- The generate step creates
/tmp/hello.txtand declares it as an output artifact. - The consume step accepts that artifact as an input artifact (passed via
arguments) and prints its contents. - The templates run in sequence:
generatefinishes first, thenconsumeruns and receives the artifact produced bygenerate.
Use standard temporary paths such as /tmp inside container scripts to avoid confusion. This example uses /tmp consistently for both producer and consumer.
How artifacts are stored (MinIO and default compression)
When the
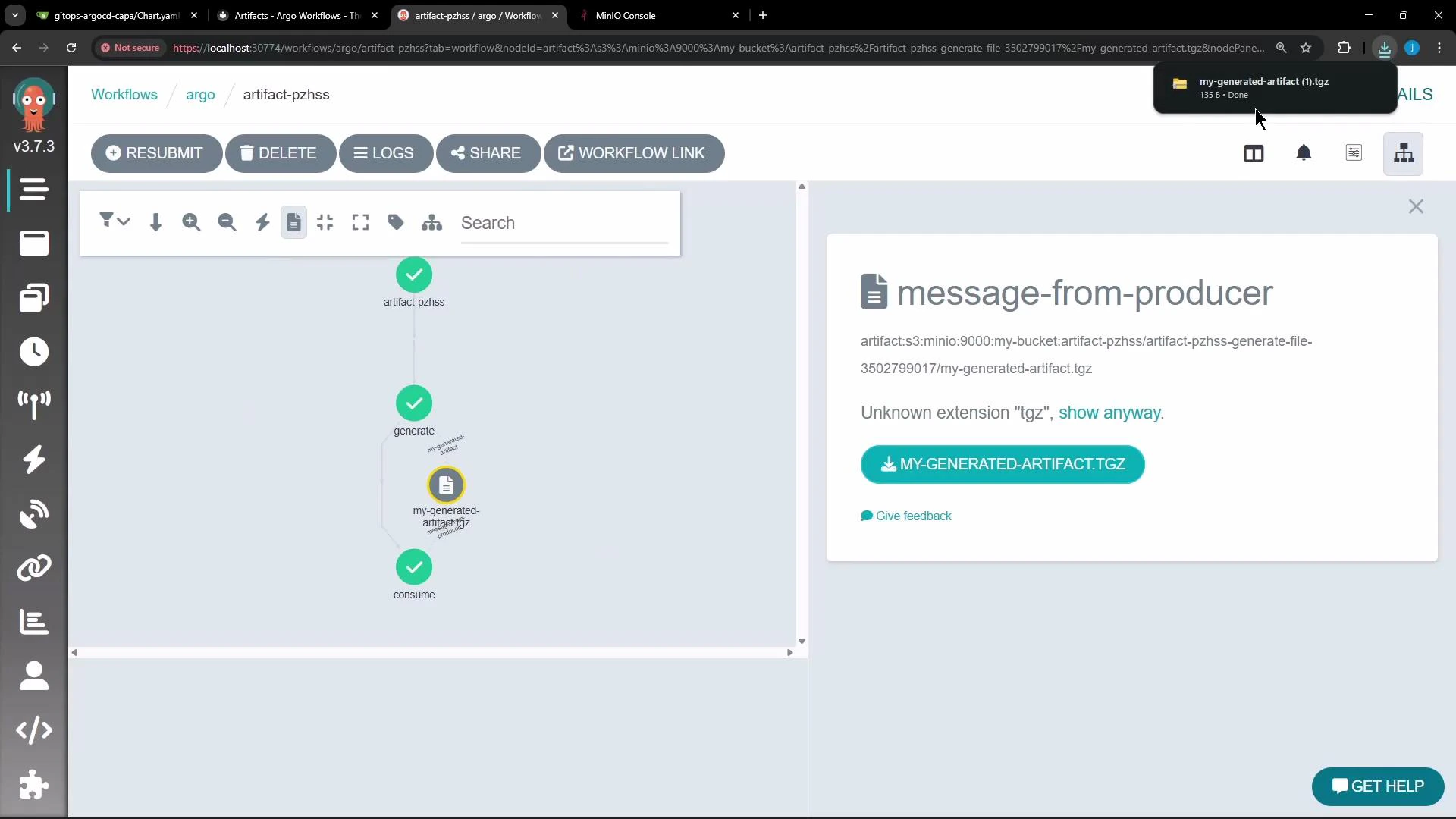
generate step completes, Argo uploads the artifact to the configured artifact repository (MinIO in this demo). By default Argo archives artifacts as a tar + gzip, so objects stored in MinIO often appear as compressed tarballs (for example, .tgz or .tar.gz). You can download these archived artifacts from the MinIO console or the Argo Workflows UI.
