- Review the Data Wrangler–processed dataset exported for Canvas.
- Create a Canvas AutoML training job using the processed dataset.
- Inspect training artifacts, metrics, and feature attributions.
- Run sample single-record inference and learn how to deploy the model.
- Data Wrangler standardizes and documents your preprocessing steps.
- Canvas AutoML speeds up model exploration without requiring code.
- When you need production-grade models, you can take artifacts from Canvas and iterate using SageMaker Studio or the SDK.
Canvas instances are billed while running. Stop the instance when not in use to avoid unexpected costs.
1 — Verify the exported dataset from Data Wrangler
We used Data Wrangler to clean and transform the house‑price dataset: removing unnecessary columns, imputing missing values, scaling numeric features, applying ordinal encoding for some features and one‑hot encoding for others. The Data Wrangler flow exported the transformed dataset to SageMaker Canvas (and optionally to S3).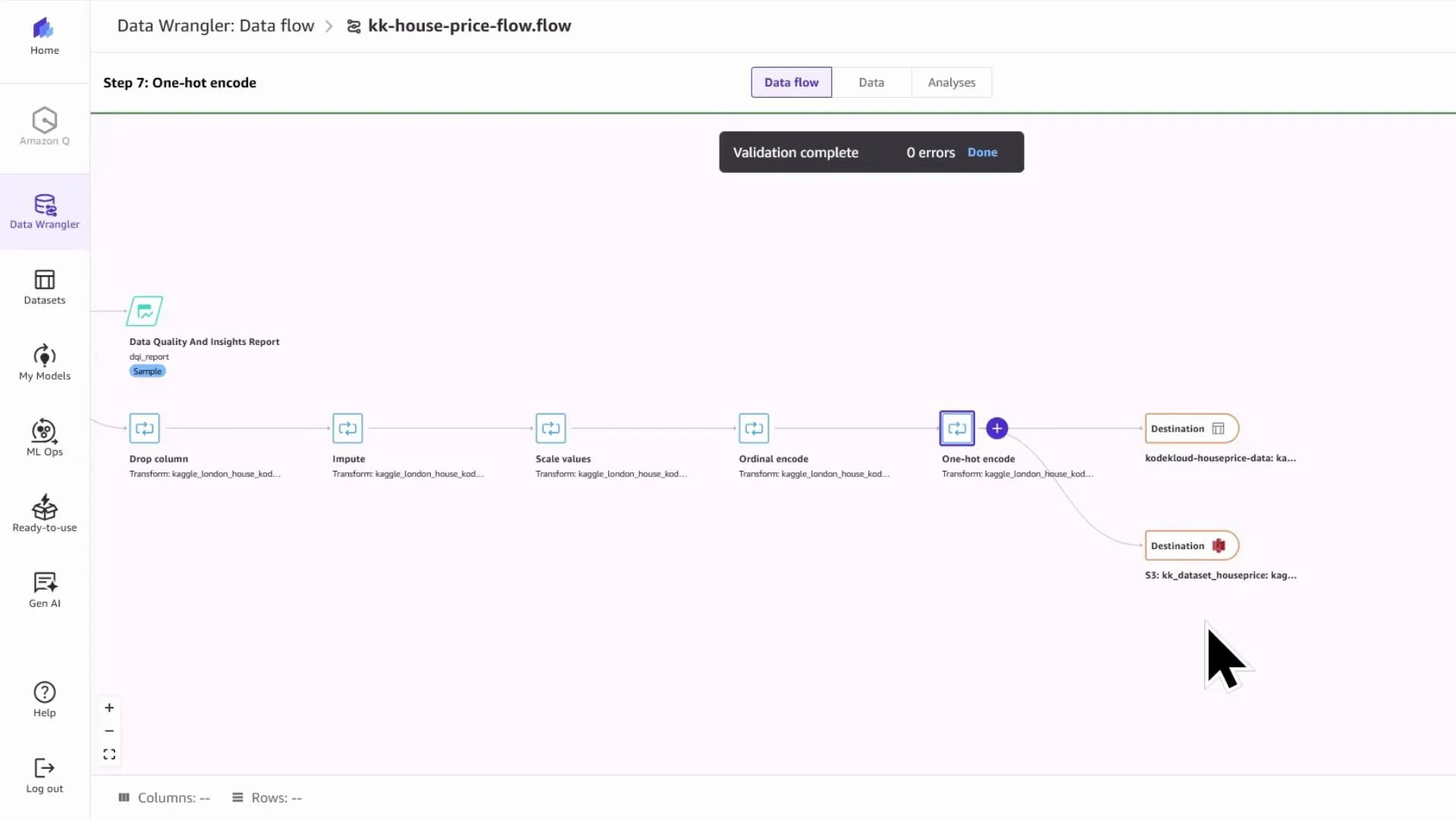
2 — Create a Canvas AutoML model (Quick Build)
- With the Canvas dataset selected, click Create model.
- Give the model a name (example:
kodekloud-canvas-demo) and choose the problem type. For predicting sale prices you want a numeric/regression model — not image or text.
