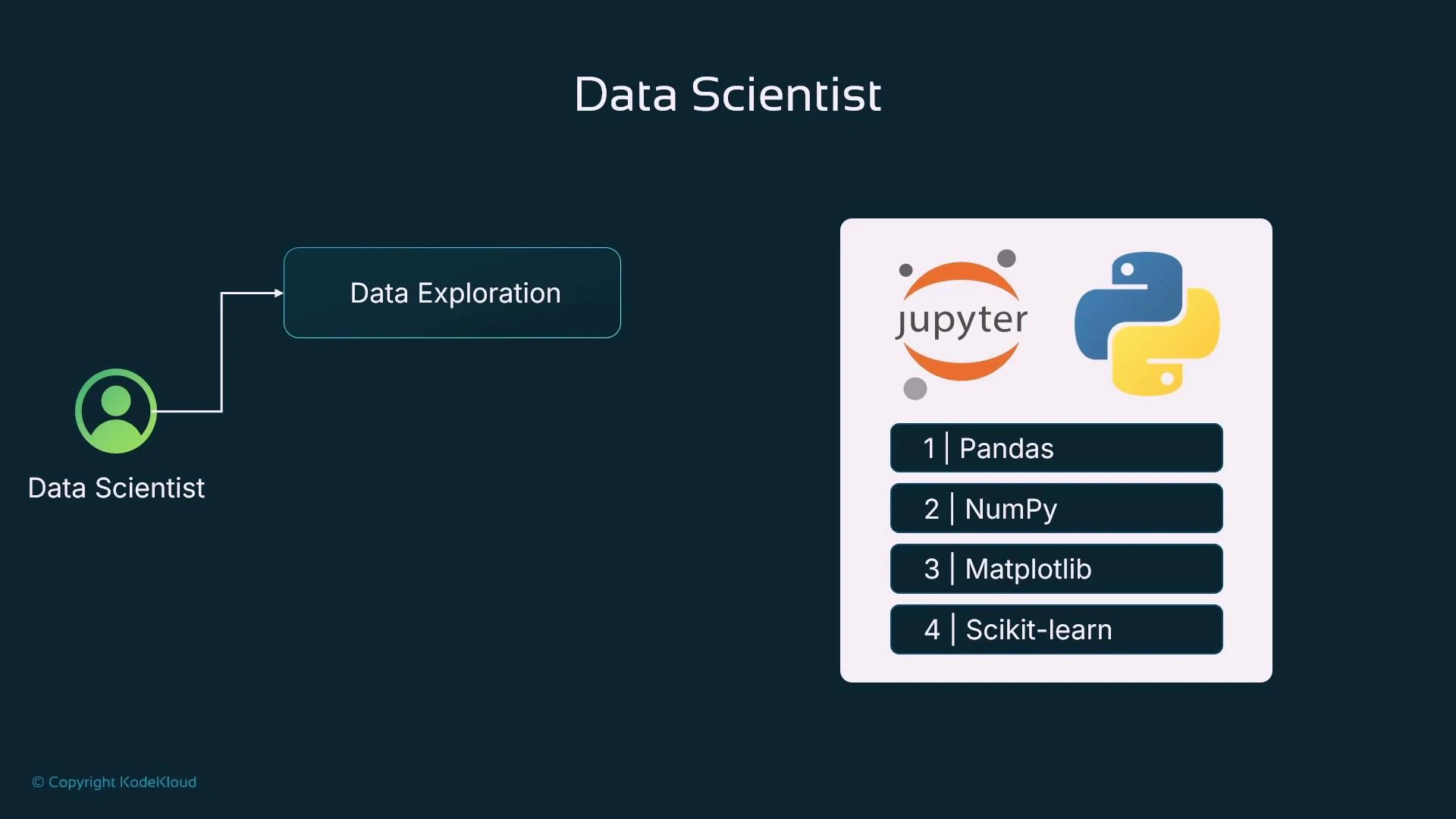
Data exploration and interactive analysis
Data scientists start by getting to know the dataset: understand features and targets, spot correlations and outliers, and identify columns to drop. This phase is highly interactive — you run small code cells, inspect outputs, create visualizations, and document reasoning for reproducibility. Jupyter Notebooks or JupyterLab are the default environment for this iterative workflow: run Python cells, visualize inline, and annotate with Markdown to capture findings that can be shared or re-run.
