Both the Boto3 and SageMaker SDK approaches create the same underlying AWS resources (an Endpoint and an Endpoint Configuration). Choose the SDK based on whether you need fine-grained control (Boto3) or faster, ML-focused development (SageMaker SDK).

Overview
Both SDKs ultimately produce the same SageMaker resources: an Endpoint Configuration and an Endpoint. The difference is how you get there:- Boto3 (low-level): explicitly create an Endpoint Configuration, then create the Endpoint that references it. Gives maximal control over the infra.
- SageMaker Python SDK (high-level): create a Model object and call its deploy method; the SDK generates the Endpoint Configuration and Endpoint for you. Faster to iterate for ML workloads.
Boto3: create an Endpoint Configuration
With Boto3 you first create an Endpoint Configuration that describes the serving infrastructure (instance type, initial instance count, the model to serve, and other parameters). The following example assumes a SageMaker Model named “linear-learner-model” already exists in your account:
Config ≠ Endpoint
Creating an Endpoint Configuration does not provision the actual serving endpoint. An Endpoint is a separate resource that references the Endpoint Configuration and must be created explicitly.
Boto3: create the Endpoint
After the Endpoint Configuration exists, create the Endpoint and point it at that config:Invoke a SageMaker Endpoint with Boto3 Runtime
To send prediction requests to a deployed endpoint using Boto3, use the SageMaker Runtime client (sagemaker-runtime) and its invoke_endpoint method. Ensure the payload and ContentType header match your model’s expected serialization: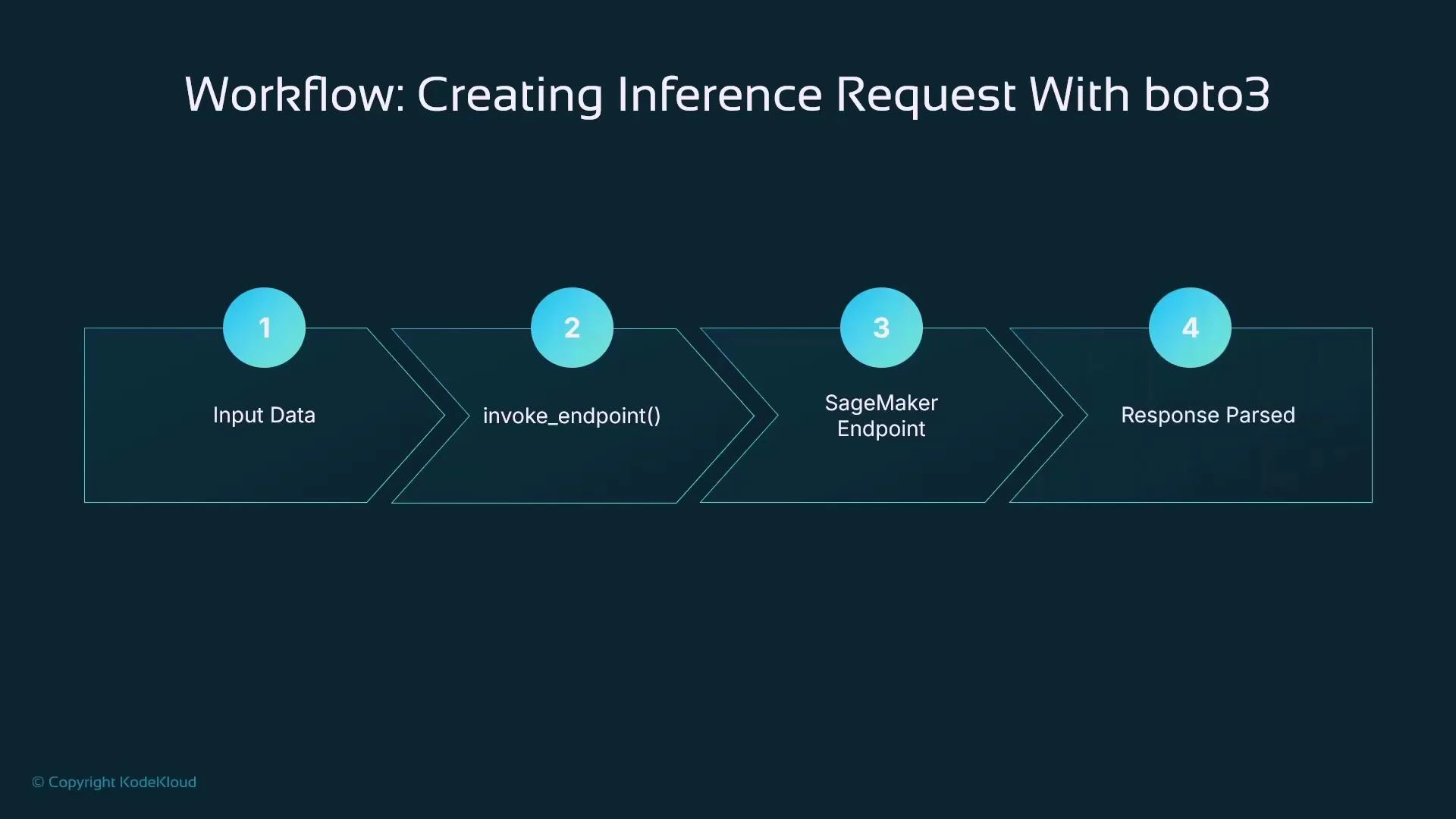
SageMaker Python SDK: Model.deploy (higher-level)
The SageMaker Python SDK provides an ML-focused abstraction. Instead of manually creating an Endpoint Configuration, you define a Model object and call deploy; the SDK creates the Endpoint Configuration and Endpoint for you. This reduces boilerplate and lets you focus on model code and iteration.
Example: create a Model and deploy it (SageMaker SDK)
This example shows how to use the SageMaker SDK to create a Model pointing to a model artifact in S3 and an inference container image, then deploy it as an endpoint.Mixed approach: custom infra with Boto3, inference with SageMaker SDK