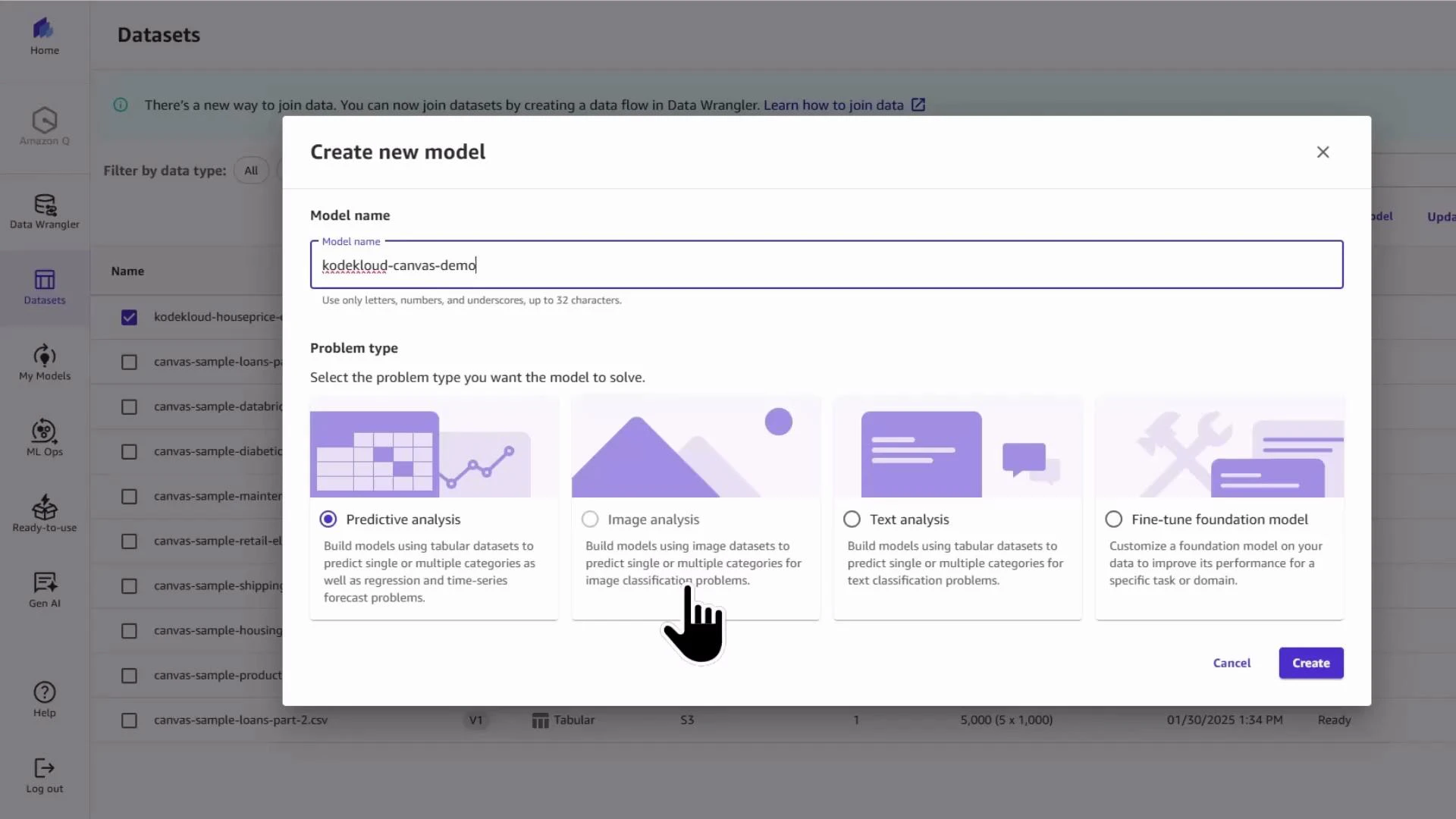
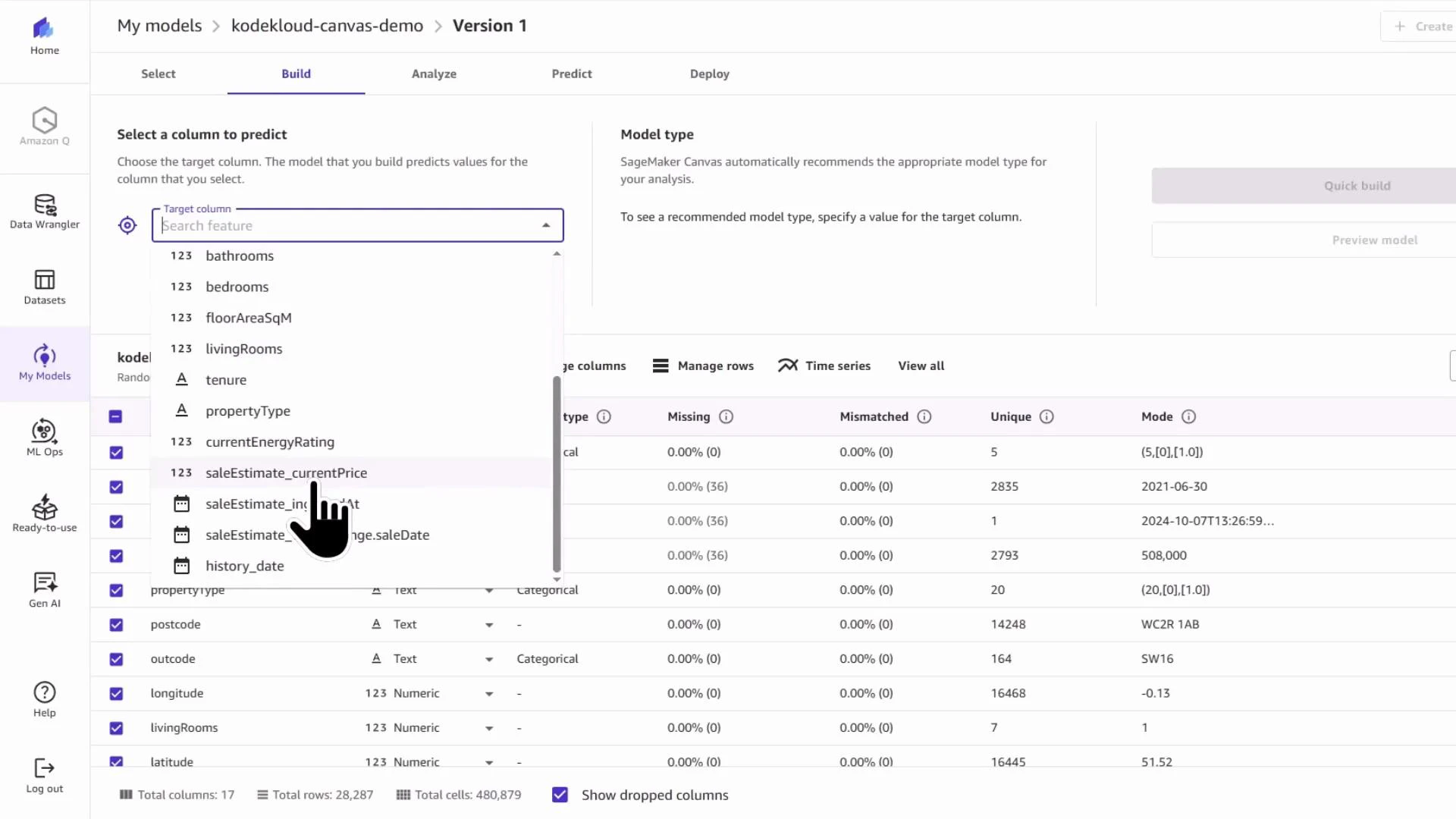
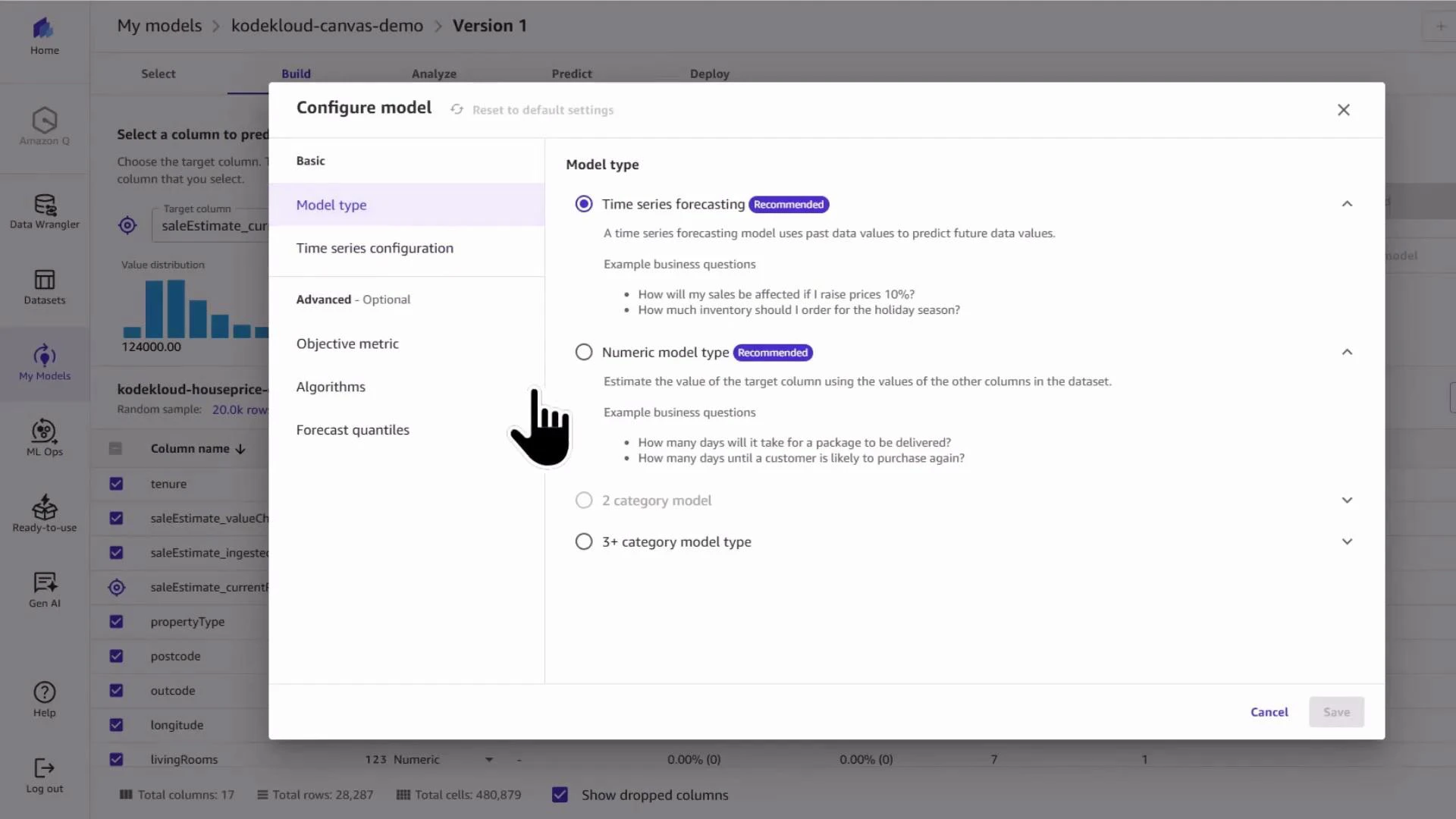
Canvas AutoML can misidentify the problem type when time-related columns exist. Explicitly choose numeric/regression when predicting continuous values.
