- Why automation matters for ML workflows
- How SageMaker Pipelines fits into an enterprise deployment lifecycle
- Options for running notebook code inside pipelines (notebooks vs. scripts)
- A concise SDK example showing how to build and run a pipeline
Why automate ML workflows?
Manual notebook-driven experimentation (running cells by hand) is error-prone and difficult to reproduce. Automation provides:- Reproducibility and lineage: with the same inputs (data version, algorithm version, scripts) you should reproduce the same model artifact.
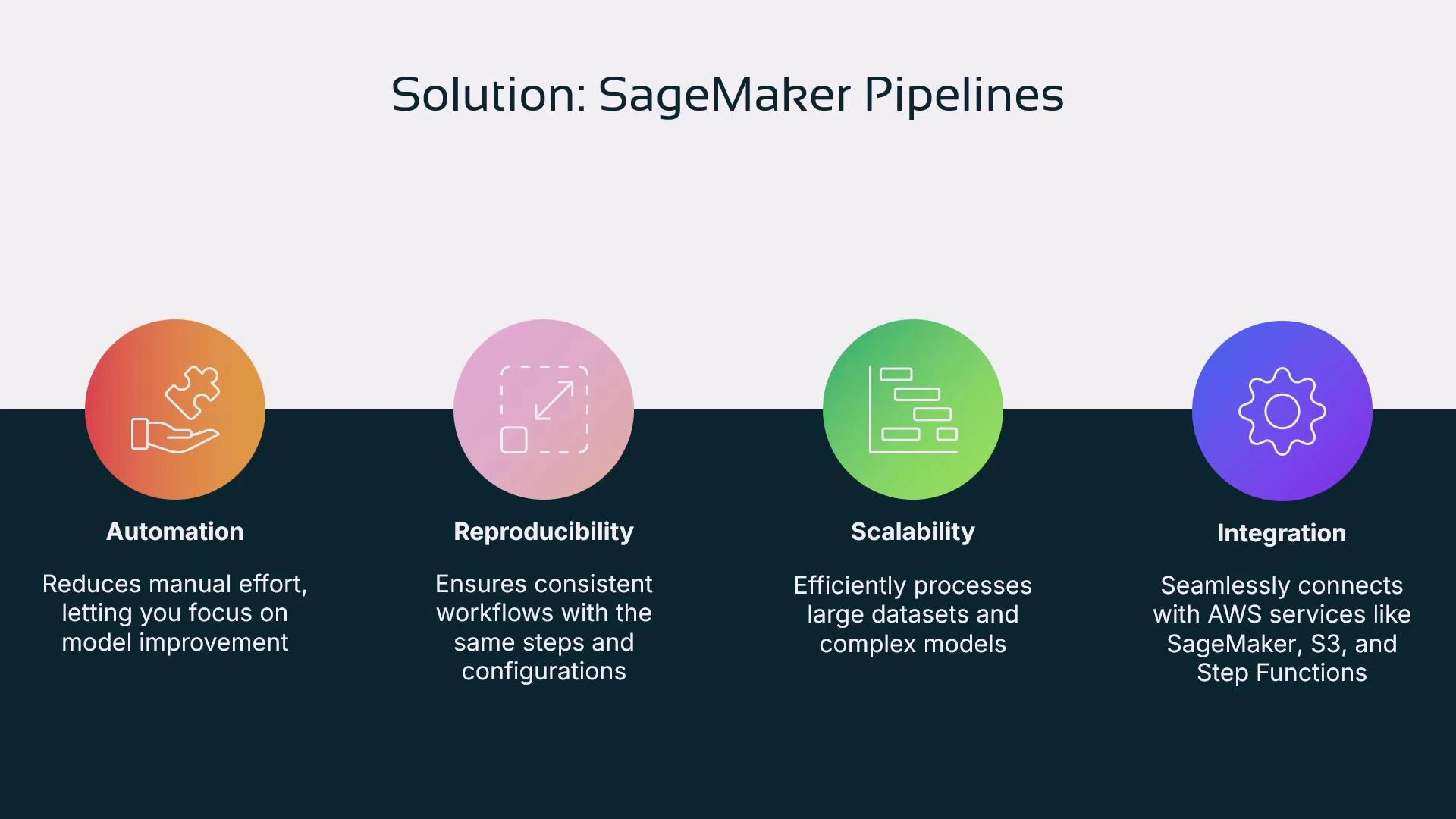
- Scalability: automation enables large-scale experiments and workloads.
