Observability goes beyond collecting metrics and logs — it’s about understanding whether systems and ML models are behaving normally and producing correct outcomes. Good observability combines platform and infrastructure signals (for availability and latency) with model-centric signals (for data quality, drift, and fairness).
- Ensure models continue to perform as expected in production.
- Detect issues such as model drift, data-quality problems, and performance regressions.
- Combine two complementary approaches:
- AWS CloudWatch — infrastructure- and service-level metrics and logs.
- SageMaker Model Monitor — model-centric monitoring for data quality, drift, and bias.
- Infrastructure health
- A deployed model runs on managed compute (for example, a SageMaker endpoint). If the instance is undersized, inference can suffer from CPU/GPU/memory or I/O contention.
- Monitor resource utilization and latency to ensure the deployment meets your SLA and scaling requirements.
- Model health
- Beyond infrastructure: confirm the model continues to make correct predictions.
- Detect distribution shifts by comparing inference inputs to the training data distribution (data drift).
- Monitor predictions for biased outcomes across subgroups (for example, by demographic attributes).
- Track feature attributions and model explainability signals to detect changes in what the model relies on.
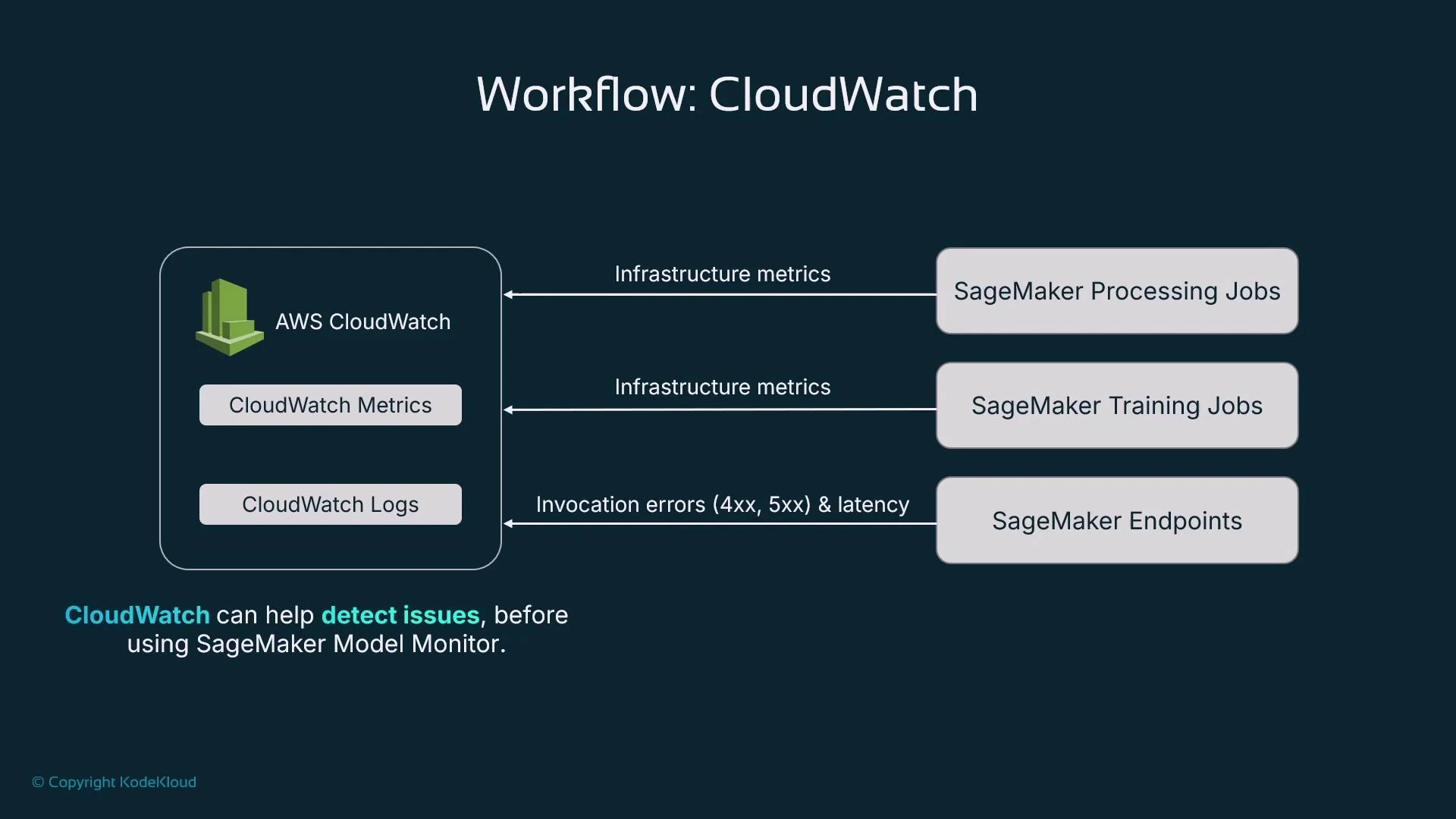
CloudWatch costs can be negligible in test/dev but grow in production. Many models, multiple instance types, autoscaling, and high throughput increase metrics and logs volume — estimate throughput and budget for CloudWatch metrics, custom metrics, and log ingestion/retention.