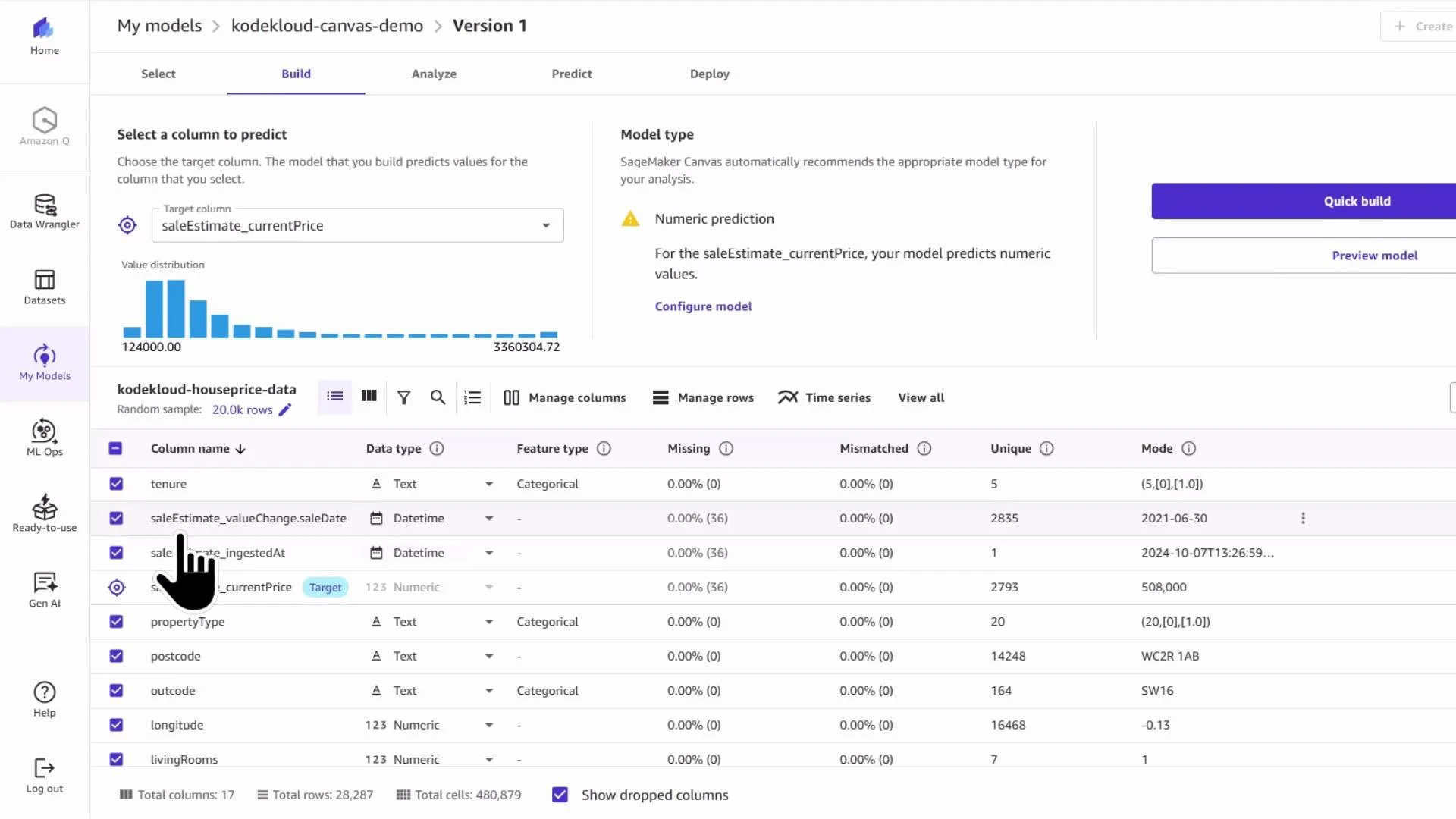
- Exclude verbose free-text address fields.
- Keep postcode prefix, latitude and longitude for geographic signals.
- Keep numeric predictors such as bedrooms, bathrooms, energy rating, floor area, and tenure.
