
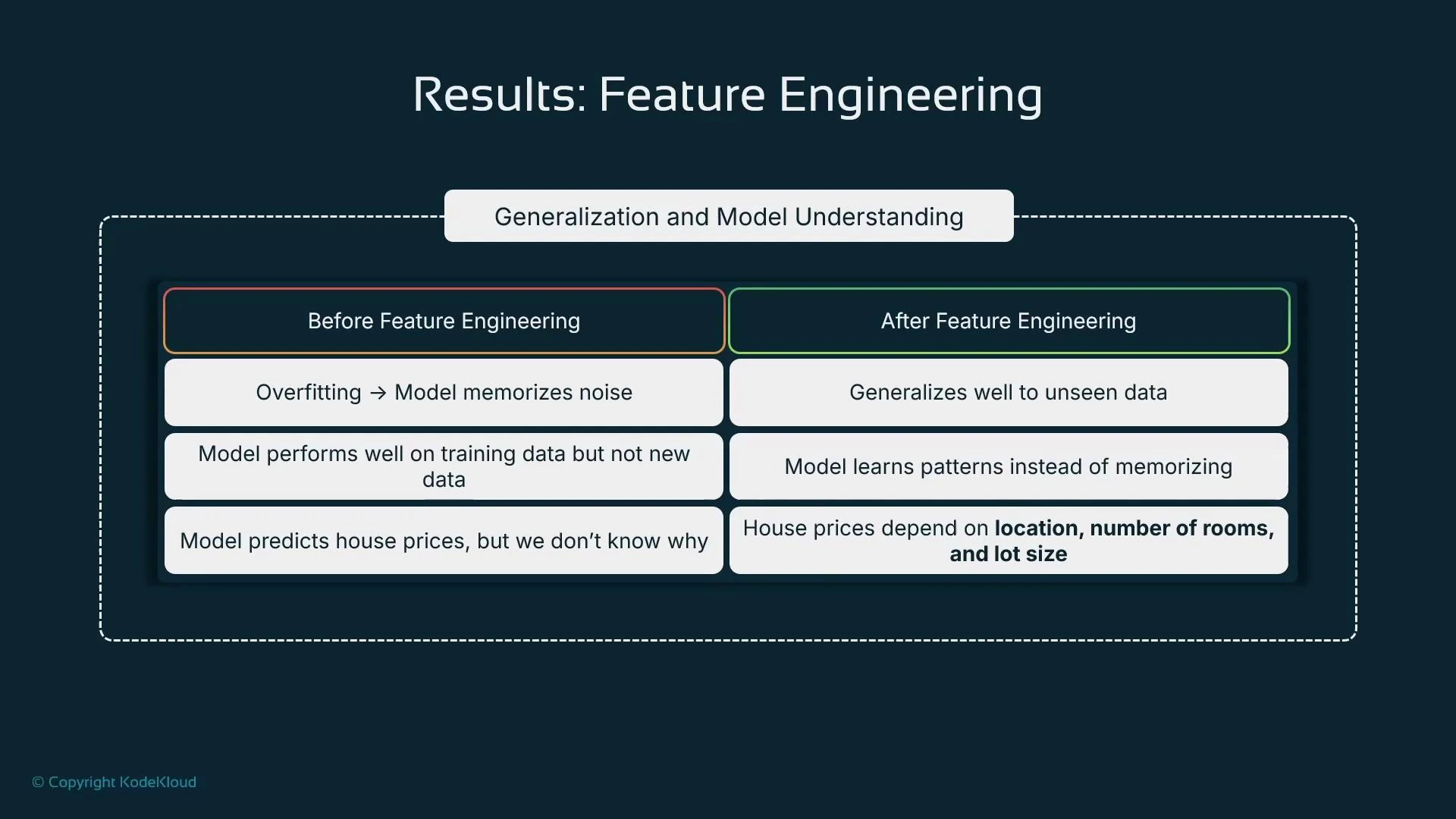
- Stronger features produce clearer correlations between inputs and targets, yielding more accurate predictions and lower error metrics (e.g., reduced mean squared error for regression).
- Feature engineering can reduce bias by exposing relevant signals, which leads to better-optimized model parameters and improved generalization.
- Well-crafted features often allow simpler models to achieve competitive performance and reduce the need for deeper architectures.
- Training usually converges faster on feature-engineered data, meaning fewer epochs and less hyperparameter tuning.
Why improved features help generalization
Overfitting happens when a model learns noise or peculiarities in training data rather than underlying patterns. Effective feature engineering reduces this risk by surfacing meaningful relationships and removing spurious signals—helping the model perform well on unseen data.
Overfitting is when a model memorizes training examples and performs poorly on new data. Thoughtful feature engineering mitigates overfitting by exposing true predictive signals and reducing noisy or irrelevant inputs.