- Load tabular data into a pandas DataFrame for inspection and manipulation.
- Use NumPy for fast vectorized numerical ops when required.
- Visualize distributions, correlations, and model diagnostics with Matplotlib/Seaborn.
- Use scikit-learn for quick baseline models and common preprocessing (imputation, scaling, encoding) to validate ideas.
Feature engineering
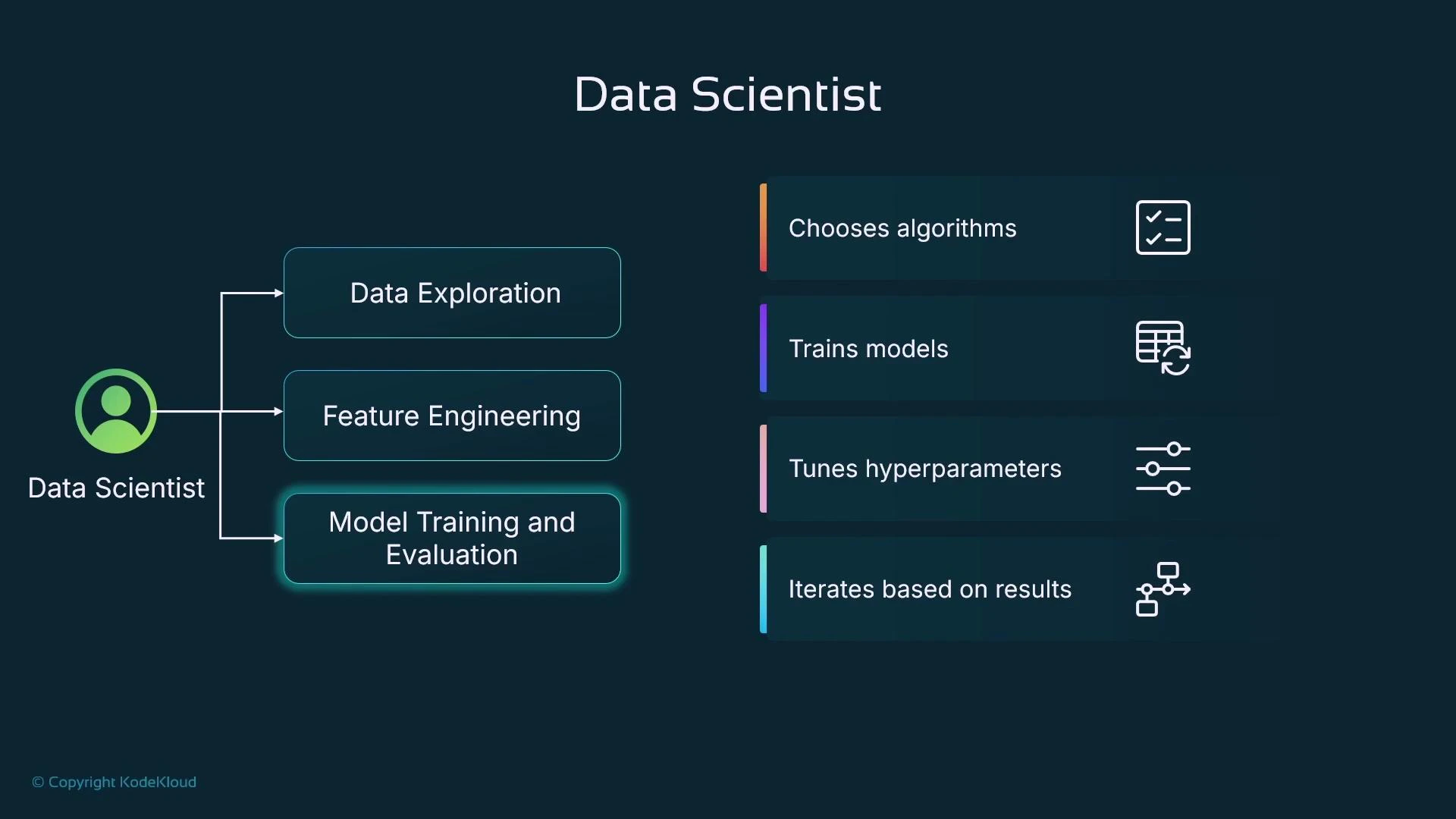
Once the dataset is understood, feature engineering prepares inputs for modeling. Common steps:- Drop non-predictive columns and reduce cardinality where appropriate.
