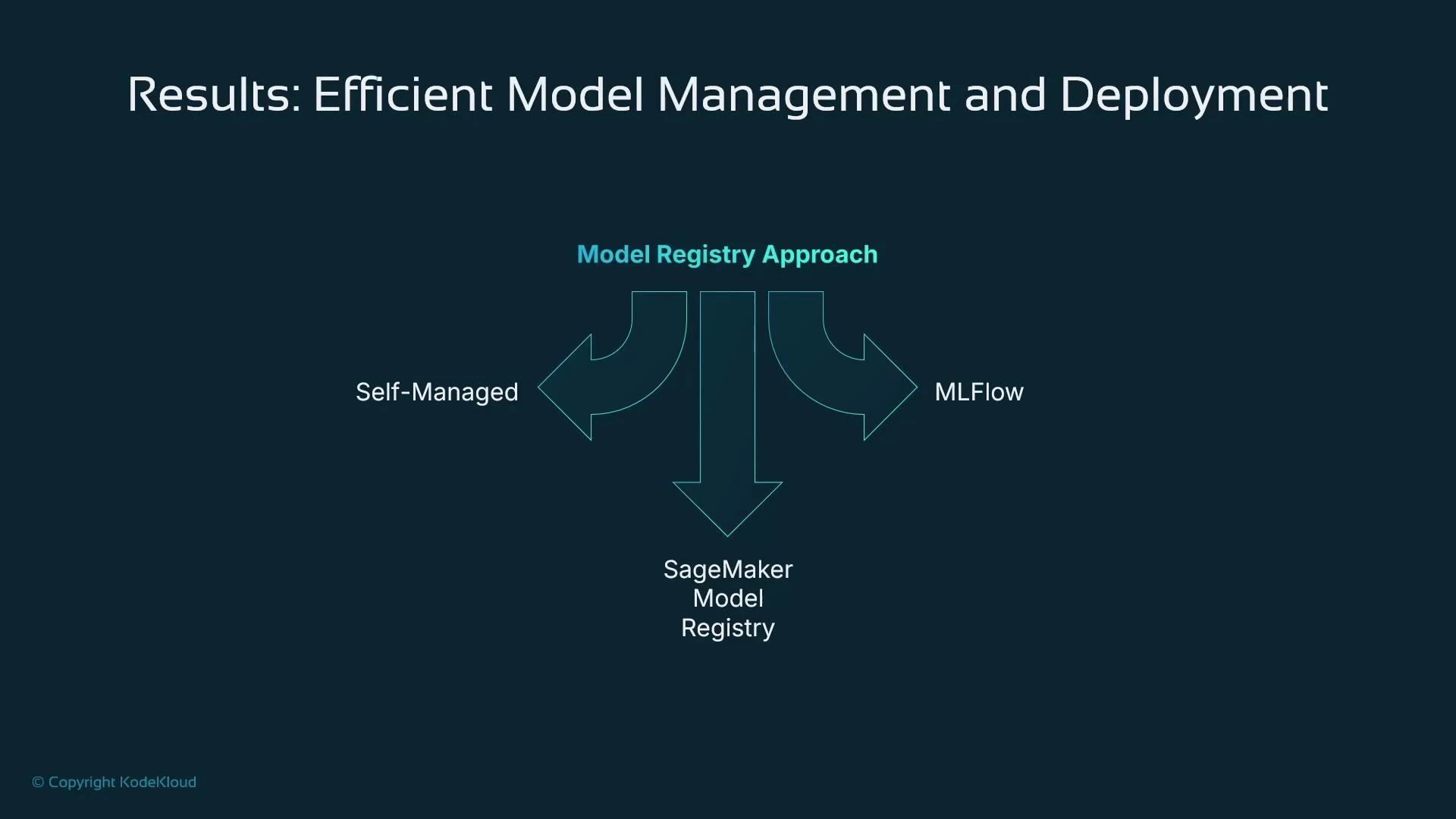
- Self-managed registries: Build a tracking/catalog solution with AWS DynamoDB or a relational database.
- MLflow: Open-source experiment tracking and model registry (mlflow.org).
- SageMaker Model Registry: Built into SageMaker and integrates with AWS IAM, Studio, SDKs, and CI/CD pipelines — ideal for AWS-centric workflows.