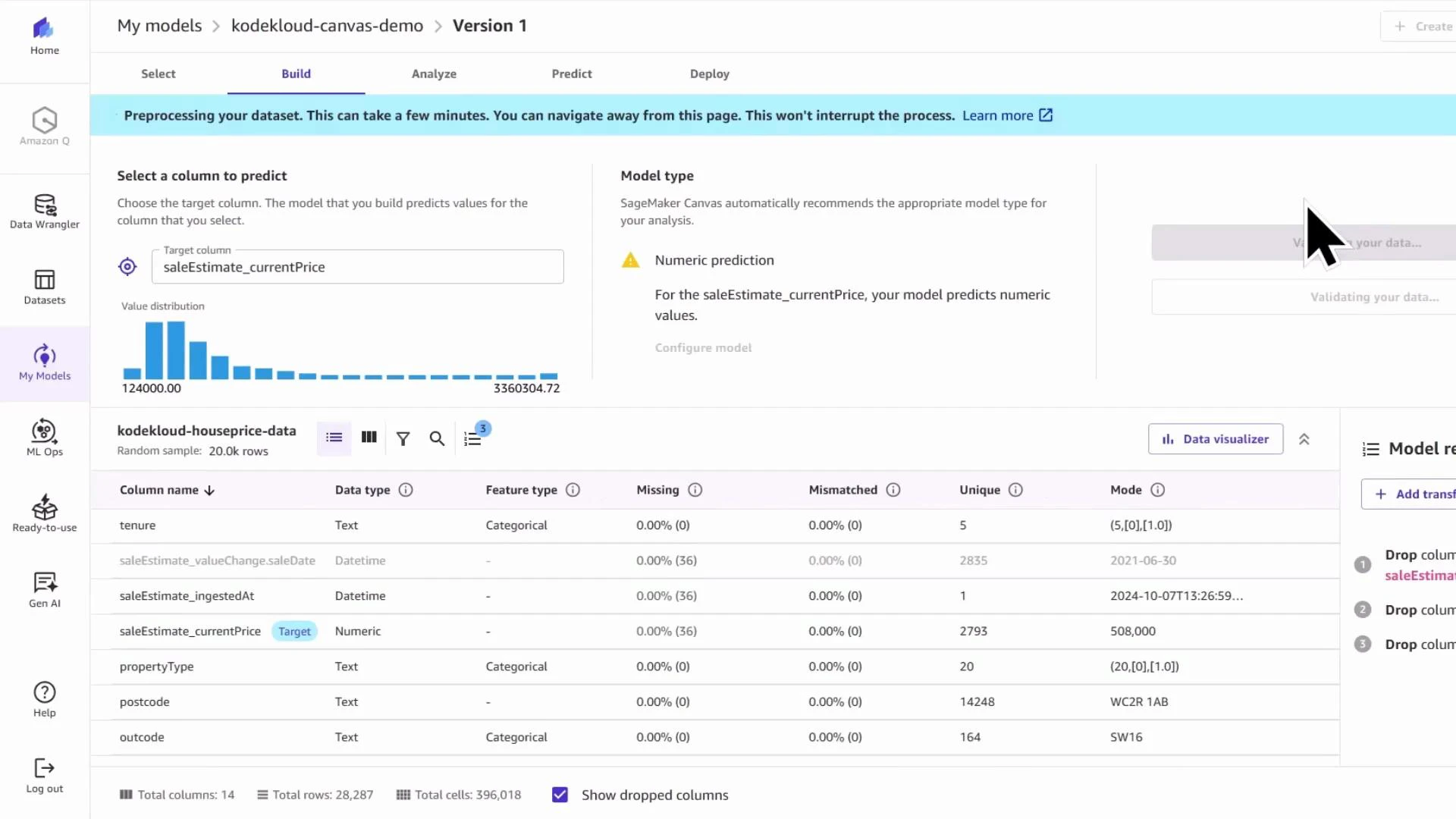
3 — Inspect the underlying SageMaker training job
Canvas creates a standard SageMaker training job under the hood. You can monitor it from SageMaker Studio → Jobs → Training to inspect hyperparameters, input channels, and output artifacts. This transparency helps you reproduce or customize runs later via the SDK. Example job status overview: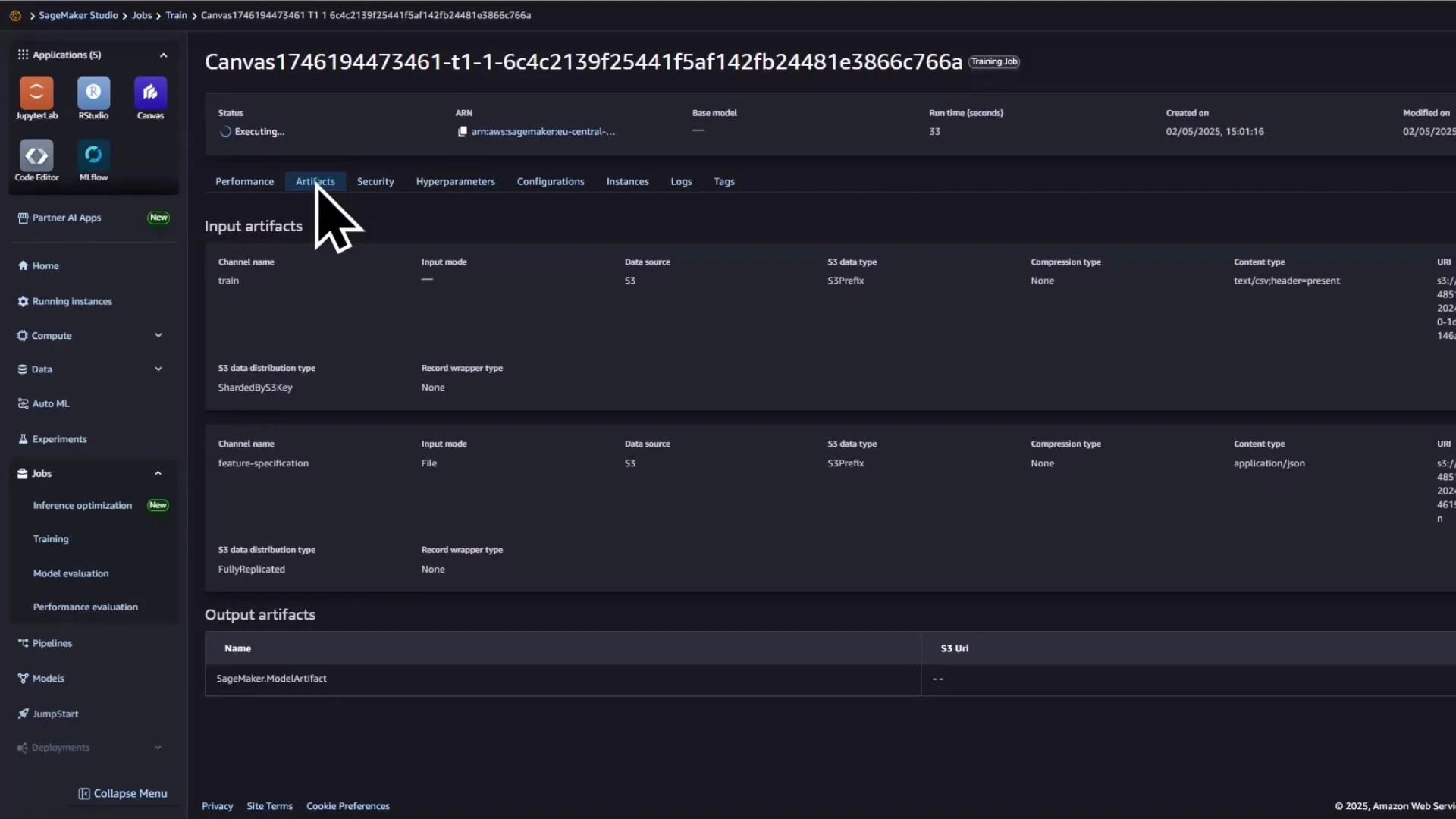
4 — Review metrics, feature importance, and diagnosis