- Convert categorical variables to numeric form (one-hot, ordinal, target encoding, or embeddings).
- Handle missing values (imputation strategies: mean, median, model-based).
- Normalize / standardize numeric features.
- Create derived features (date/time decompositions, feature crosses).
- Reduce dimensionality (feature selection, PCA, or regularization-aware models).
Always confirm the encoding strategy is appropriate for the model and data. For example, one-hot encoding can explode dimensionality for high-cardinality categorical features—consider alternatives like embedding-based approaches or feature hashing in those cases.

Model training, evaluation, and iteration
Data scientists run experiments across algorithms (e.g., XGBoost, LightGBM, or deep learning) and hyperparameters. Each run produces model artifacts and evaluation metrics; when using managed training, artifacts commonly persist to object storage (e.g., Amazon S3). Standard evaluation patterns:- Hold-out split (typical: 70% train / 20% validation / 10% test) or cross-validation.
- Monitor validation metrics to compare runs and avoid overfitting.
- Track hyperparameters (learning rate, epochs/rounds, batch size, regularization) and their impact.
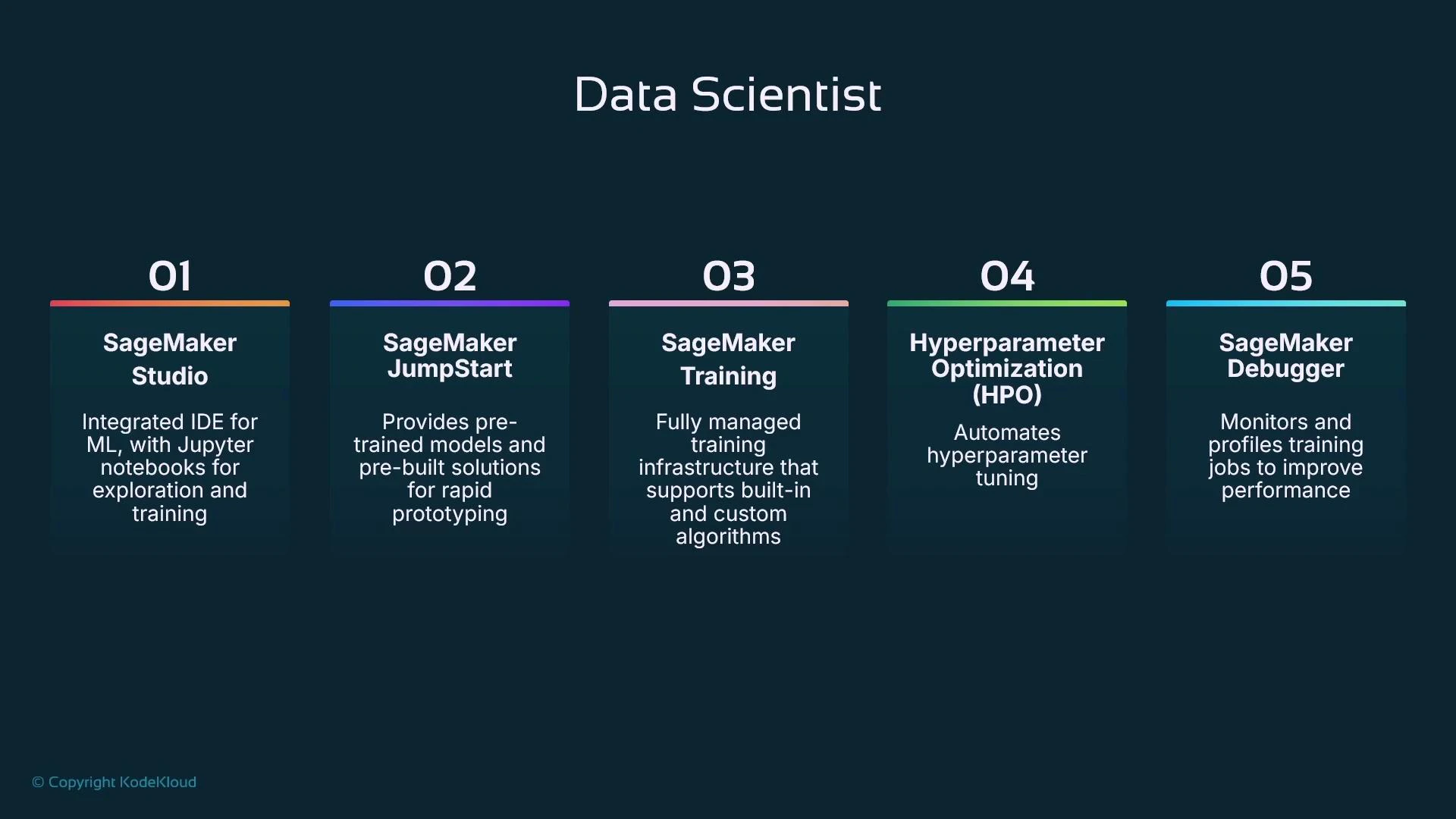
How Data Scientist tasks map to a managed ML platform
- Hosted, browser-based notebook environments (like SageMaker Studio) let data scientists author and run experiments with managed compute and seamless integrations.
- Model catalogs and prebuilt examples (JumpStart) accelerate prototyping using pre-trained models or templates.