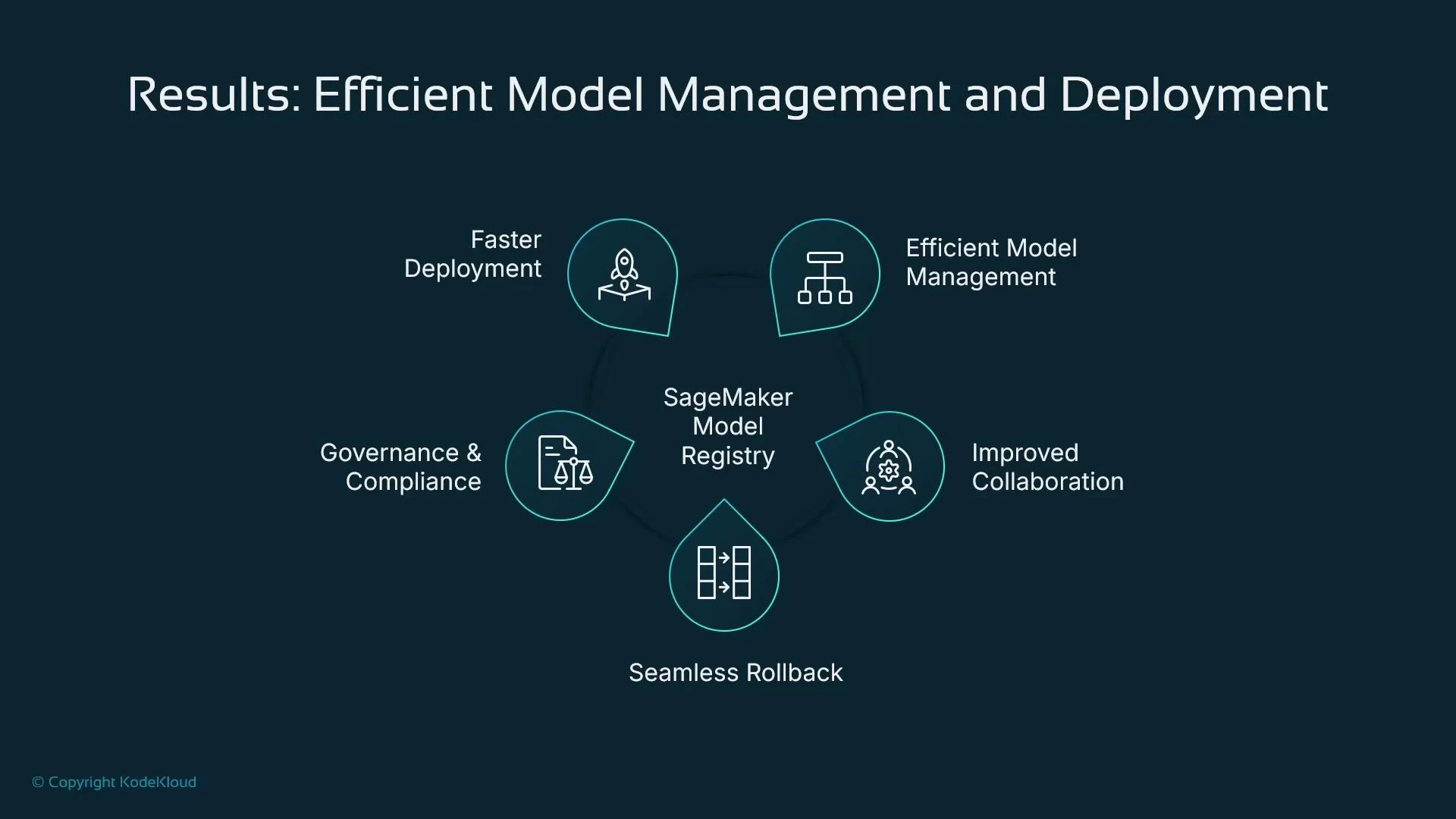
- Faster deployment via approval-triggered pipelines and automation.
- Robust version control and better artifact management.
- Clear collaboration between data scientists and governance teams.
- Seamless rollback or replacement using versioned model packages.
- Improved governance and compliance through audit trails and access controls.
- The distinct roles and interfaces for interacting with a model registry (data scientist vs governance officer).
- How to create a Model Package Group and register a Model Package programmatically.
- How SageMaker Model Registry supports approvals, audit trails, explainability/bias artifacts, and integration with CI/CD.
- Alternatives such as MLflow or custom registries, and reasons to choose the built-in SageMaker Model Registry if you operate primarily in AWS.
- SageMaker Model Registry documentation
- SageMaker Python SDK
- Boto3 SageMaker client
- MLflow project and model registry
- AWS DynamoDB overview