- Batch inference with SageMaker Batch Transform
- How Batch Transform distributes work and uses transient compute
- Mini-batching behavior inside instances
- When to choose batch vs. real-time inference

SageMaker Batch Transform (offline / periodic inference)
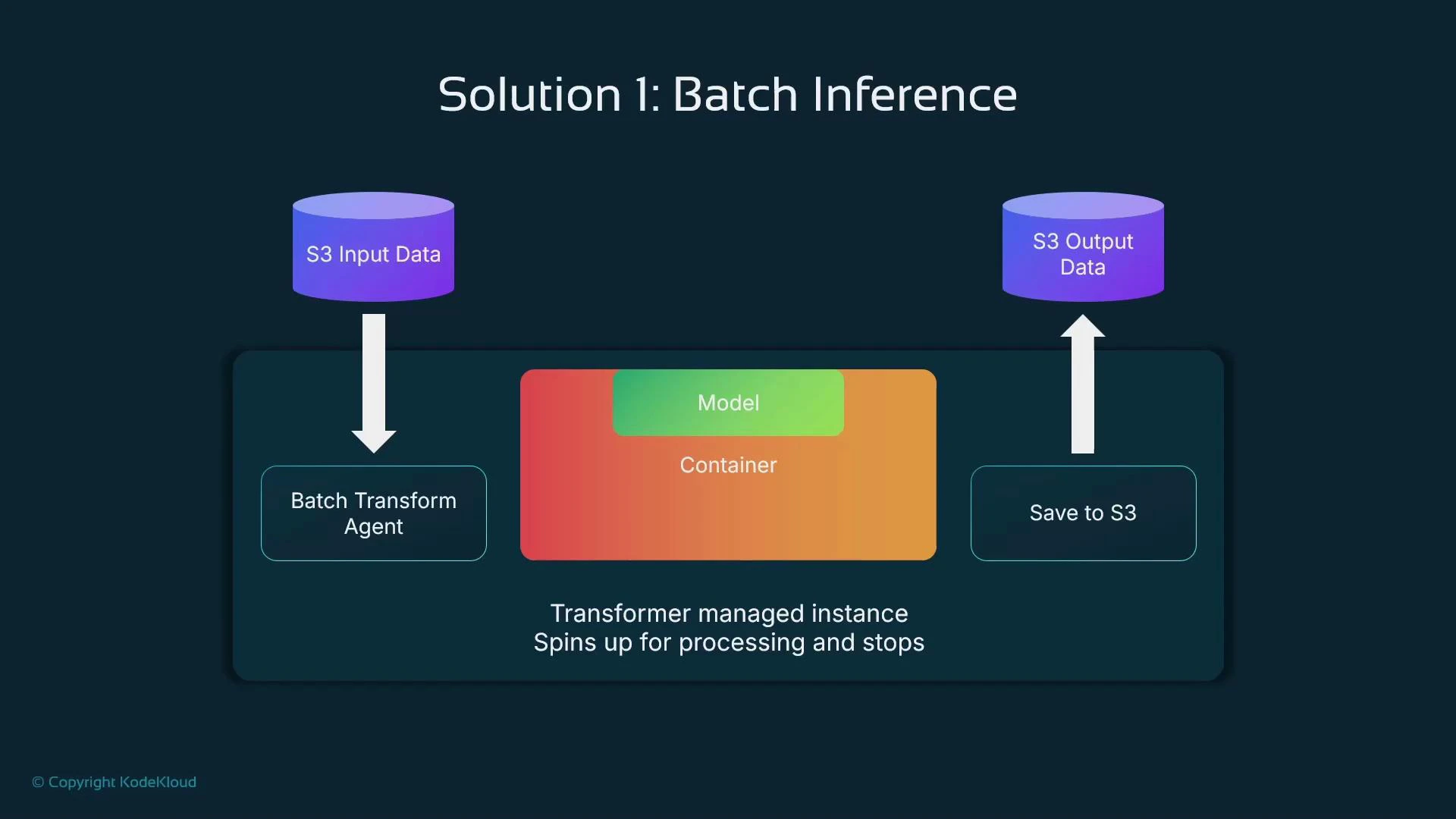
SageMaker Batch Transform is a managed service for non-real-time inference. Provide input files in Amazon S3 and a pre-registered SageMaker model; Batch Transform launches managed compute instances, runs inference on the input, writes outputs back to S3, and then shuts down those instances. This avoids the cost of a continuously running endpoint by using transient compute only when needed.