After Quick Build completes, Canvas surfaces performance metrics (RMSE, MSE) and feature attributions. A high RMSE indicates the model is not yet production-ready and suggests further iteration: handle outliers, transform the target (e.g., log transform), re-encode categories, add external features, or remove leakage.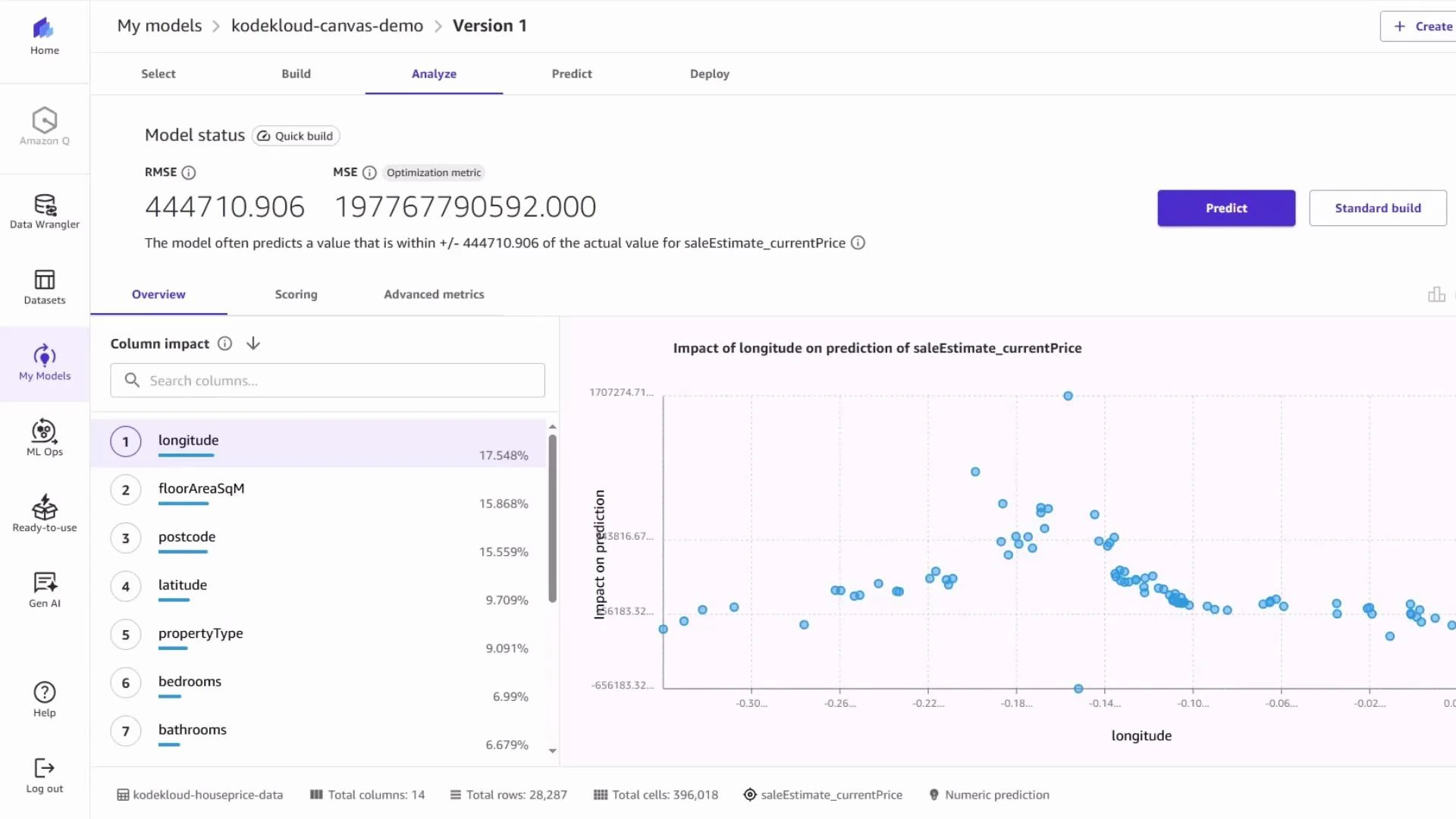
- Remove or treat extreme outliers.
- Log-transform skewed targets.
- Create interaction features (e.g., bedrooms × floor area).
- Add external geographic or neighborhood statistics.
- Re-check training/test splits for leakage.
5 — Test predictions (single and batch)
