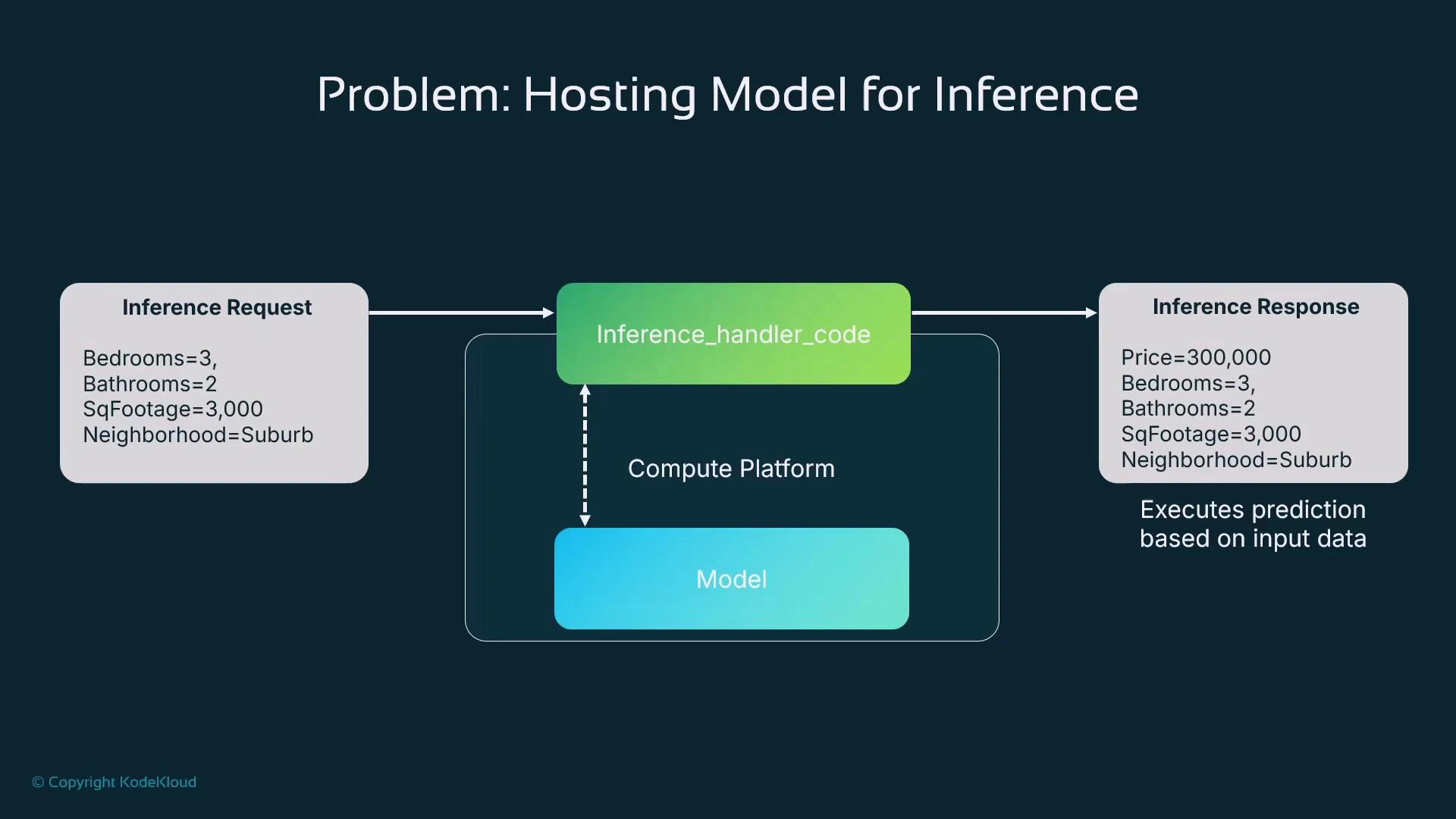
- Compute to run the model (VM, container, or managed instance).
- An inference handler: code that accepts requests, pre-processes input, calls the model, then post-processes output.
- A transport layer for clients to access the handler (HTTP API, message queue, batch jobs, etc.).

If you are new to ML production on AWS, start with a SageMaker Endpoint to minimize infrastructure work and get predictable, low-latency inference quickly.