- Integration: pipelines connect natively with AWS services like S3, Lambda, Step Functions, and the SageMaker Model Registry.

- Choose a dataset (versioned)
- Pick an algorithm and its version
- Run data processing (scaling, encoding, imputation)
- Run a training job (possibly hyperparameter tuning)
- Store and register model artifacts
- Repeat when code, data, or algorithm versions change
Solution: SageMaker Pipelines
SageMaker Pipelines lets you declare a sequence of steps and run them deterministically:- Define processing, training, evaluation, registration, and (optionally) deployment steps.
- Provide inputs such as dataset S3 paths, script locations, algorithm versions, and hyperparameters.
- Execute the pipeline programmatically or via orchestration systems (CI/CD, Step Functions, Airflow).
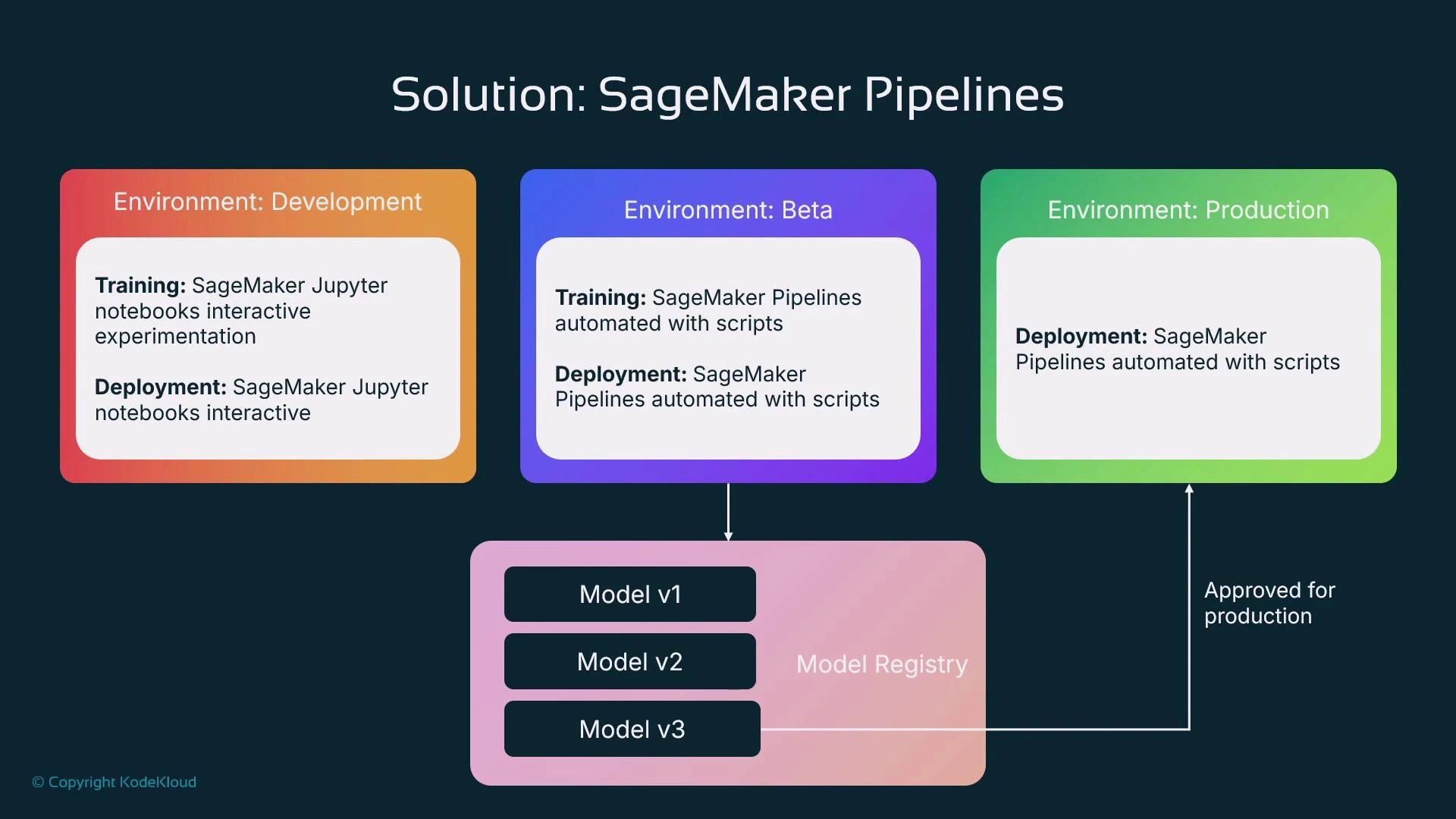
How pipelines fit into an enterprise lifecycle
- Development: data scientists iterate interactively in notebooks (exploration, prototyping).