Even if the RMSE is high, you can still exercise the model with single-record or batch predictions to validate end-to-end behavior. Example single prediction input (London property):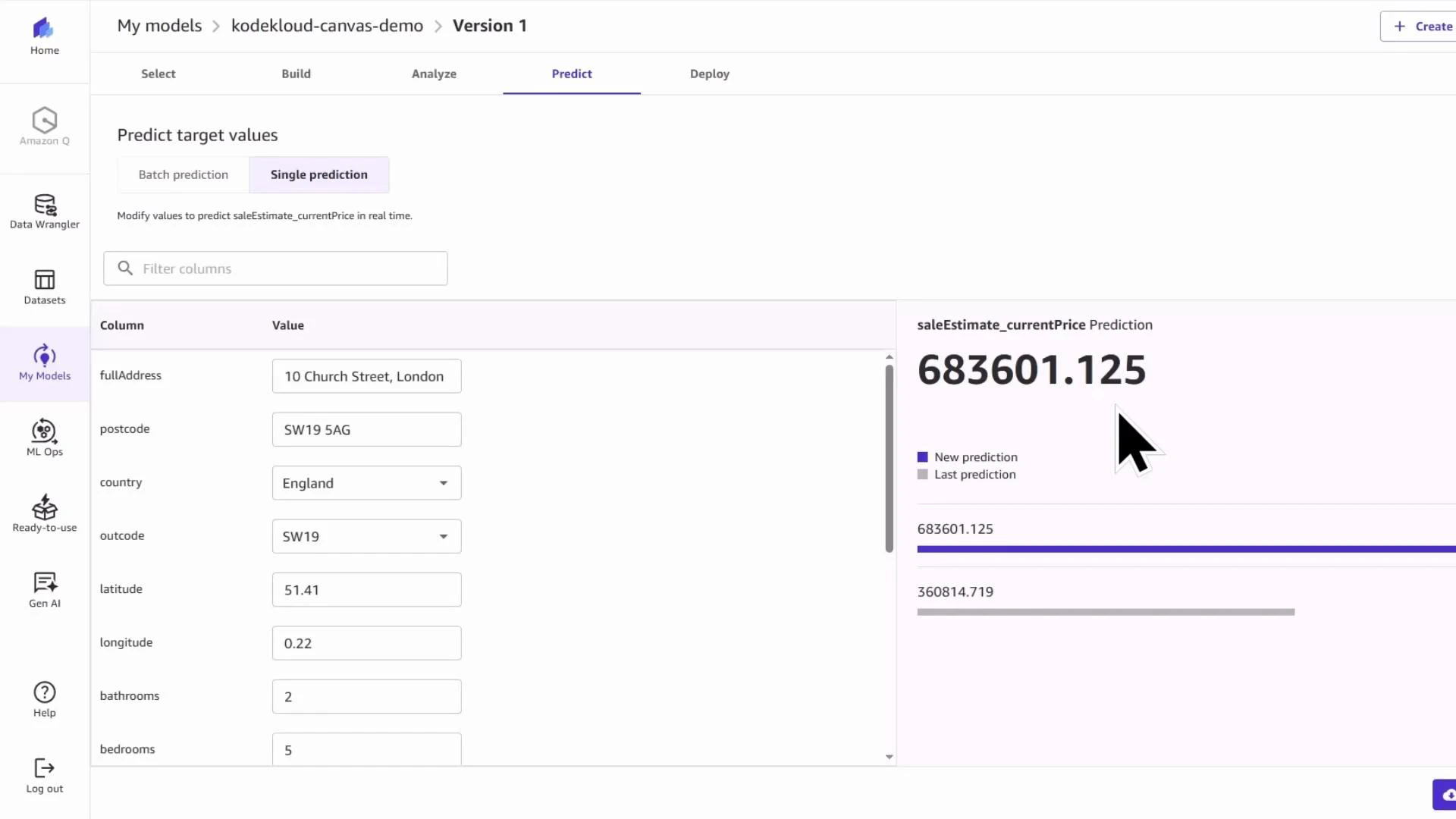
6 — Deploy to a SageMaker endpoint (when ready)
When model performance meets your acceptance criteria, Canvas supports direct deployment to a hosted SageMaker endpoint. Choose Create deployment, provide a deployment name and select instance size to create a real-time inference endpoint.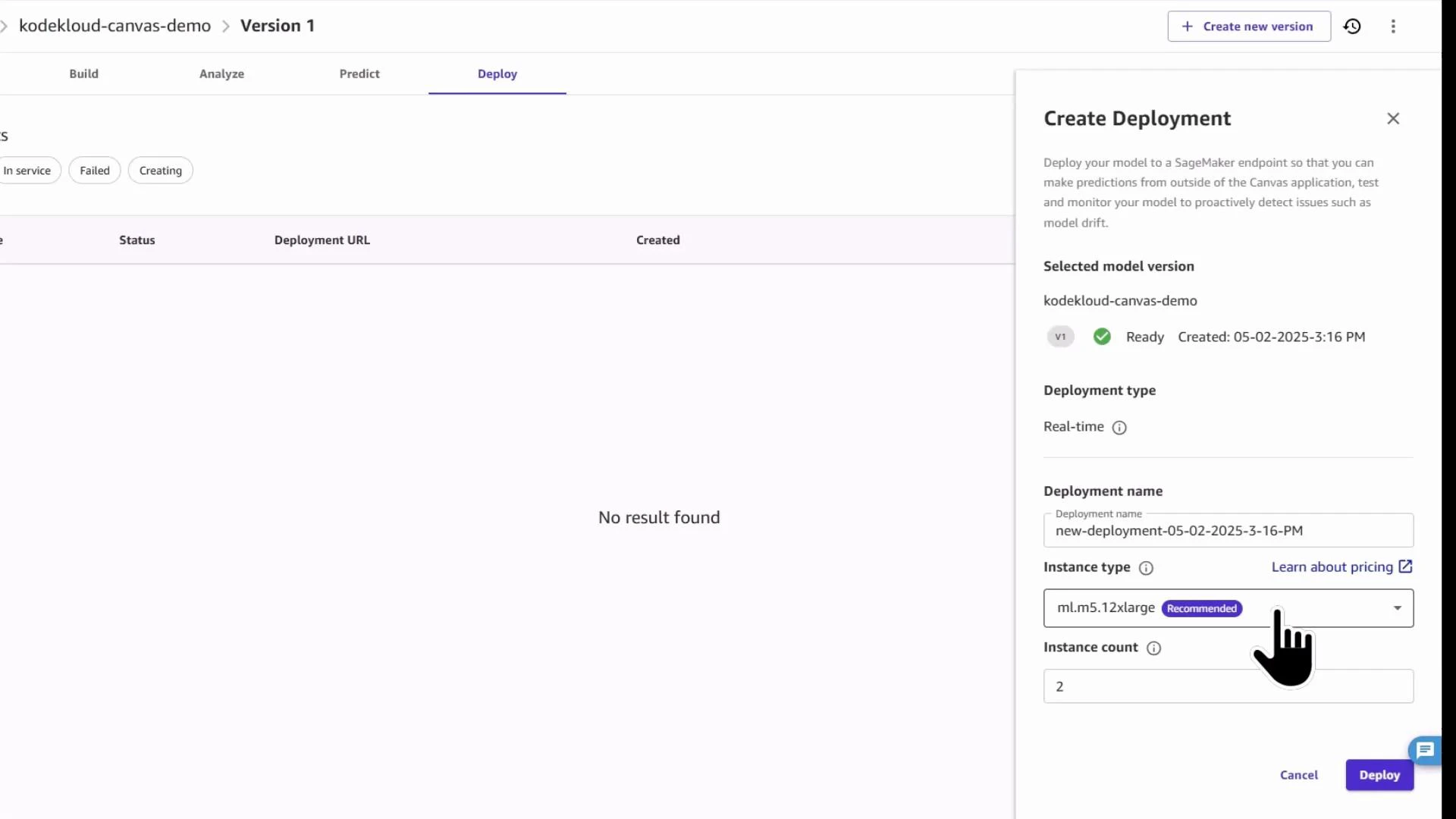
Quick reference
Summary
- Feed a Data Wrangler–processed dataset into SageMaker Canvas to speed model prototyping.
- Set the correct problem type (numeric/regression) and review feature inclusion.
- Use Quick Build to run Canvas AutoML, then inspect the generated SageMaker training job.
- Evaluate metrics (RMSE/MSE) and feature importance to guide iterative improvements.
- Test single or batch inference; deploy via Canvas when satisfied.
- Amazon SageMaker Canvas documentation
- Amazon SageMaker Data Wrangler documentation
- SageMaker pricing