- Persist enrichment outputs (entities, key phrases, pages, images) to storage for auditing, downstream ETL, or analytics.
- Turn unstructured content into structured, queryable artifacts (JSON objects, relational tables, or files).
- Keep search index data and persisted enrichment artifacts separate and optimized for different use cases.
knowledgeStore block that defines where and how to persist the results. Projections describe the output format and destination:
- objects — JSON blobs written to blob storage
- tables — relational rows written to Azure Tables
- files — binary or large artifacts written back to blob storage
- Save enrichment output as structured JSON objects in a blob container.
- Common use cases: storing entire enriched documents or structured metadata for downstream processing.
- Create relational tables that are queryable with SQL-like patterns (via Azure Tables).
- Useful for aggregations, joins, or building dashboards (e.g., documents, pages, or key phrases).
- Persist binary or large extracted content (e.g., OCR output images, processed images, or large text blobs) back into blob storage.
- Good for assets that are better stored as files rather than table rows or JSON objects.
Knowledge store inside the skillset
Include a
knowledgeStore block in your skillset JSON to configure the destination storage and any projections. The block contains the storage connection and an array of projections that describe objects, tables, or files to persist.
Example knowledgeStore block:
Storage connection strings must be in one of the accepted formats:
- Full storage access: “DefaultEndpointsProtocol=https;AccountName=[your account name];AccountKey=[your account key];”