- Beta / Pre-production: start productionizing by replacing manual steps with automated pipelines for retraining, evaluation, and model registration in staging.
- Production: approved model versions in the Model Registry are promoted and deployed automatically. The registry approval can trigger a deployment pipeline.
Why use scripts (not notebooks) as pipeline steps?
Each pipeline step usually maps to a standalone Python script, not an interactive notebook. Scripts are preferred because:- Deterministic execution (no interactive prompts)
- Easier to add error handling, logging, and retries
- More robust for automation and production debugging
- Better suited for CI/CD and version control
Refactoring notebook code into well-defined Python scripts improves maintainability. Use an IDE like SageMaker Studio Code Editor or VS Code for development and debugging before integrating into pipelines.

- Run notebooks via processing jobs with papermill (an orchestration workaround that still carries notebook limitations).
- Newer native support: SageMaker Pipelines can run Jupyter notebooks as steps in some regions — convenient but not always available and notebook code commonly lacks production-grade error handling.


Notebooks can be executed by pipelines in some regions, but they often lack structured error handling and are less portable. For production pipelines, prefer dedicated scripts stored in a Git repository.
Recommended script-to-step mapping
Store scripts in a Git repo and invoke them from pipeline steps. Example mapping: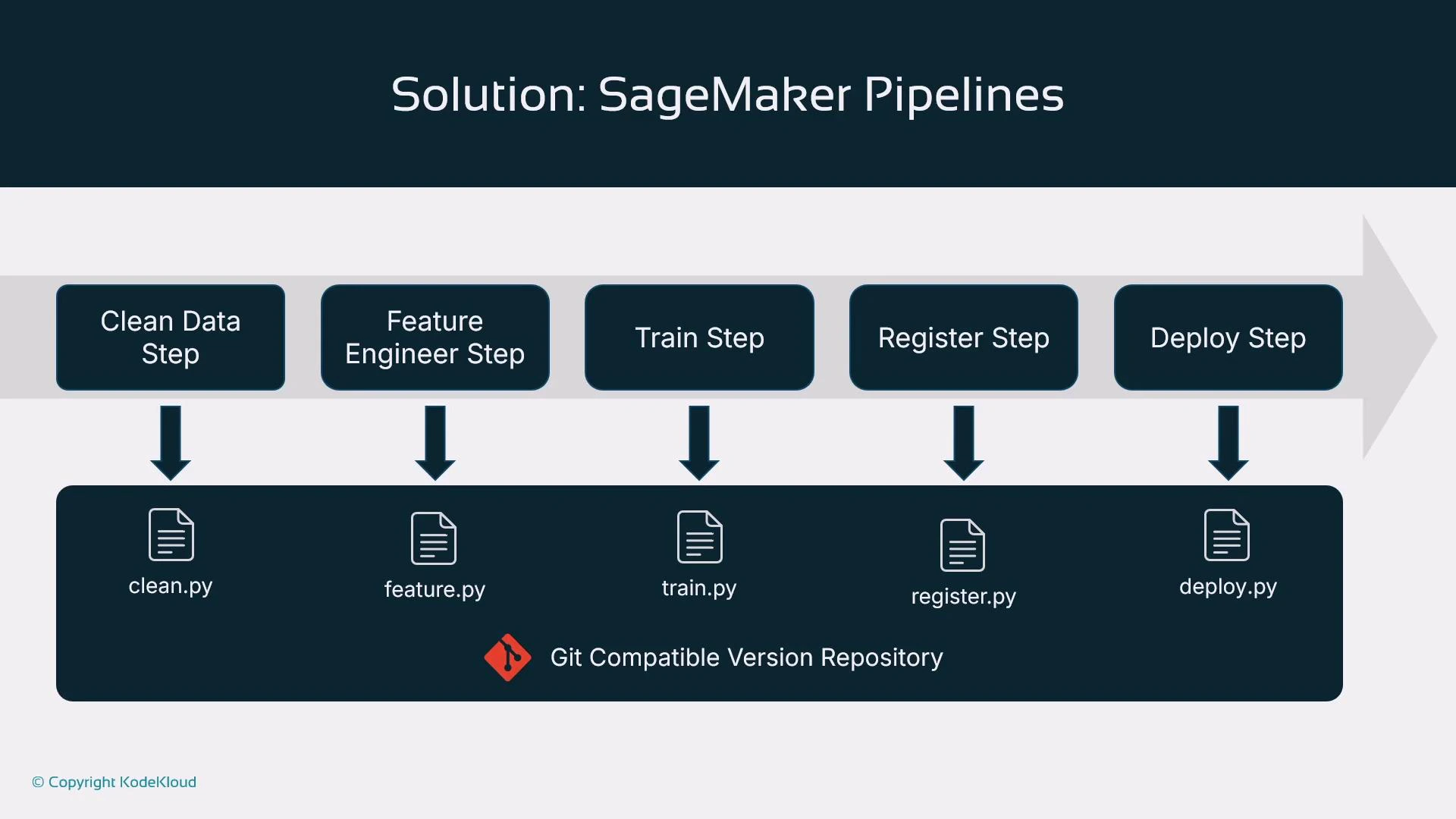
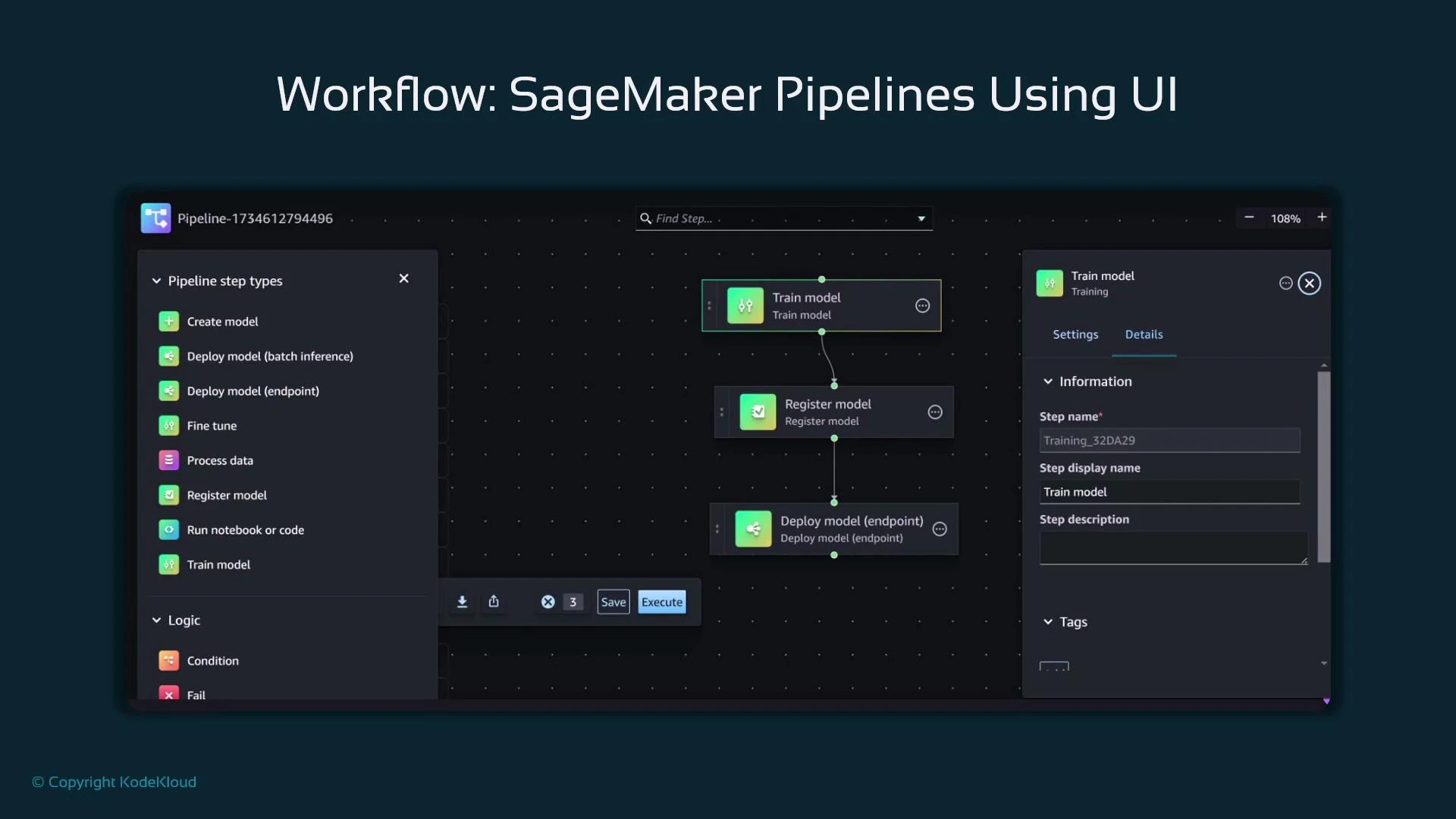
Creating pipelines: Visual Editor vs. SDK
- Studio Visual Editor: drag-and-drop, low-code, quick visualization. Good for simple pipelines but limited customization and binding arbitrary scripts to arbitrary step types.
- SageMaker Python SDK (recommended): define ProcessingStep, TrainingStep, RegisterModel, etc., in code. This gives full control, versioning in code, parameterization, and reuse.
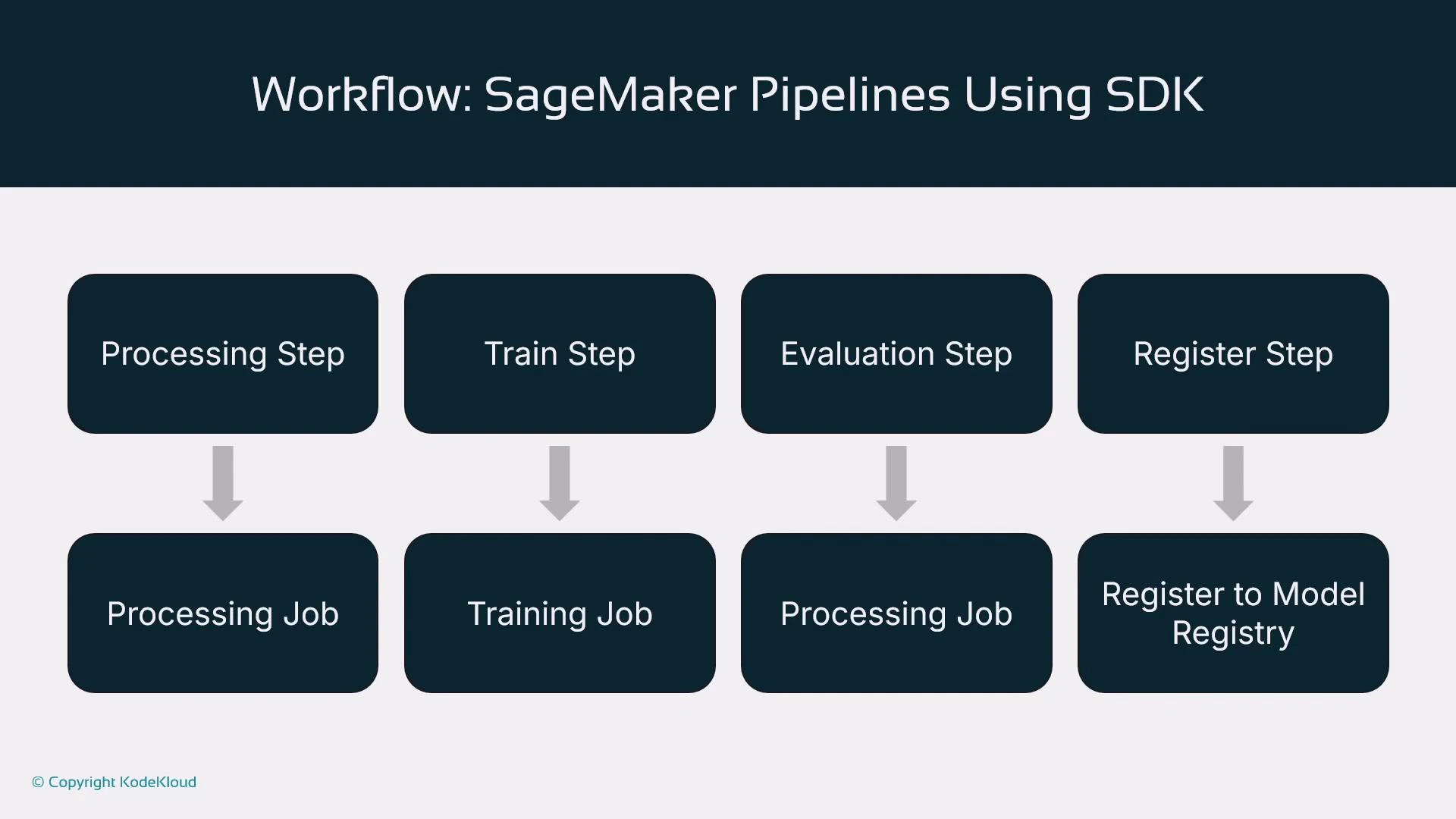
Example: Build a SageMaker Pipeline using the SDK
Below is a concise, complete example that defines a data preprocessing ProcessingStep, a TrainingStep, a model evaluation ProcessingStep, and a RegisterModel step. Finally, these steps are assembled into a Pipeline object and executed. Assumptions:- SDK imports,
role,pipeline_session,bucket,input_data,train_instance_type, andtrain_instance_countare already defined and configured.
- Define steps first; the pipeline’s step list dictates execution order.
- pipeline.upsert(…) creates or updates the pipeline resource in SageMaker.
- pipeline.start() launches an execution; use execution.describe() to inspect status.
- Parameterize S3 paths, instance types, and instance counts for flexible reuse.