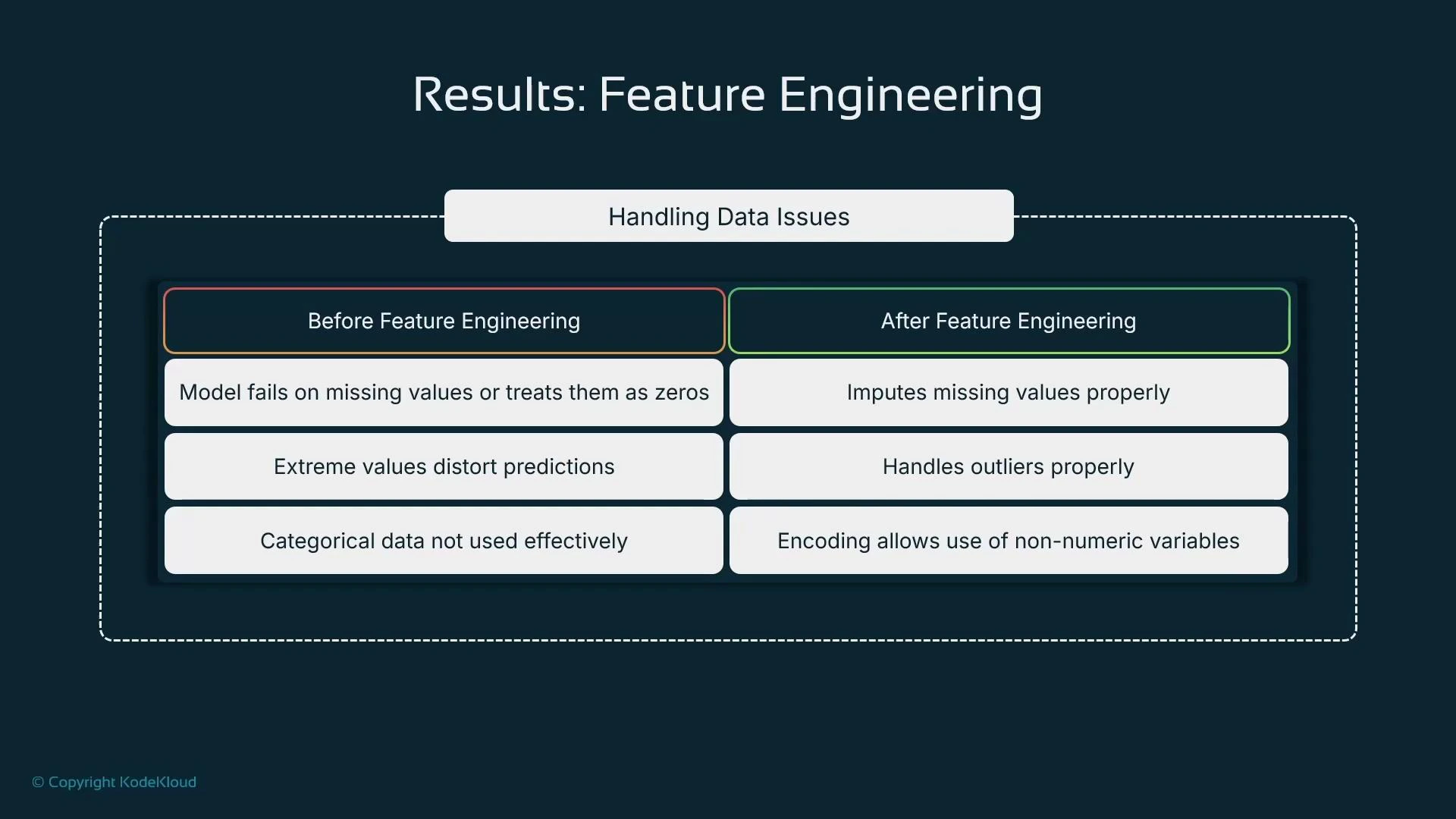
- Missing values: apply per-feature strategies such as mean/median imputation, KNN imputation, or model-based methods; consider adding a missing-value indicator.
- Outliers/extreme values: use clipping, winsorizing, trimming, or model-based handling depending on whether extremes are valid signals.
- Categorical variables: choose one-hot, ordinal, target/mean encoding, or learned embeddings based on cardinality and model type.
These decisions influence both predictive performance and interpretability—so combine domain knowledge with algorithmic considerations when choosing strategies.