Key benefits:
- Cost-effective for periodic or bulk prediction jobs
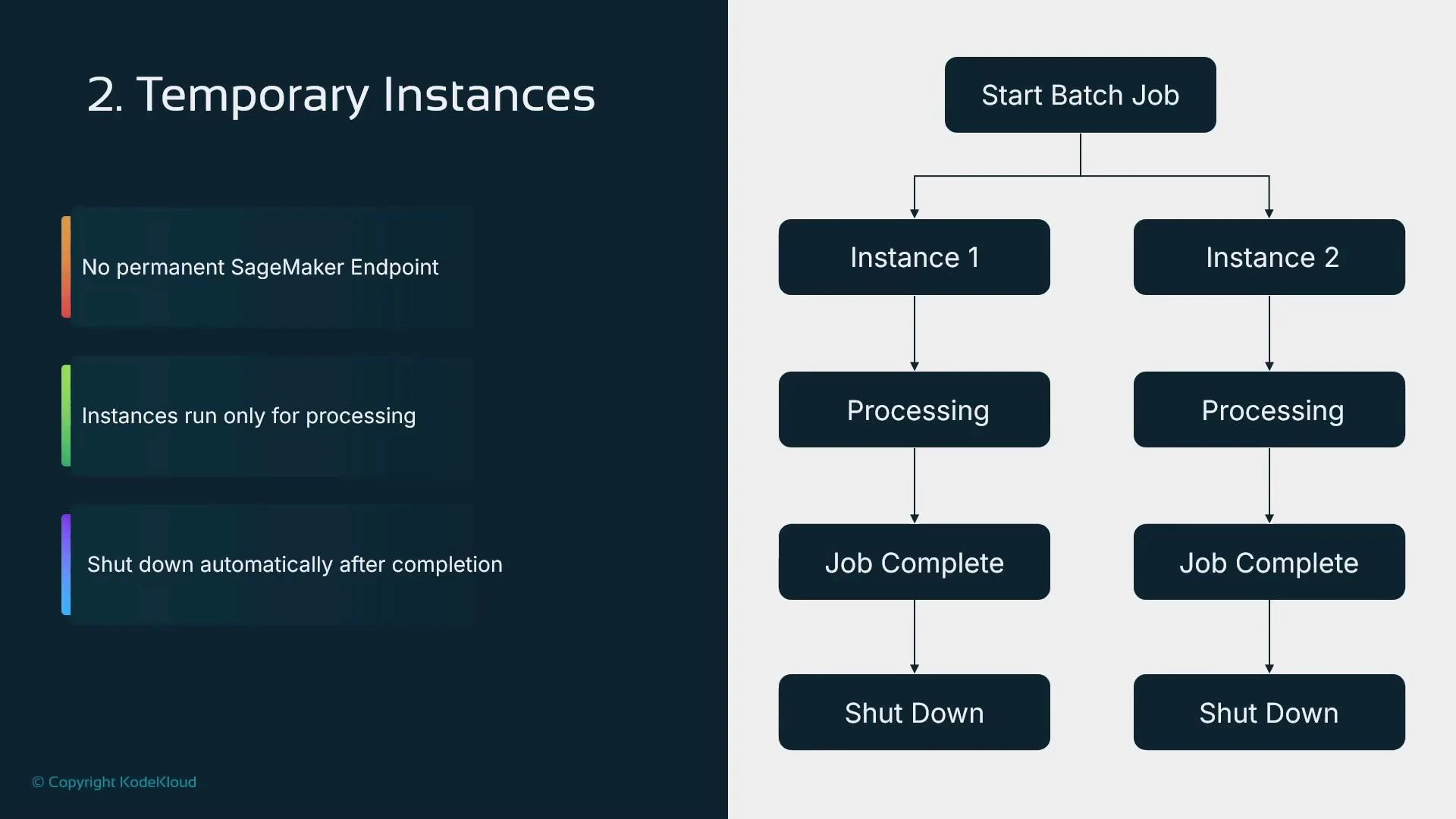
- Managed lifecycle: instances spin up to run the job and terminate after completion
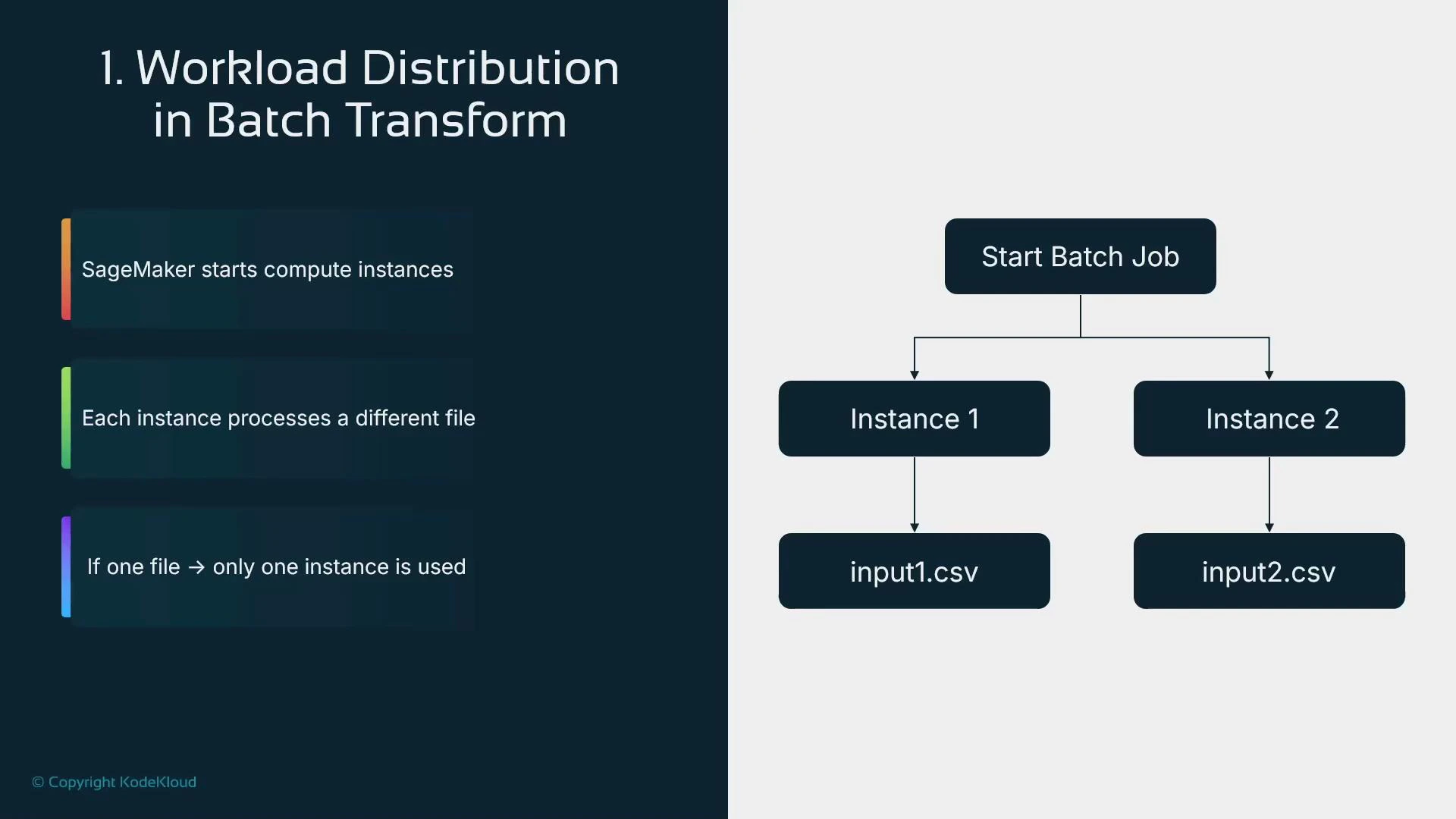
- Supports parallelism across instances when you provide multiple input files
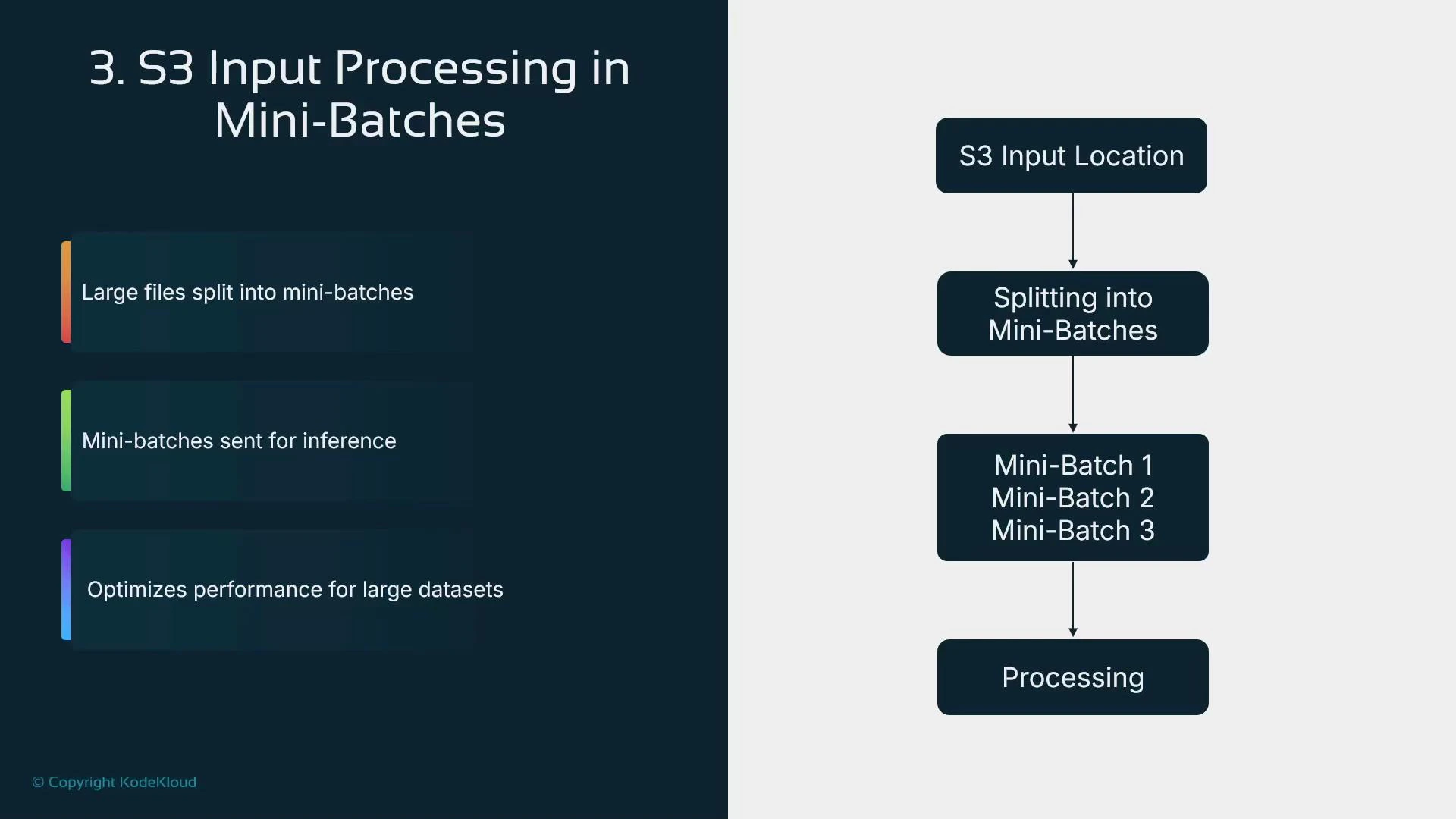
- Mini-batching within an instance improves throughput for models that accept batched input
Replace placeholders like model_name and S3 paths with your own values. Ensure the model container supports the specified content_type / accept values and can process batched input if you enable mini-batching. See the SageMaker Batch Transform docs for available parameters.
(Reference: https://docs.aws.amazon.com/sagemaker/latest/dg/batch-transform.html)
(Reference: https://docs.aws.amazon.com/sagemaker/latest/dg/batch-transform.html)
