- Core capabilities of Azure AI Vision (object detection, OCR, captioning, etc.)
- Typical real-world use cases and deployment considerations
- What the service returns and a sample response
- Practical next steps and links to documentation
- Scan images: Analyze an image to determine whether it contains people, vehicles, animals, and other object categories.
- Identify objects: Detect and localize specific items (for example, products on a retail shelf).
- Read text (OCR): Extract printed or handwritten text from images, such as invoices, receipts, or street signs.
- Detect emotions: Analyze faces to infer expressions and basic affective signals for user-experience research.

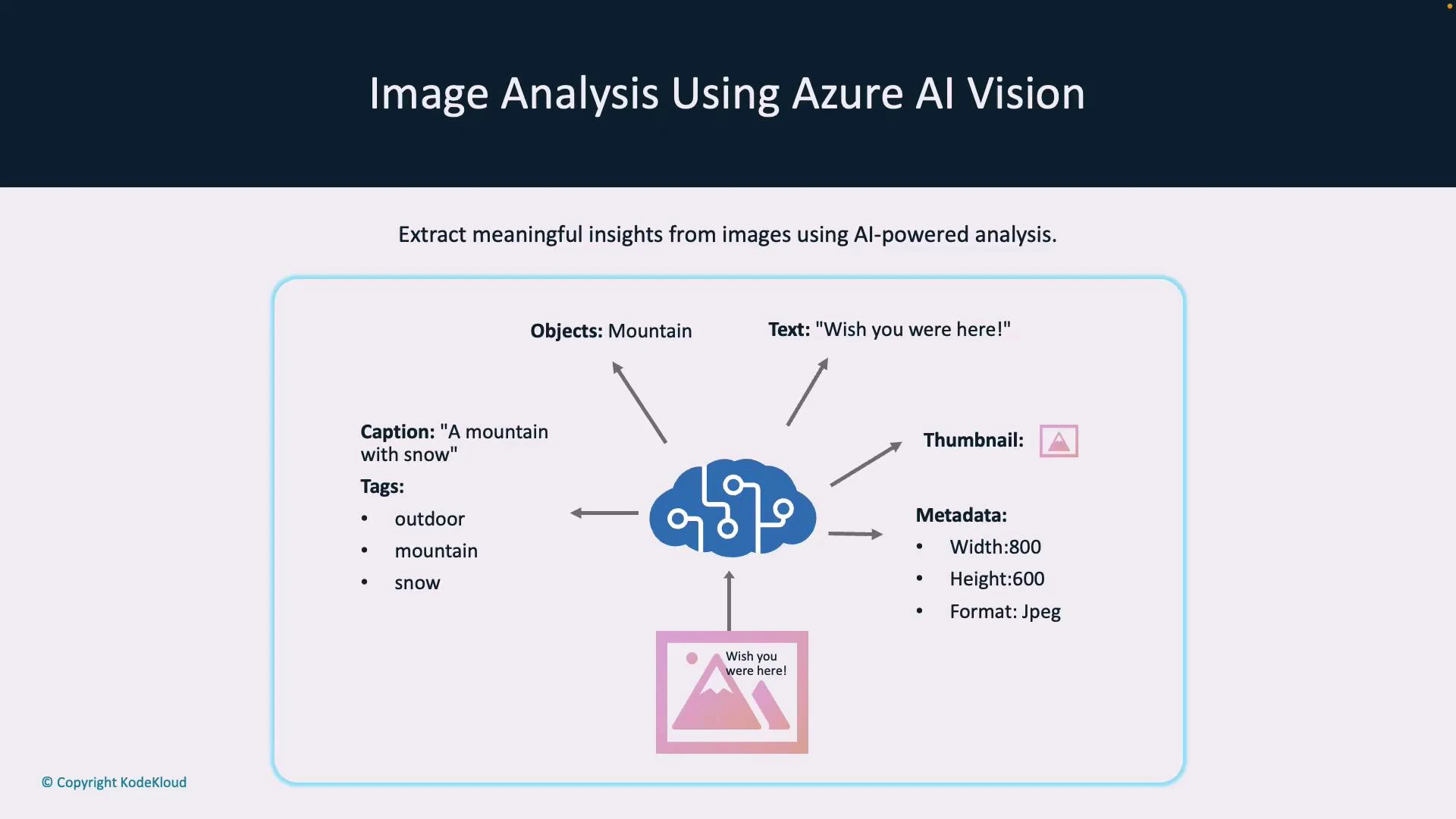
- Caption: A short human-readable description (e.g., “a mountain with snow”).
- Tags: Keyword labels that describe image content (e.g.,
outdoor,mountain,snow). - Detected text: OCR’d strings found in the image (printed or handwritten).
- Objects & bounding boxes: Coordinates and classes for detected items.
- Smart thumbnail: A cropped image centered on the main subject.
- Metadata: Image properties such as width, height, and format.
- Caption & tag generation: Produce concise descriptions and keywords to improve search, filtering, and accessibility.
- Object detection: Locate and classify objects for inventory, traffic analytics, or counting.
- People detection: Detect persons and bounding boxes for crowd analysis, privacy-preserving blur, and access logs.
- Optical Character Recognition (OCR): Extract printed and handwritten text for data entry automation and document processing.
- Smart thumbnails: Automatically crop images to focus on the primary subject (improves visual presentation in galleries).
- Multimodal embeddings: Generate vector embeddings that combine visual and textual context for semantic search and image-text matching.
Check region and SKU availability for advanced features. Use the Azure portal or the Azure AI Services documentation to verify which features are available in your target region and which deployment options (cloud, private preview, or specialized SKUs) apply.
- Try a quickstart: Use the REST API or an SDK (Python, C#, JavaScript) to submit images and inspect responses.
- Review authentication and pricing: Understand keys, endpoint configuration, and cost/latency trade-offs.
- Tune for accuracy: Experiment with image resolution, pre-processing, and post-processing filters for better results.
- Explore advanced features: Look into multimodal embeddings for semantic search and hybrid workflows.
- Azure AI Services docs: https://learn.microsoft.com/azure/ai-services/
- Azure portal: https://portal.azure.com
- Azure AI Vision quickstarts and SDKs: https://learn.microsoft.com/azure/ai-services/vision/overview