- The Metrics view displays time-series metrics emitted by AWS services in the selected region.
- Metrics are organized into namespaces such as /aws/sagemaker/TrainingJobs. Learn namespace and metric naming so you can filter and chart relevant signals.
- For SageMaker endpoints, training jobs, and processing jobs you can chart CPU, GPU, disk, invocation counts/errors, and latency. Use the UI to select metrics and zoom into time ranges for troubleshooting.
Example: viewing endpoint metrics (region-specific)
- Typical SageMaker endpoint metrics: CPUUtilization, MemoryUtilization (when available), InvocationCount, Invocation4XXErrors, Invocation5XXErrors, ModelLatency, and OverheadLatency.
- Select one or more metrics in the console to plot trends and spikes over different time ranges.
- CPUUtilization and GPUUtilization show whether the chosen instance type is appropriate. Very high GPU utilization may indicate a need for more GPUs or larger GPU instances.
- DiskUtilization can reveal I/O bottlenecks and suggest different storage or instance families.
- Note: memory utilization for some managed training jobs may not be available unless you install an agent or expose it explicitly.

- Monitor CPUUtilization, GPUUtilization (if applicable), and DiskUtilization to determine the best instance type and whether to use multiple instances.
- Track InstanceCount and throughput when a job is distributed to understand scalability and cost trade-offs.

- CloudWatch metrics for SageMaker endpoints help determine:
- Latency and whether it’s caused by the model (ModelLatency) or by system overhead (OverheadLatency).
- Traffic patterns for scaling decisions.
- Invocation errors (4xx indicate client-side issues, 5xx indicate server-side issues).
- Use ModelLatency to measure inference time inside the model container and OverheadLatency to quantify platform/network overhead.

- AWS services can push logs into CloudWatch Logs. Log groups contain log streams and events — filter to the groups you need (for example, search for “endpoint”).
- The CloudWatch log viewer displays each log event with a timestamp and supports filtering by text or pattern (e.g., error, timeout) and expanding structured fields.
