- What a data source is and when to use it
- How to author data source blocks
- How to reference attributes returned by data sources in other resources
- Avoid hard-coding provider-specific IDs (VPC IDs, ARNs, resource group names).
- Resolve dependencies on existing infrastructure that Terraform does not manage.
- Make modules and configurations reusable across environments.
- VMware/VMware vSphere: Query datacenters, clusters, resource pools, and datastores before deploying VMs.
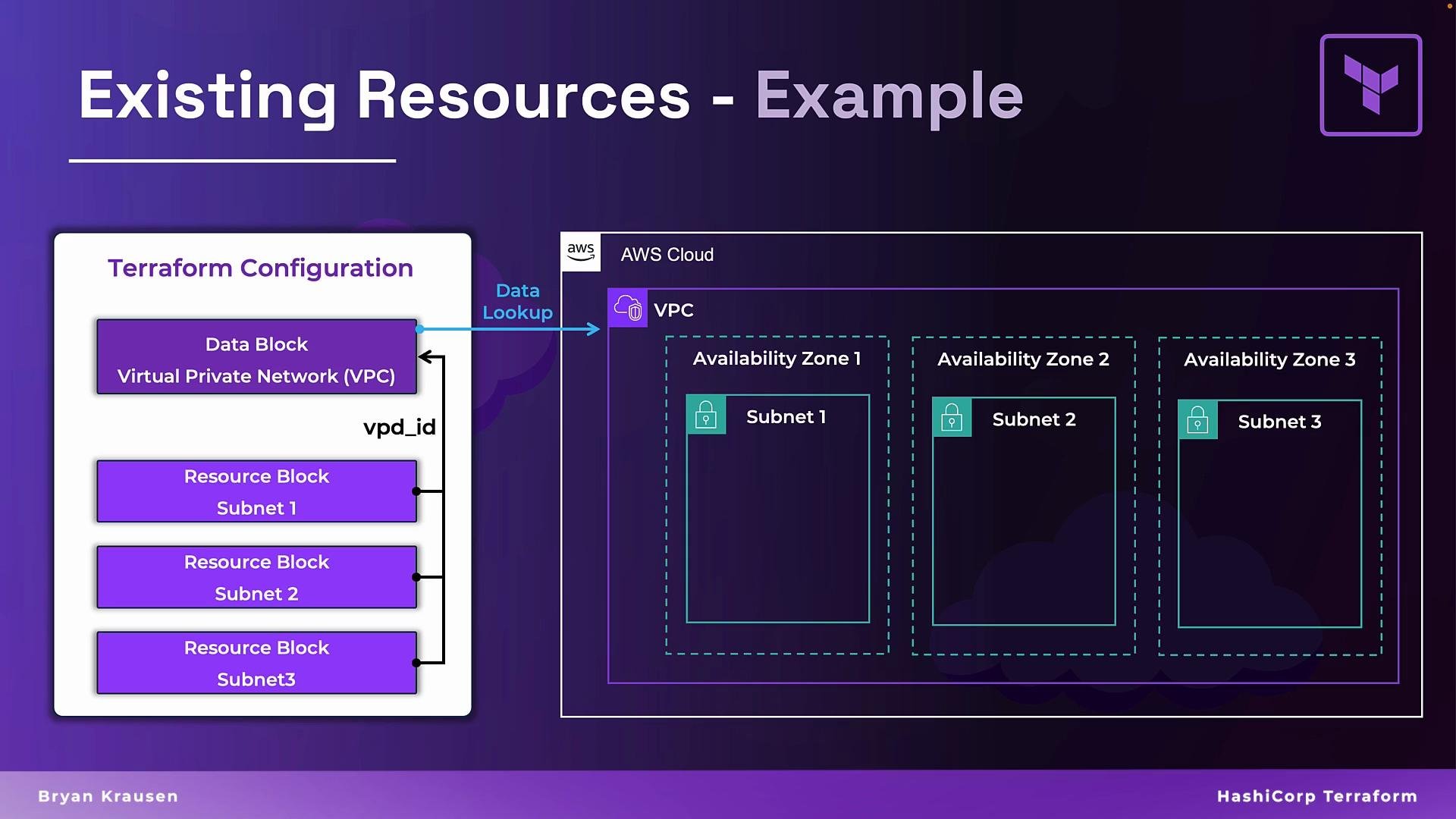
- AWS: Look up a VPC by tag or name to get its ID for subnet or route table creation.
- Kubernetes: Query an existing namespace or service account to attach resources to it.
terraform plan and terraform apply. Terraform queries the provider API in real time to populate data source attributes, so you avoid hard-coded IDs, ARNs, or other brittle values.
Key points about data sources
Data sources let Terraform read existing objects (resources, accounts, namespaces, etc.) and expose their attributes for use elsewhere in your configuration. They are read-only and will not create or change provider-side resources.

data keyword and two labels, similar to how resource blocks are structured:
- First label: the provider-specific type (for example,
aws_vpc,azurerm_resource_group,kubernetes_namespace) - Second label: your local name (a descriptive identifier, such as
prd,dev,app)
data.<TYPE>.<NAME>.<ATTRIBUTE>
data— indicates a data source<TYPE>— the data source type (e.g.,aws_vpc)<NAME>— your local data source name (e.g.,prd)<ATTRIBUTE>— the attribute you want (e.g.,id,cidr_block,arn)
data.aws_vpc.prd:
- VPC ID:
data.aws_vpc.prd.id - CIDR block:
data.aws_vpc.prd.cidr_block - ARN:
data.aws_vpc.prd.arn - Owner account:
data.aws_vpc.prd.owner_id
- Use filters or explicit names in data sources to reduce accidental matches.
- Prefer data sources in modules when the module must integrate with already existing infrastructure.
- Be mindful of provider API rate limits: data sources are called during plan and apply.
- If attributes change outside Terraform, re-running
terraform planwill reflect the new values (depending on provider behavior).
- Data sources are read-only constructs that let you query existing infrastructure and expose attributes to your Terraform configuration.
- Use data sources to avoid hard-coded IDs and to resolve dependencies on existing resources.
- Each provider documents supported arguments and returned attributes in the Terraform Registry — check it for the exact schema.
- Terraform Registry: https://registry.terraform.io/
- AWS Provider documentation: https://registry.terraform.io/providers/hashicorp/aws/latest/docs
- AzureRM Provider documentation: https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs
- Kubernetes Provider documentation: https://registry.terraform.io/providers/hashicorp/kubernetes/latest/docs