Key capabilities
Argo Workflows provides a rich set of features for running container-native workloads on Kubernetes:- Declarative workflow definitions: author workflows with YAML manifests that describe steps, DAGs, templates, and inputs/outputs.
- Control-flow primitives: built-in support for conditional execution, loops, fan-in/fan-out, and parallel steps.
- Reusability & parameterization: define reusable WorkflowTemplate and ClusterWorkflowTemplate objects and pass parameters between templates.
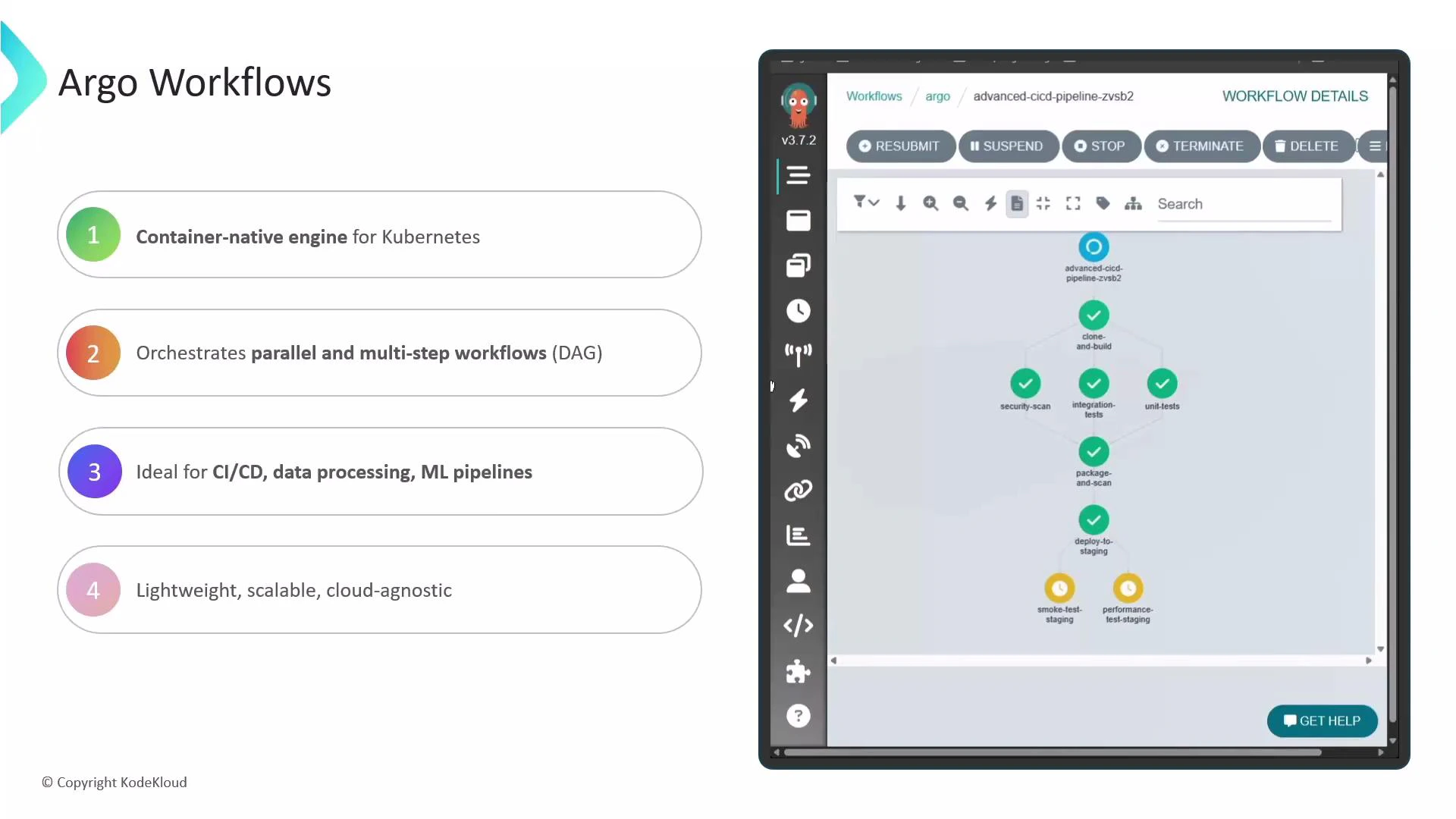
- Visualization & observability: the Argo Server UI visualizes DAGs, provides per-step logs, and shows execution state for debugging.
- Execution control: timeouts, suspend/resume, retries, and backoff policies to control runtime behavior.
- Data passing and artifacts: first-class artifact support (S3, GCS, HTTP, and more) plus parameters and outputs for step-to-step data transfer.
- Concurrency & resource management: configure parallelism at workflow, template, and step levels to guard resource consumption.
- Long-running services: sidecars and daemon steps let you run background services alongside workflow steps.
- SDKs & clients: official Go and Python SDKs (and community SDKs for other languages) enable programmatic workflow control.
- Exit handlers & cleanup: onExit handlers, TTL strategies, and garbage-collection options help automate cleanup and teardown.
Minimal declarative example
Below is a minimal Argo Workflow YAML that demonstrates the declarative style and a simple sequence of steps. Save this to a file (e.g., minimal-workflow.yaml) and submit it withargo submit when you have an Argo controller running.
Feature summary (quick reference)
When to choose Argo Workflows
- You need Kubernetes-native orchestration with fine-grained control over containers and resources.
- Your workloads require parallelism, complex DAGs, or passing artifacts between steps.
- You want UI-based visualization of pipeline execution and per-step logs.
- You prefer declarative YAML workflow definitions that integrate with GitOps and CI/CD tooling.
Argo runs natively on Kubernetes, so you’ll need a Kubernetes cluster (local or cloud) to run workflows and to use the Argo Server / UI for visualization and control.
Links and references
- Official Argo Workflows docs: https://argoproj.github.io/argo-workflows/
- Kubernetes documentation: https://kubernetes.io/docs/
- Argo GitHub repository: https://github.com/argoproj/argo-workflows
- Argo Python SDK: https://github.com/argoproj-labs/argo-python-sdk