- SAS token: “BlobEndpoint=[your account endpoint];SharedAccessSignature=[your sas token]”
- If your search service uses Managed Identity, you can use: “ResourceId=[your resource id];”
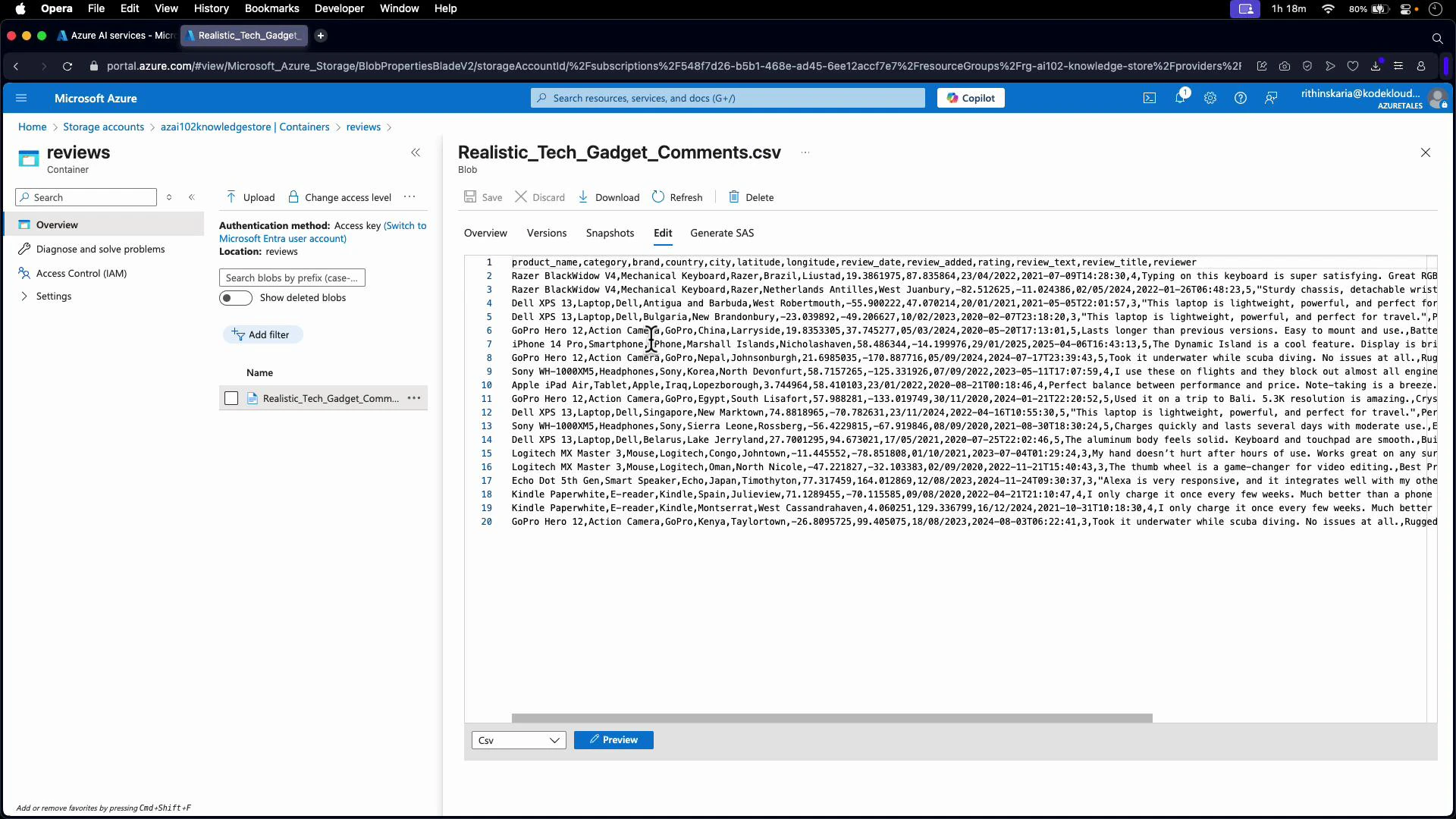
- Data source name: e.g., “reviews data source”
- Data to extract: Content and metadata
- Parsing mode: Delimited text
- Delimiter: comma (or other if needed)
- If the first CSV row contains headers, enable the “first line contains headers” option so fields map correctly
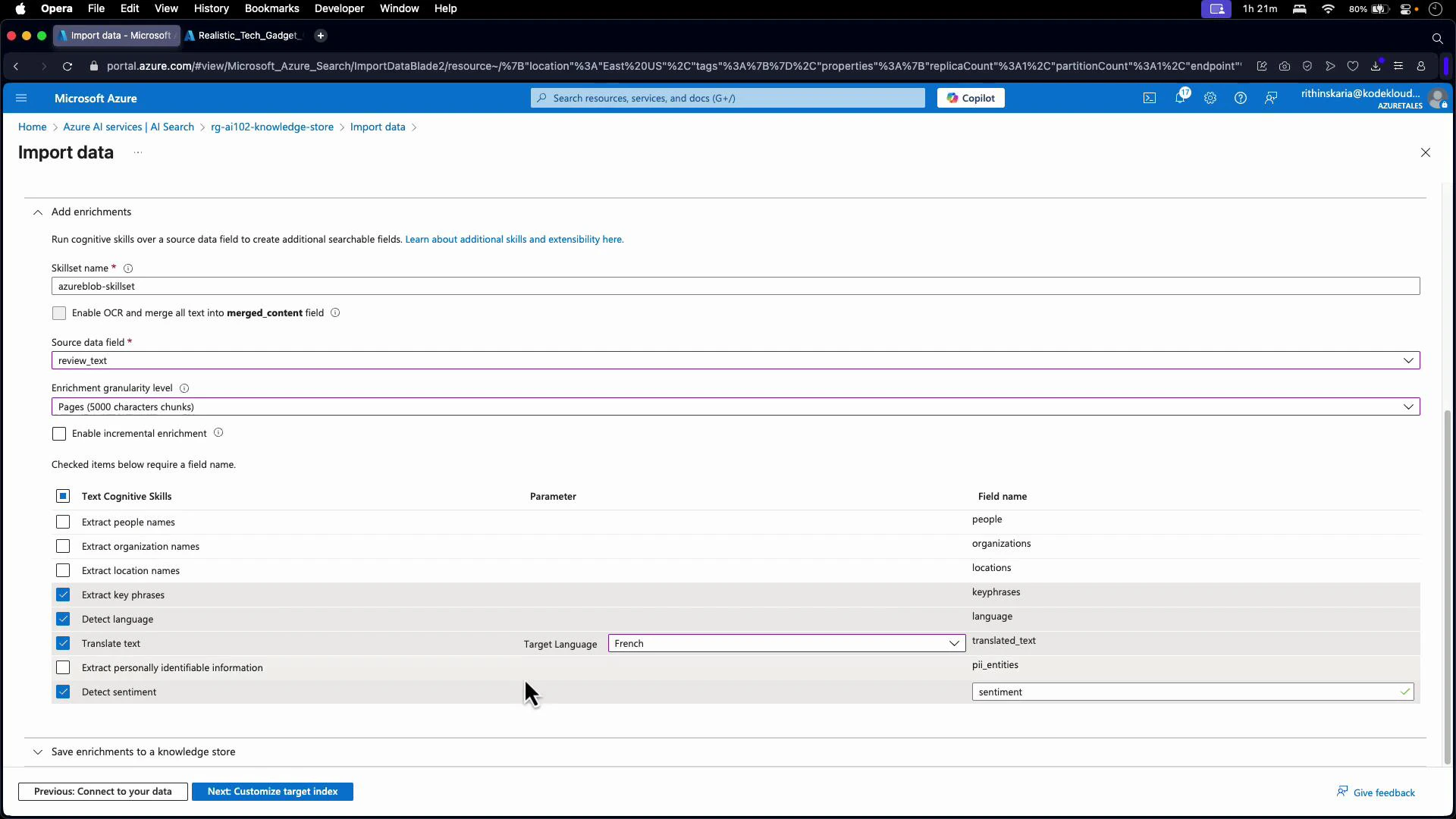
review_text):
- Detect language
- Extract key phrases
- Translate text (if you need translated outputs)
- Detect sentiment
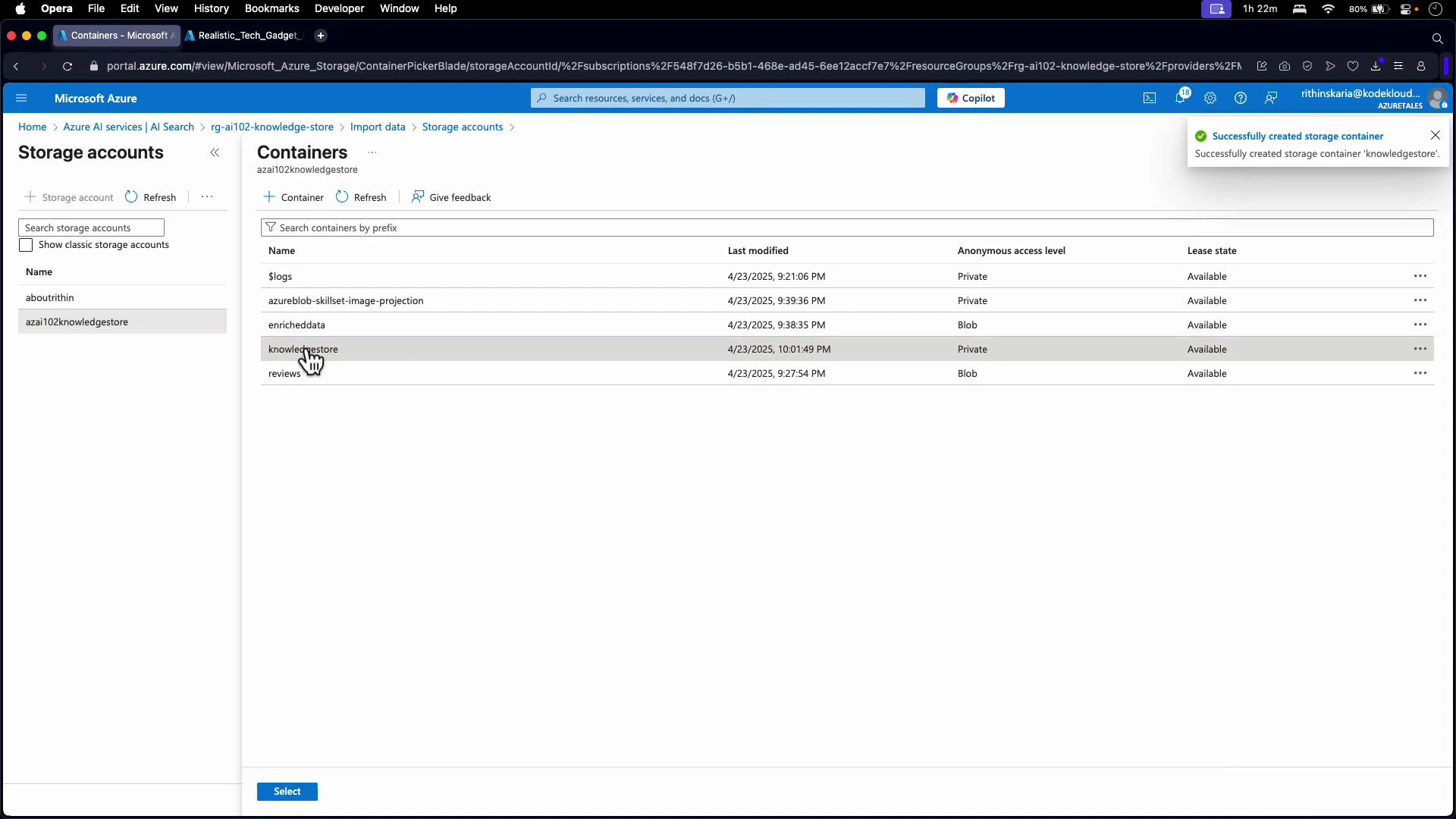
- Select or create the destination storage account and container (for example, a container named “knowledgestore”).