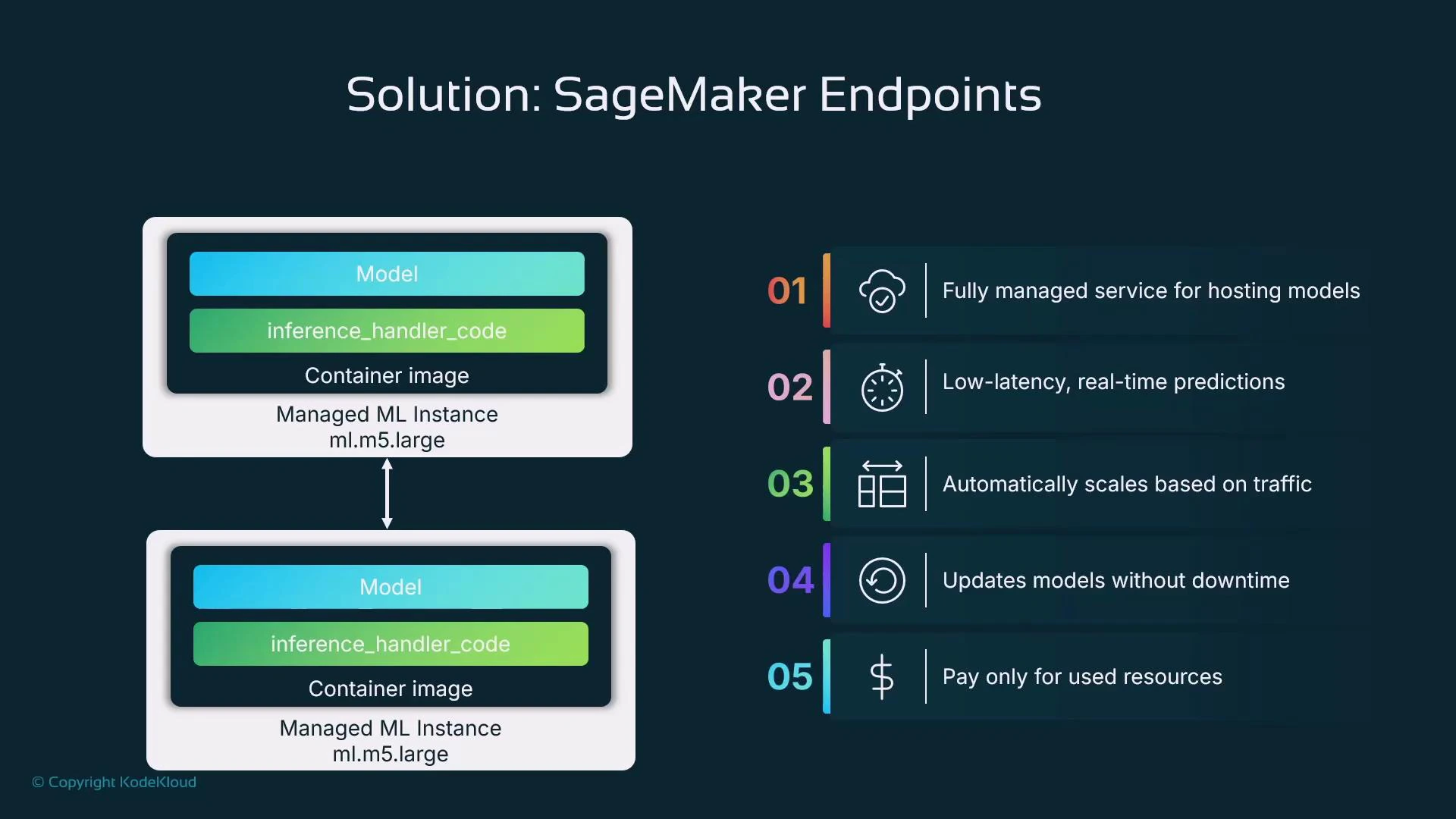
- Fully managed hosting: SageMaker provisions instances and containers and manages lifecycle, OS, and patching.
- Low-latency, real-time predictions for synchronous workflows (e.g., fraud detection, personalization).
- Autoscaling: scale instance count automatically in response to traffic.
- Safe updates: built-in mechanisms to roll out new model versions (supporting blue/green, canary, or A/B strategies).
- Flexible pricing: pay-as-you-go for instances; use serverless/async/batch options for cost-efficient non-real-time use cases.
- Real-time endpoints: synchronous, low-latency responses with instance-backed hosting.
- Serverless inference: run model code without provisioning instances (good for low or spiky traffic).
- Asynchronous endpoints: submit requests and retrieve results later (useful for long-running or variable-latency inference).
- Batch Transform jobs: high-throughput offline inference over large datasets.
- Multi-Model Endpoints (MME): host many small models on the same endpoint and load them on-demand to reduce cost.
- Choose instance type and initial count (e.g., ml.m5.large) based on latency and memory/CPU requirements.
- Use SageMaker autoscaling to adjust instance count to traffic.
- For workloads that are infrequent or bursty, evaluate serverless or asynchronous endpoints to avoid always-on instance costs.
- SageMaker supports programmatic endpoint updates for rolling new model versions into production.
- Typical flow: create a new model resource (pointing to the new model artifact and container), create a new endpoint configuration, then call UpdateEndpoint to switch traffic.
- This supports deployment strategies used in DevOps: canary releases, blue/green swaps, and A/B tests.
- Steps:
- Create a Model resource that references your model artifact and container image.
- Create an Endpoint Configuration specifying instance type and count.
- Create the Endpoint from that configuration.
- To deploy a new model, create a new Model + Endpoint Configuration and call UpdateEndpoint.
Be mindful of costs: real-time endpoints incur charges while instances are running. For low-traffic or batch workloads, evaluate serverless, async, or Batch Transform to reduce costs.
- Match hosting to requirements: latency, throughput, availability, cost, and operational capacity.
- Start simple with SageMaker Endpoints for predictable, low-latency inference on AWS; evolve to serverless or async patterns when appropriate.
- Design for model updates and automated deployment from the start — models drift and will require retraining and rotation into production.
- Monitor model performance, latency, and cost after deployment; automate rollback or traffic-shifting when necessary.
- AWS SageMaker Endpoints documentation: https://docs.aws.amazon.com/sagemaker/latest/dg/ex endpoints.html
- SageMaker Python SDK: https://sagemaker.readthedocs.io/
- boto3 SageMaker client: https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html
- Kubernetes and container orchestration: https://kubernetes.io/docs/home/