- Managed training jobs provision compute (CPU/GPU), run training, and persist model artifacts to storage (S3).
- Automated hyperparameter optimization services search the configuration space efficiently.
- Training-level debuggers and profilers collect metrics and tensors during training to reveal bottlenecks.
Personas and collaboration
Three complementary ML personas and their responsibilities:- Data Engineer: builds repeatable ETL/ELT pipelines, cleans and transforms raw data, and delivers production-ready datasets for downstream modeling.
- Data Scientist: performs exploratory data analysis, feature engineering, model experimentation, and delivers trained models and documented notebooks.
- MLOps Engineer: automates end-to-end ML workflows (CI/CD for models), orchestrates training/deployments, manages model registry/versioning, and ensures safe production releases.

Recap
- Data engineers prepare repeatable data extraction and transformation pipelines to deliver clean datasets.
- Data scientists explore data, engineer features, run iterative training experiments with different algorithms and hyperparameters, and produce trained models and documented notebooks.
- MLOps engineers automate, test, version, and deploy models and pipelines for production usage.
References and further reading
- Jupyter: https://jupyter.org
- pandas documentation: https://pandas.pydata.org/
- scikit-learn: https://scikit-learn.org/
- XGBoost: https://xgboost.ai/
- LightGBM: https://lightgbm.readthedocs.io/
- Amazon SageMaker docs: https://docs.aws.amazon.com/sagemaker/latest/dg/
- Amazon S3 docs: https://docs.aws.amazon.com/s3/index.html