- The Transformer object configures the job; calling transform() actually starts it.
- SageMaker launches the specified instance_count of identical instances, distributes input files across them, and terminates instances after processing.
- Use transformer.wait() to block until the job completes and results are written to S3.
- Provide multiple input files in your S3 prefix, or
- Pre-split large files into smaller chunks that can be distributed across instances.
- Use Batch Transform for periodic, offline, and high-throughput inference jobs to reduce cost and simplify operations.
- Ensure your model container supports the expected content_type and batched inputs (or adapt the container).
- For parallelism, provide many input files or pre-split large files—Batch Transform maps files to instances.
- Monitor job logs and output artifacts in S3 to validate results and troubleshoot issues.
- For workflows that need pre- or post-processing steps, consider SageMaker Inference Pipelines (covered in other lessons) or preprocess inputs before invoking Batch Transform.
Batch Transform is ideal when predictions can be performed offline or in scheduled batches. It reduces cost by avoiding always-on endpoints and supports parallel processing and mini-batching for efficiency. Always confirm that your model container and input formats are compatible with batched requests before enabling mini-batching.
- SageMaker Batch Transform documentation: https://docs.aws.amazon.com/sagemaker/latest/dg/batch-transform.html
- SageMaker inference overview: https://docs.aws.amazon.com/sagemaker/latest/dg/inference.html
- SageMaker Python SDK: https://sagemaker.readthedocs.io/