If you need a custom Endpoint Configuration the SageMaker SDK cannot express, combine the two approaches: create the configuration and endpoint with Boto3, then use the SageMaker SDK’s Predictor to call that existing endpoint for ergonomic inference code: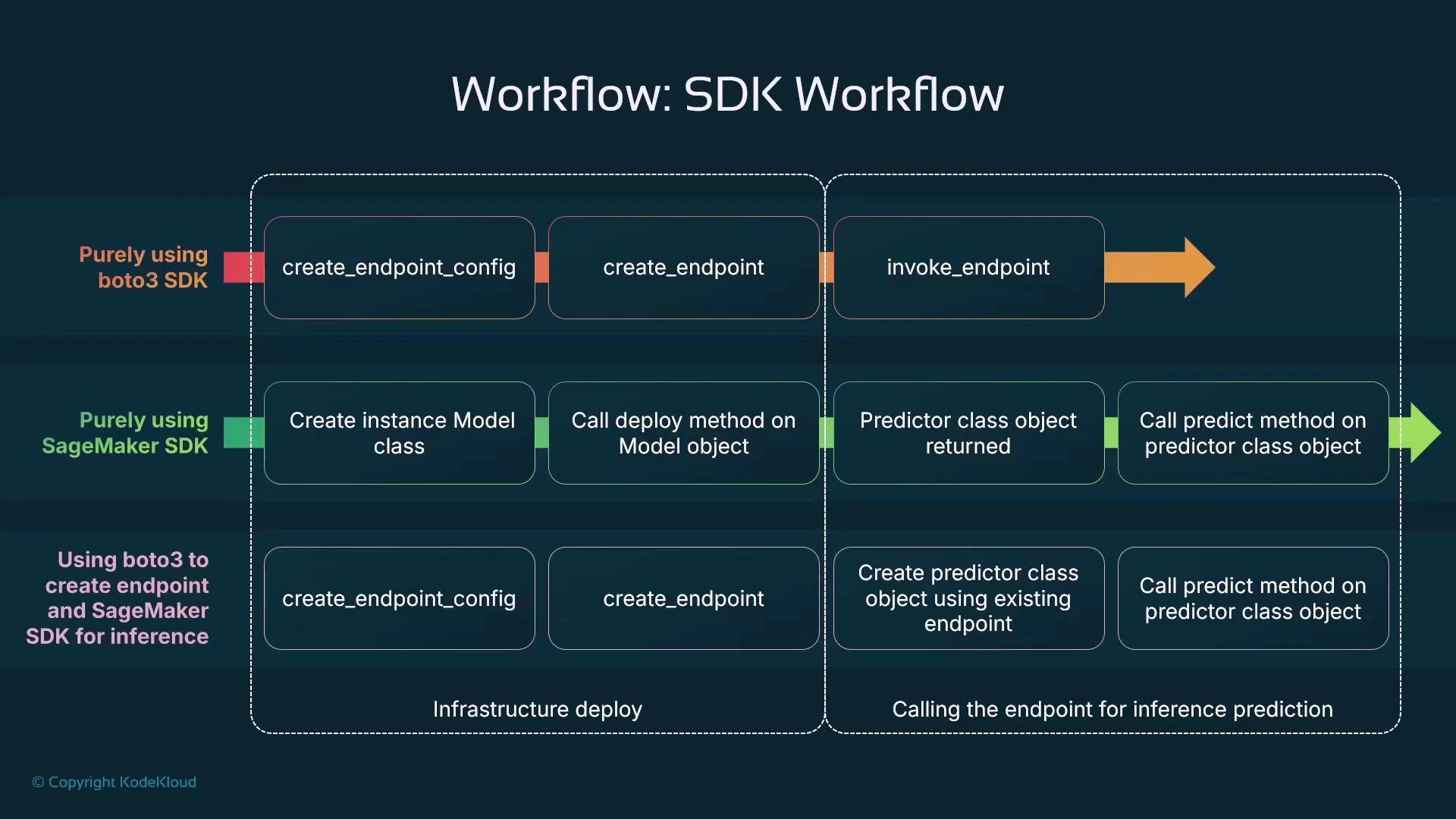
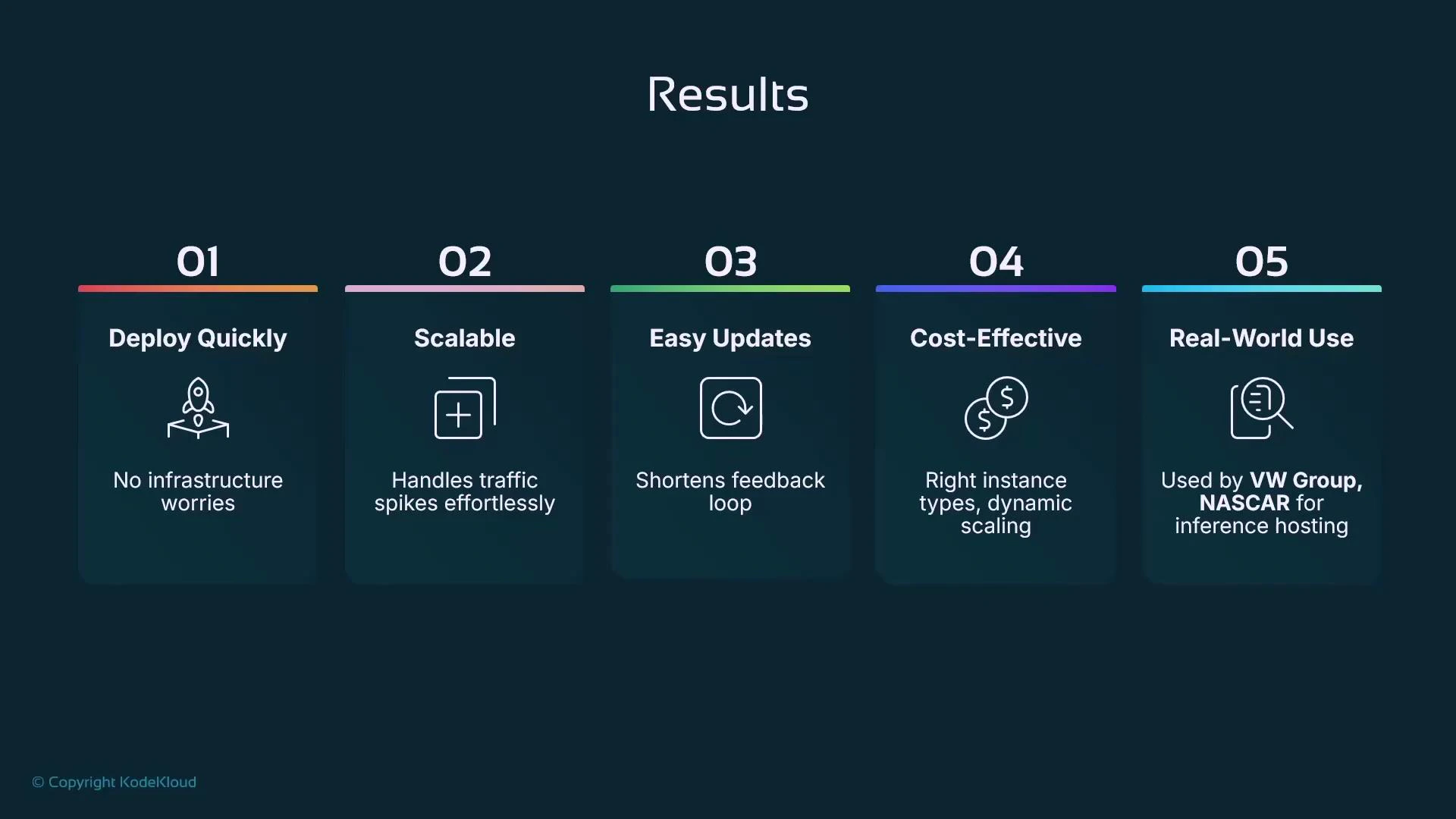
Why use SageMaker Endpoints?
SageMaker Endpoints are the native, managed option for real-time inference. Key benefits:- Deploy quickly: minimal infra code required to go from a trained model to a hosted endpoint.
- Scalable: integrates with autoscaling to handle traffic spikes and variable load.
- Easy updates: supports multiple production variants, enabling canary, blue-green, and A/B testing.
- Cost control: right-size instances and use autoscaling to reduce hosting costs.
- Production-ready: built for enterprise workloads and integrated with AWS monitoring and security.
Running real-time endpoints incurs compute and networking costs while the instances are provisioned. Use autoscaling, smaller instance types for development, or alternatives (asynchronous/batch inference) when strict real-time latency is not required.
Key takeaways
- Amazon SageMaker Endpoints provide managed hosting for real-time inference and can be created via Boto3 (fine-grained control) or the SageMaker Python SDK (higher-level abstraction).
- With Boto3: create an Endpoint Configuration, then create an Endpoint, and invoke it via the sagemaker-runtime client.
- With the SageMaker SDK: create a Model object and call deploy; the SDK creates the Endpoint Configuration and Endpoint for you, returning a Predictor that simplifies inference calls.
- You can mix approaches: use Boto3 to provision custom infra and the SageMaker SDK Predictor for ergonomics when invoking the endpoint.
- Consider alternatives (asynchronous inference, batch transform) for workloads that do not require low-latency, always-on endpoints.

Further reading and references
- Boto3 SageMaker client documentation: https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html
- SageMaker Python SDK docs: https://sagemaker.readthedocs.io/en/stable/
- SageMaker real-time endpoints overview: https://docs.aws.amazon.com/sagemaker/latest/dg/realtime-endpoints.html
- SageMaker Studio: https://docs.aws.amazon.com/sagemaker/latest/dg/studio.html