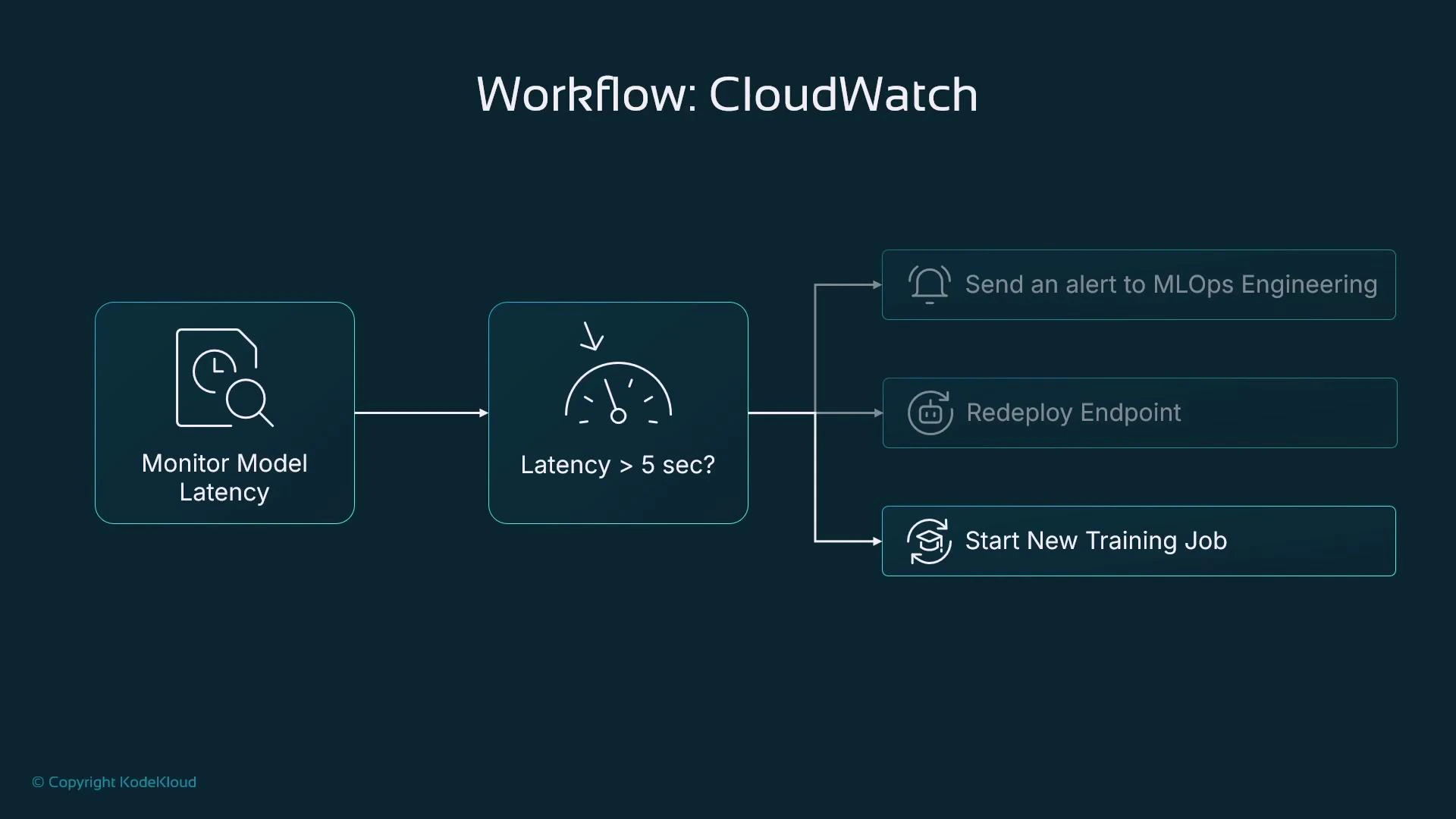
- Alarms allow you to define thresholds on metrics and take automated actions when those thresholds are crossed.
- Alarm actions can notify via SNS, invoke a Lambda, trigger a Step Function, or integrate with other automation for remediation.
- Monitor ModelLatency and create an alarm if latency > 5 seconds.
- Possible alarm actions:
- Notify the MLOps team (SNS email/SMS).
- Trigger an automated redeploy of the endpoint (via Lambda/Step Function).
- Kick off a retraining pipeline if drift or data-quality issues are detected.
- Use CloudWatch for infrastructure and platform signals (availability, latency, resource utilization) and SageMaker Model Monitor for model-level signals (data quality, drift, bias).
- Capture inference inputs and outputs with Model Monitor to enable automated data quality checks, drift detection, and bias detection pipelines.
- Combine metrics, logs, and model-monitoring signals to build a robust observability stack: use CloudWatch for alerting and automation; use Model Monitor for model performance and fairness insights.
- AWS CloudWatch
- SageMaker Model Monitor documentation (search “SageMaker Model Monitor” in AWS docs)
- Kubernetes Basics (for containerized workloads and sidecars)