- Why manual model training can be costly and slow.
- What SageMaker AutoML / Autopilot automates.
- How to run Autopilot from the SageMaker SDK, inspect candidates, and deploy the best model.
- Best practices and when to use Autopilot vs. custom training.
- Managing dataset versions, feature processing, algorithm selection, and hyperparameter permutations creates a large combinatorial search space.
- Running every permutation is time-consuming and costly even with experiment tracking.
- Data scientists often reduce the search space using domain knowledge, but that still requires many training runs.

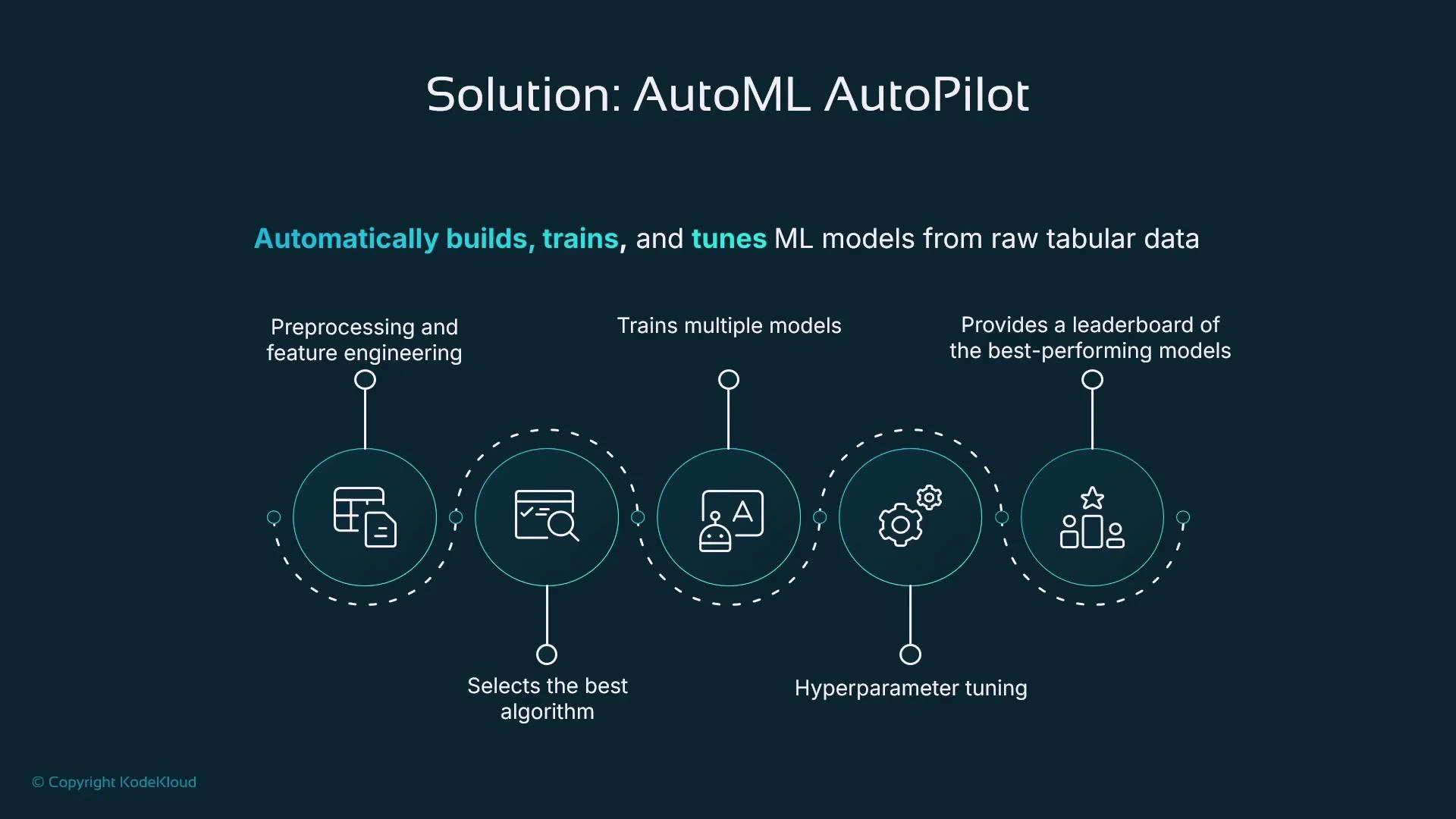
- Automates preprocessing and feature engineering.
- Selects algorithms suited to your tabular problem.
- Trains multiple candidate models and tunes hyperparameters.
- Produces a ranked leaderboard so you can pick the best candidate quickly.
- Exposes model artifacts and notebooks for inspection and further customization.
- Programmatic control: integrate Autopilot into CI/CD pipelines and automated workflows.
- Access to artifacts: notebooks, model artifacts, and details about candidate models.
- Customization: you can set guardrails (max candidates, runtime) and then inspect and refine outputs manually.
- Seamless deployment: take the best candidate and create a SageMaker Model/endpoint.

- Preprocessing and feature engineering
- Algorithm selection
- Training multiple candidate models
- Hyperparameter tuning
- Leaderboard of top candidates
- AutoML (general): automation techniques applied to machine learning workflows.
- Autopilot (specific): Amazon SageMaker’s AutoML implementation for tabular data.
- In the SageMaker SDK you may see both “AutoML” and “Autopilot” references; the module is typically sagemaker.automl.
Autopilot is excellent for rapid prototyping and automating many training details, but if you require fine-grained control over feature engineering or model internals you should extract the candidate artifacts and continue development manually.
Quick reference: common Autopilot parameters
Example: run an Autopilot job with the SageMaker SDK
- Best practice: import the AutoML class explicitly from the submodule to make intent clear.
- After starting the job, you can describe the Autopilot job, list candidates, and pick the best candidate programmatically.
- Extract the model artifact and container image from the best candidate and create a SageMaker Model, then deploy to an endpoint.
- Explicit imports: import exact classes/functions you use for clarity and to avoid accidental submodule side effects.
- Use guardrails: set max_candidates and runtime limits to control cost.
- Inspect artifacts and notebooks produced by Autopilot to learn what preprocessing and features were used.
- Use Autopilot outputs as a starting point — you can register models in the SageMaker Model Registry and iterate further.
Autopilot automates many steps but is not a silver bullet. It can reduce time-to-insight for tabular problems, but you should still validate candidate models, check fairness/robustness, and apply custom feature engineering for production-ready models.
- An end-to-end automated pipeline from raw tabular data to trained and evaluated candidate models.
- A leaderboard of ranked candidates and metrics.
- Programmatic access to model artifacts so you can register, deploy, or refine models further.

- AutoML is the general concept of automating machine learning tasks; Autopilot is SageMaker’s AutoML for tabular data.
- You can use Autopilot through SageMaker Canvas (low-code) or programmatically through the SageMaker SDK.
- Autopilot handles preprocessing, feature engineering, algorithm selection, hyperparameter tuning, and candidate ranking.
- Control inputs like problem type, input data location, output path, and constraints such as max candidates and runtime to manage cost and runtime.
- Use Autopilot for speed and prototyping; refine the best candidate with custom data science work when you need production-grade control.
- SageMaker Autopilot (AutoML): https://docs.aws.amazon.com/sagemaker/latest/dg/autopilot-what-is.html
- SageMaker SDK documentation: https://sagemaker.readthedocs.io/
- SageMaker Canvas: https://aws.amazon.com/sagemaker/canvas/
- SageMaker Model Registry: https://docs.aws.amazon.com/sagemaker/latest/dg/model-registry.html