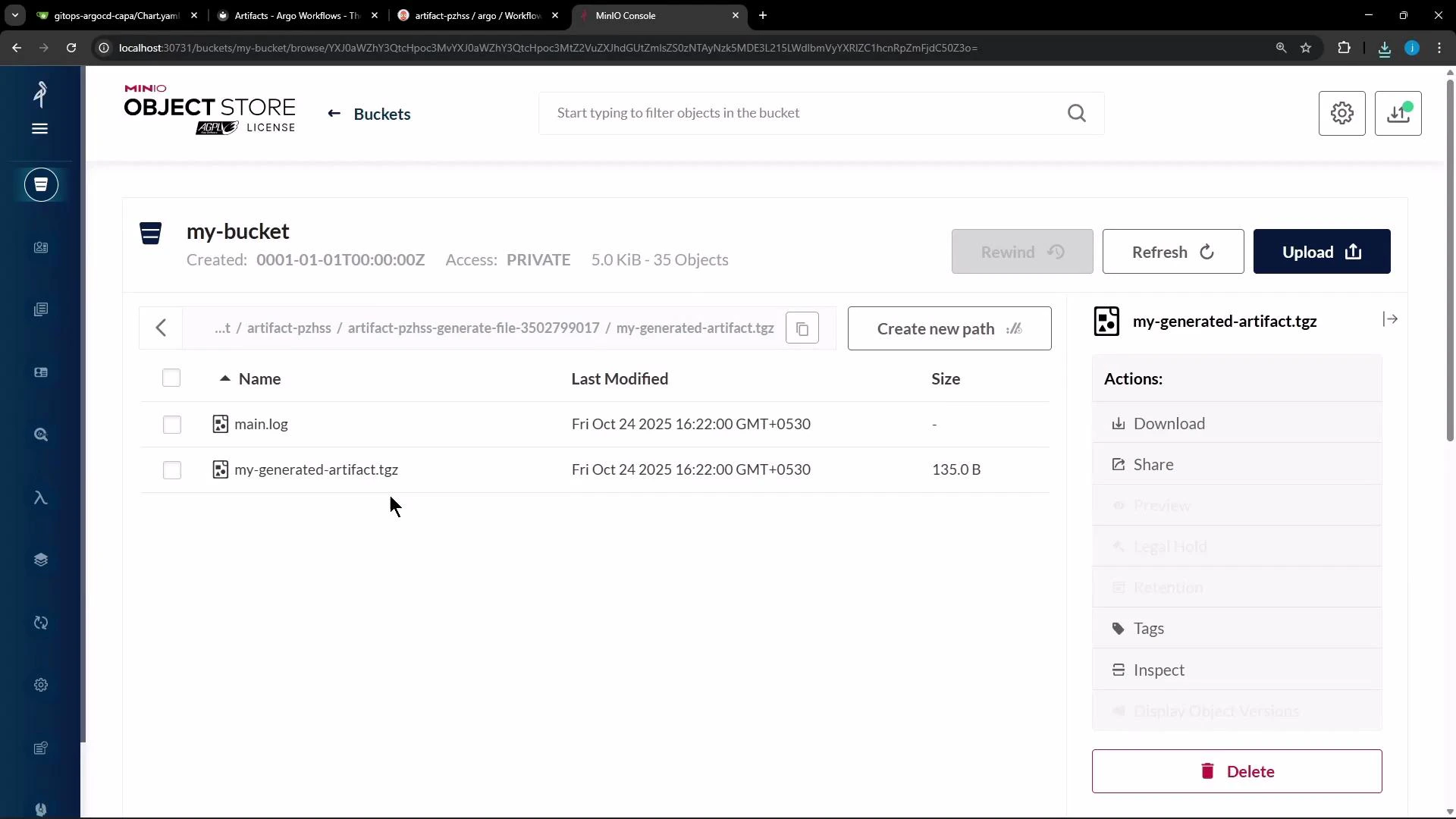
Example configuration snippets for outputs.artifacts
- Use
archive: nonewhen the consumer must see the exact file/directory structure your container produced (for caching or large build outputs). - Use
tarwith acompressionLevelwhen you need to tune upload size vs CPU cost. For textual logs, higher compression helps; for already-compressed binaries, consider lower compression or disabling it.
generatecompletes and Argo uploads/tmp/hello.txtto the artifact repository as a tar+gzip by default (e.g.,my-generated-artifact.tgz).- The
consumestep is scheduled; Argo downloads the artifact, materializes it at/tmp/message.txtinside the consumer container, and the consumer prints: