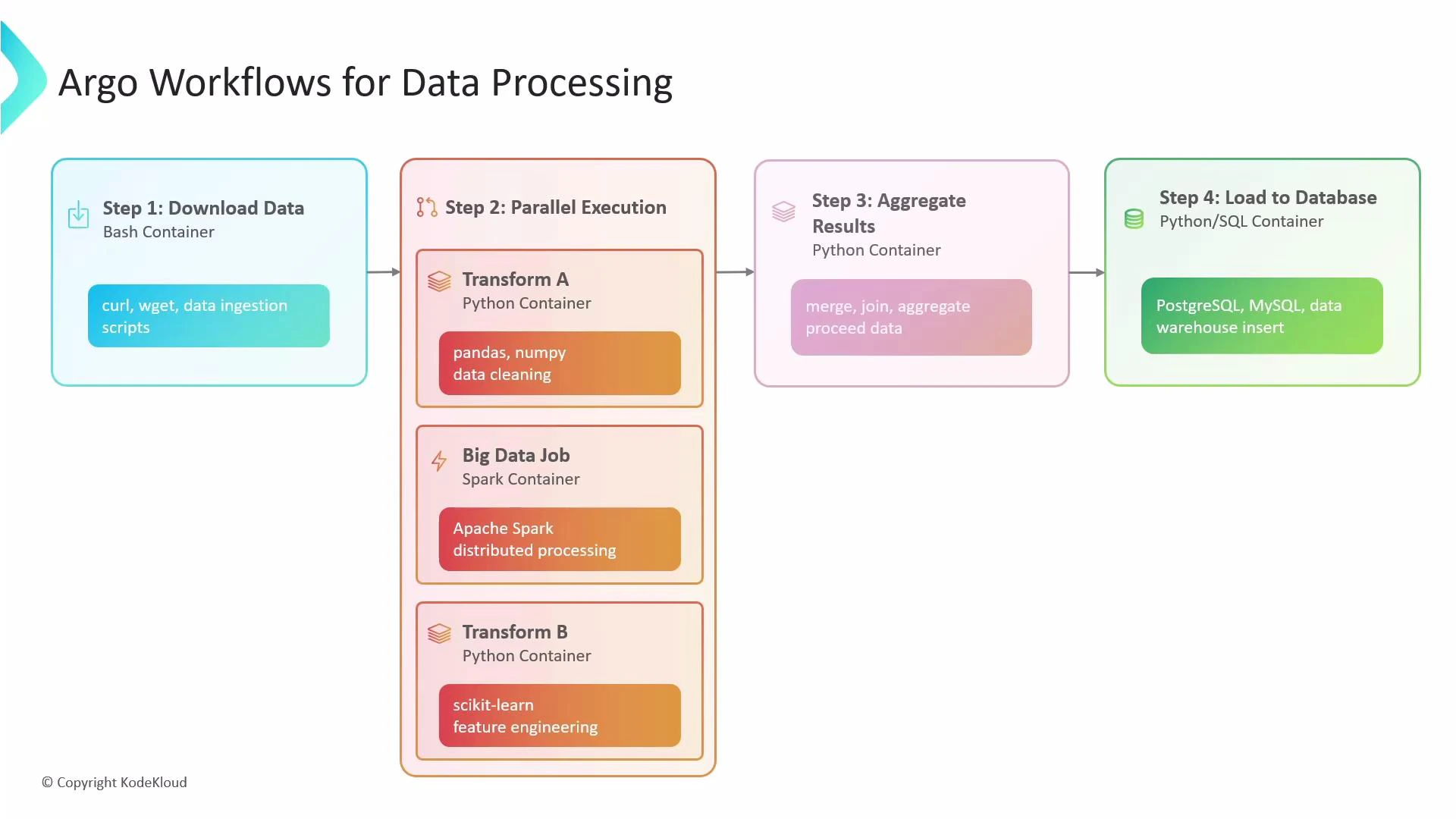
- Ingest data (e.g., curl/wget in a small container).
- Fan out to multiple transformers in parallel (Python for cleaning, Spark for heavy processing, Python for feature engineering).
- Merge parallel outputs into one dataset.
- Aggregate results and load into a SQL database (PostgreSQL/MySQL).
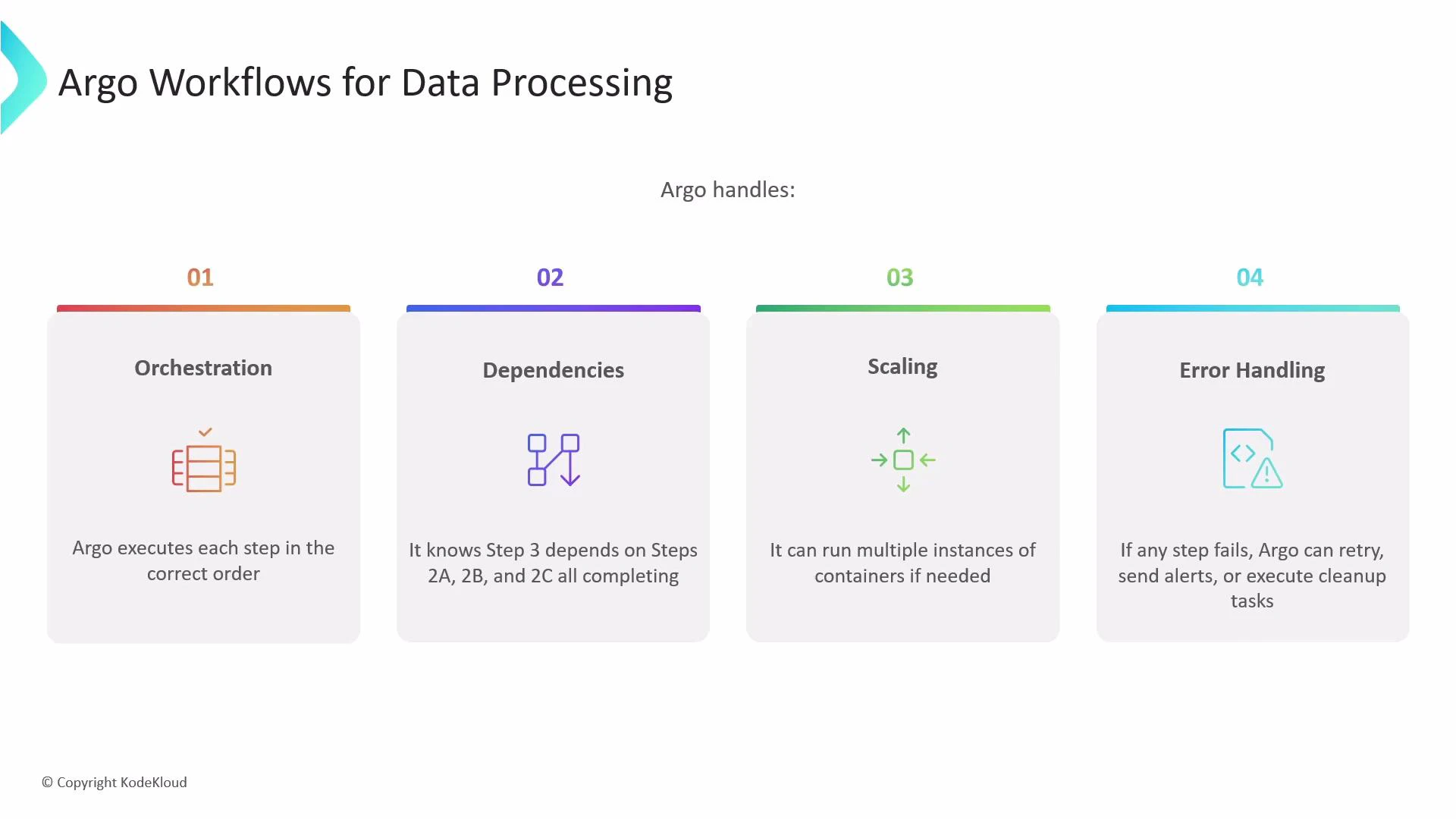
What Argo does behind the scenes
Argo Workflows orchestrates execution of containerized tasks according to your workflow definition. It:- Executes tasks in the order you define.
- Tracks and enforces dependencies (e.g., a merge step waits for all transformers).
- Scales by running multiple container instances in parallel.
- Handles failures with retries, alerts, and cleanup options.
Note: Argo Workflows is the Argo project focused on running containerized workflows. Argo CD is a separate Argo project that provides GitOps for Kubernetes deployments (see GitOps with ArgoCD). This article focuses on Argo Workflows for pipeline orchestration.
Key features at a glance
withItems: parallel fan-out for batch processing
withItems lets you fan out over a static list (file names, table names, endpoints) and run multiple instances of a template — effectively a for-each loop that executes in parallel by default. How it works: given items A, B, and C, Argo creates three independent instances of the referenced template (three pods). Each instance receives its item value via the placeholder. Example: process multiple files in parallel This workflow demonstrates a top-level template that fans out over S3 file paths and invokes a processing template for each item.- Use inside the referenced template to access the value.
- Each withItems iteration starts a separate pod (unless limited by parallelism).
Controlling concurrency with parallelism
Uncontrolled parallelism can overload cluster resources or downstream systems (databases, APIs). Use the workflow-level spec.parallelism field to throttle how many tasks run concurrently across the entire workflow. Example: limit the cosmic loop to 2 concurrent podsWarning: Setting parallelism too high can exhaust node CPU/memory or overwhelm downstream services. Use resource requests/limits on containers and test with smaller parallelism before scaling up.
Best practices for data processing pipelines
- Use small, focused containers for each step (single responsibility).
- Define resource requests and limits for heavy workloads (Spark, large Python jobs).
- Use artifact storage (S3/GCS) or persistent volumes to pass large data between steps instead of base64-encoded outputs.
- Use retry/backoff strategies and timeouts for unreliable external systems.
- Monitor and log at each step; consider sidecar log aggregators or central observability.