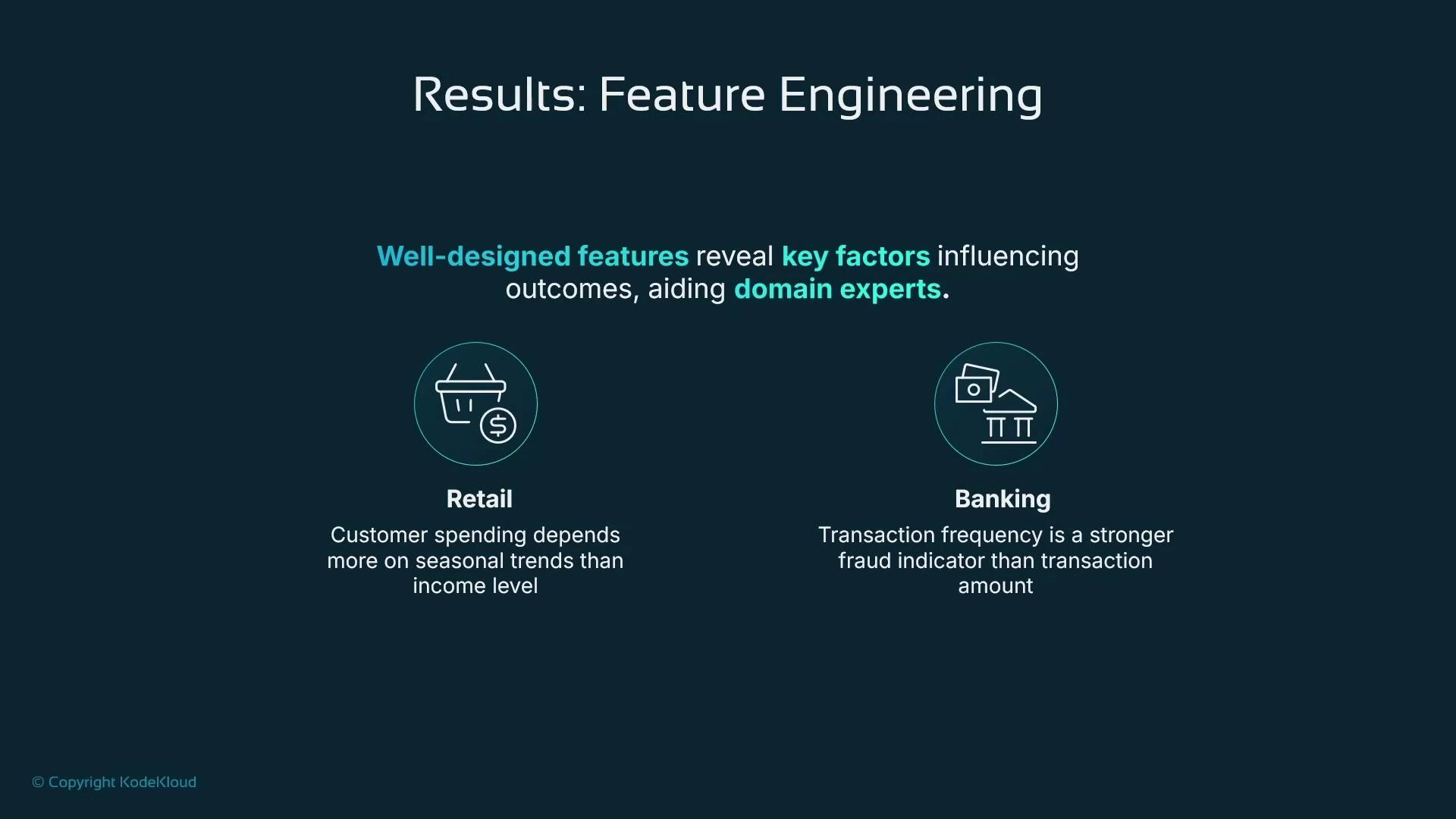
- Retail: Customer spend is often driven by seasonality or promotions rather than static income. Time-based features—month, week-of-year, holiday flags, rolling aggregates—can dramatically outperform raw income variables.
- Banking and fraud detection: Velocity and patterns (transactions per day, time since last transaction, anomalous sequence patterns) often indicate fraud more reliably than single-transaction amounts. Aggregate and ratio features are especially valuable.
- Cleaned data is a necessary starting point but not sufficient—feature engineering extracts predictive signals that raw cleaning does not.
- Typical feature engineering steps: drop irrelevant variables, transform skewed features (log, power), synthesize new features (ratios, differences, timestamps to ages), and choose appropriate encodings.
- Consider the model family: tree-based models, linear models, and neural networks expect different feature representations (e.g., scaling matters more for linear and neural models than for many tree models).
For large-scale transformations (e.g., applying min-max scaling or computing rollups on millions of rows), use managed batch processing (for example, a SageMaker Processing Job) instead of running heavy operations in an interactive notebook—this avoids resource contention and speeds up reproducible pipelines.
Links and further reading
- pandas
- NumPy
- scikit-learn
- SageMaker Processing Jobs
- Kubernetes Documentation (for orchestration and deployment patterns)