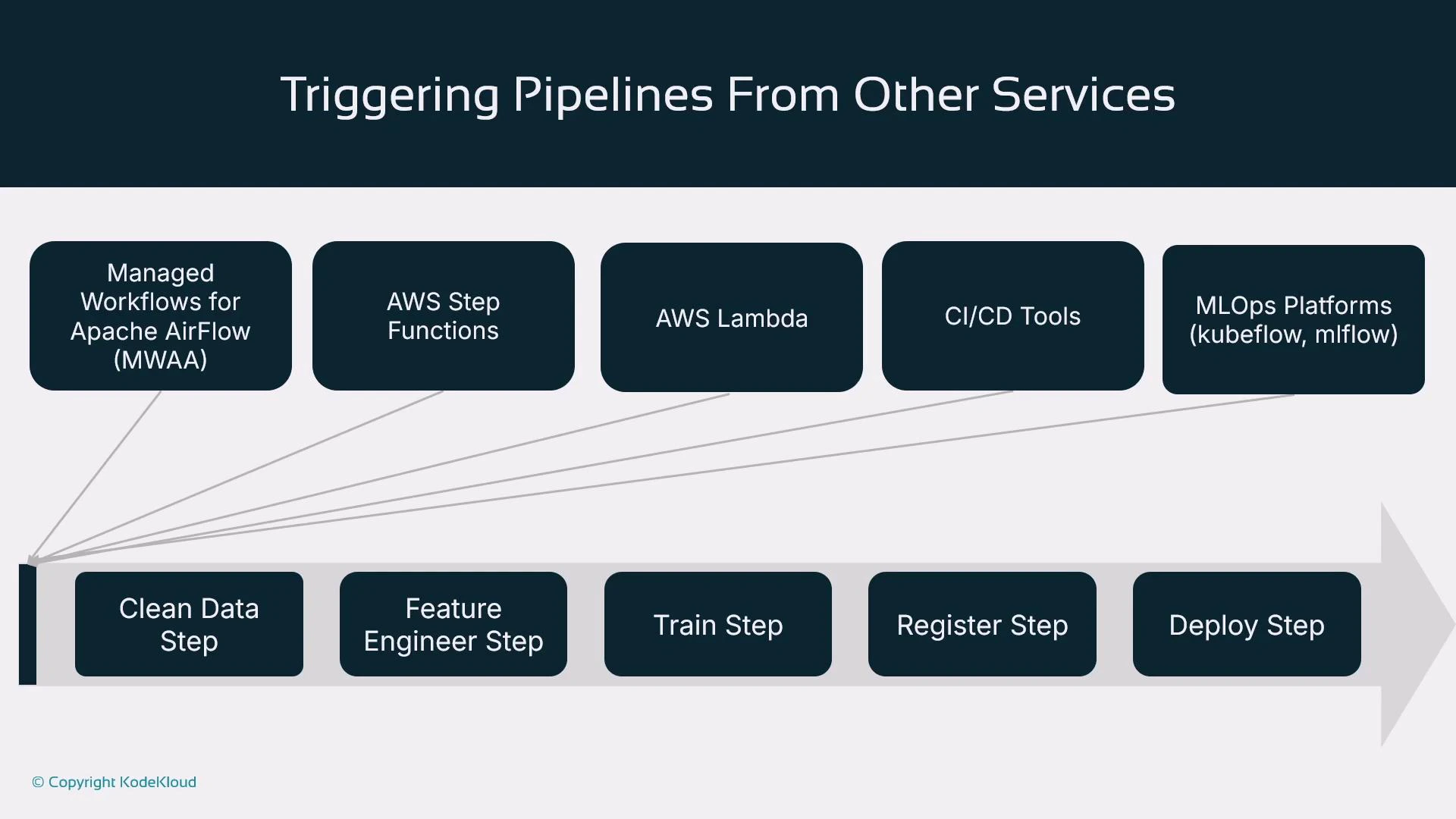
Triggers: how pipeline executions start
You can start a pipeline directly with pipeline.start(), but production pipelines are usually triggered by external systems:
References:
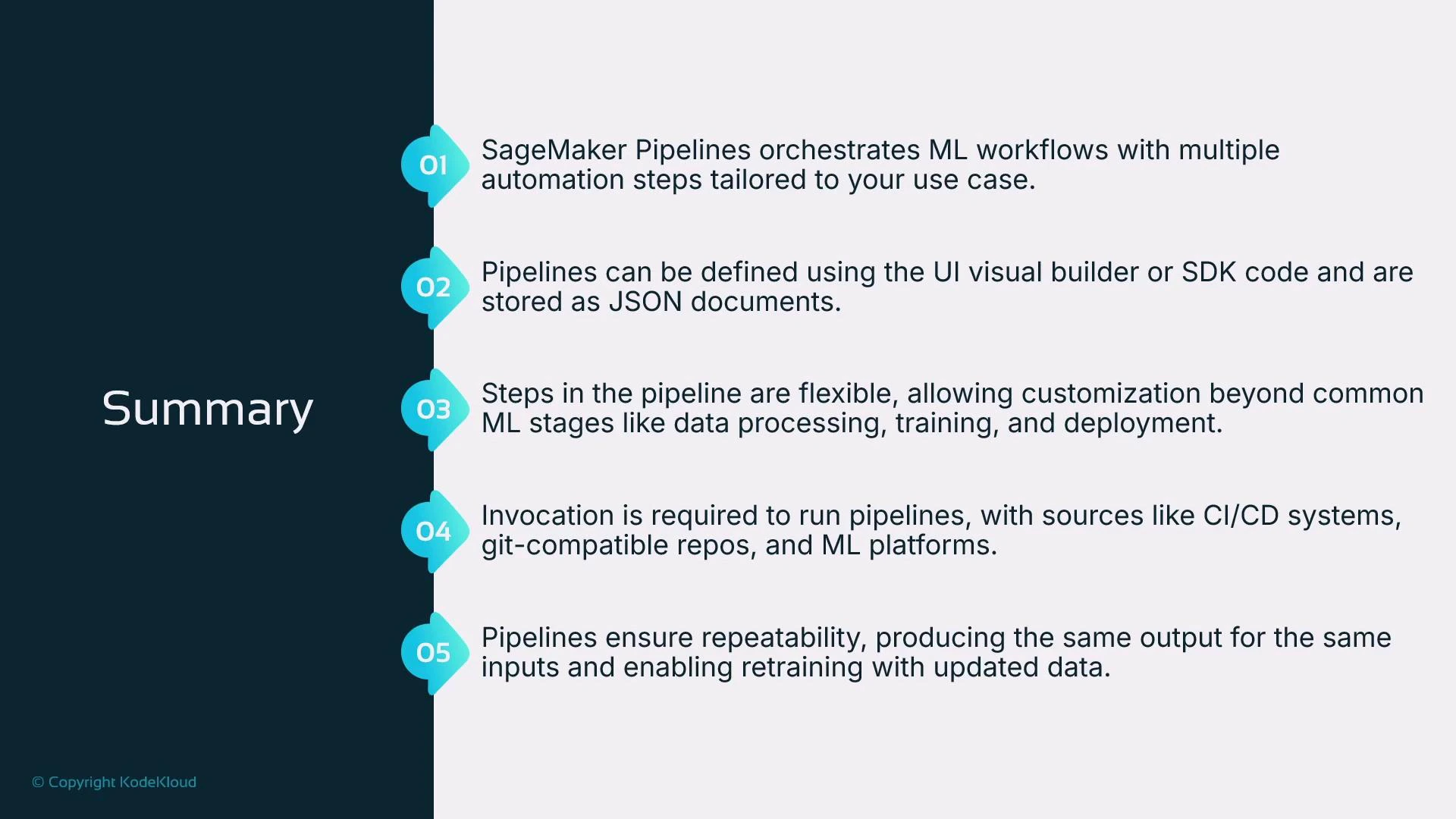
Summary
- SageMaker Pipelines orchestrates ML workflows and moves teams from manual notebook-driven experimentation to automated, reproducible pipelines.
- You can author pipelines via the Studio Visual Editor (low-code) or, preferably, via the SageMaker Python SDK for full control and version-in-code.
- Common steps include processing, training, evaluation, model registration, and deployment.
- Pipelines are typically triggered by external orchestrators (CI/CD, Step Functions, Airflow, MLOps platforms).
- The objective is repeatability: given the same inputs, pipelines produce consistent outputs and provide traceable lineage.
Next steps
Continue learning by exploring how to bootstrap new ML projects with predefined SageMaker pipelines that provide a reproducible starting point for experimentation and productionization. Consider creating a Git-backed project template that includes:- Standardized scripts (clean.py, feature.py, train.py, evaluation.py, register.py)
- CI/CD pipeline definitions to validate and trigger SageMaker pipelines
- Terraform or CloudFormation templates for infrastructure reproducibility