- Provide the storage connection string or select a managed identity option in the portal.
- Confirm container permissions and that the portal shows the selected connection string.
- Mark product name, category, and brand as searchable and retrievable in the index.
- Include metadata fields (country, city) in the knowledge store if you selected “content and metadata”.
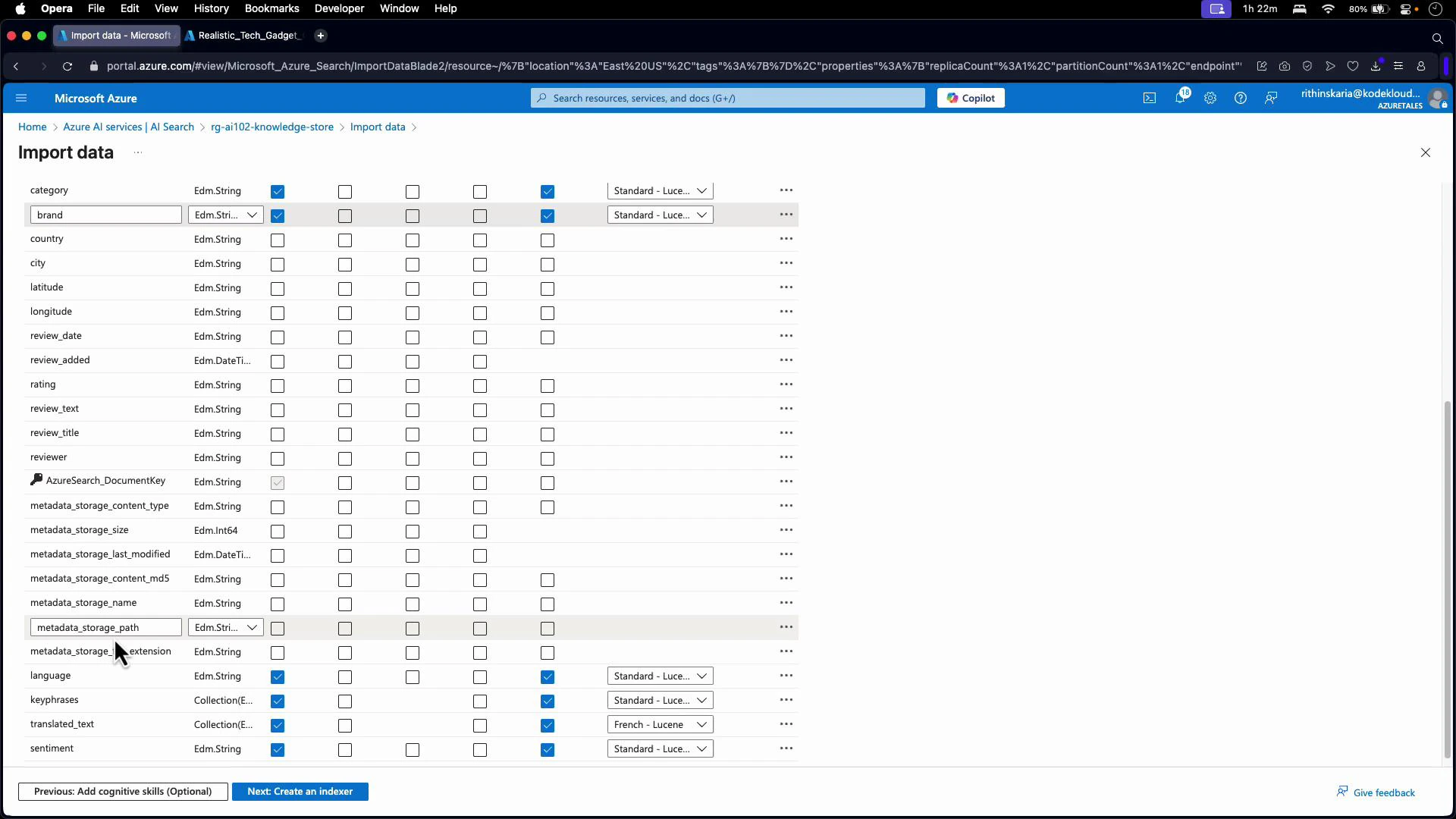
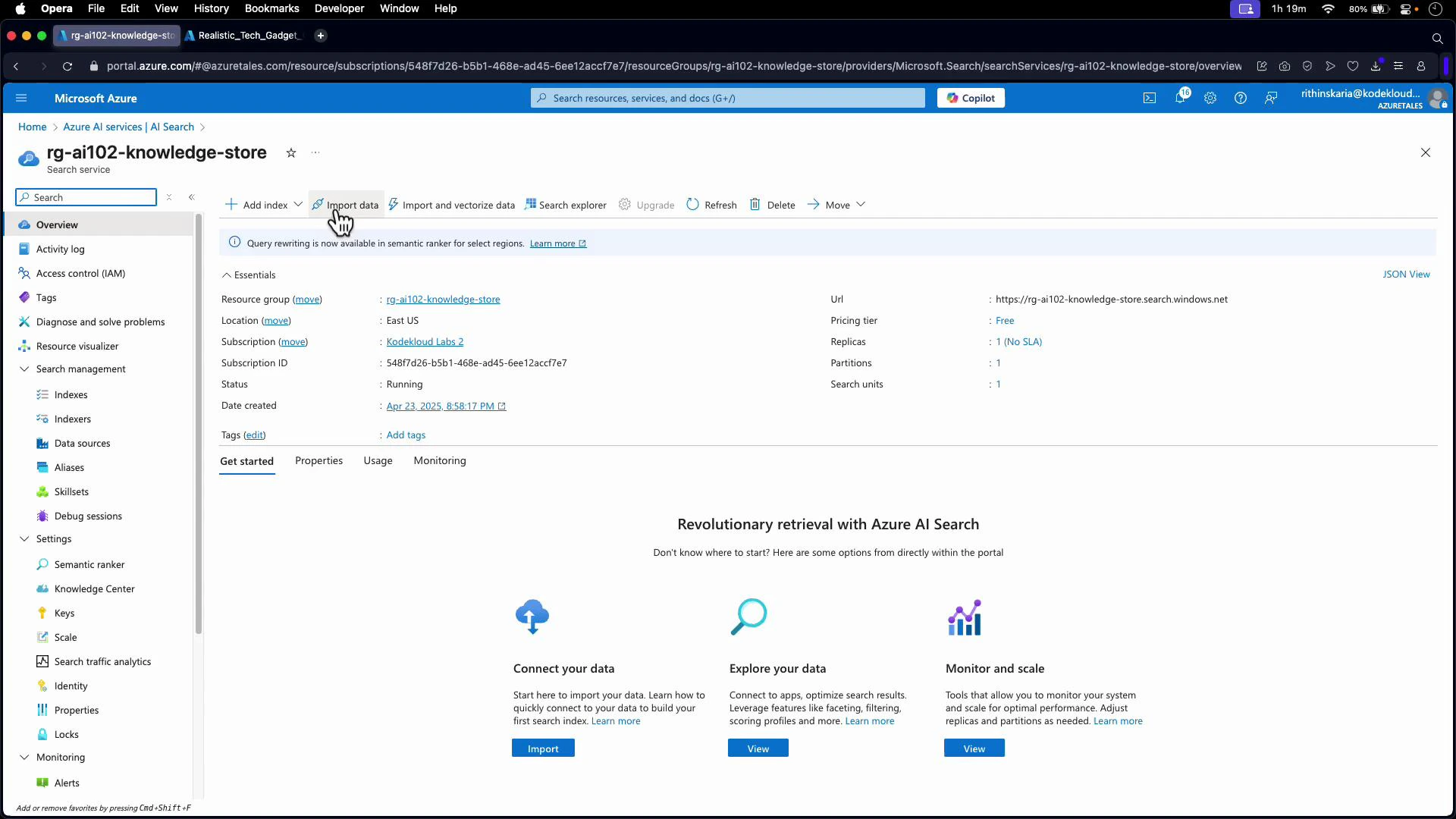
- Read blobs from the storage container
- Execute the configured skillset to enrich content
- Write enrichment results to the search index
- Persist projections to the knowledge store if enabled
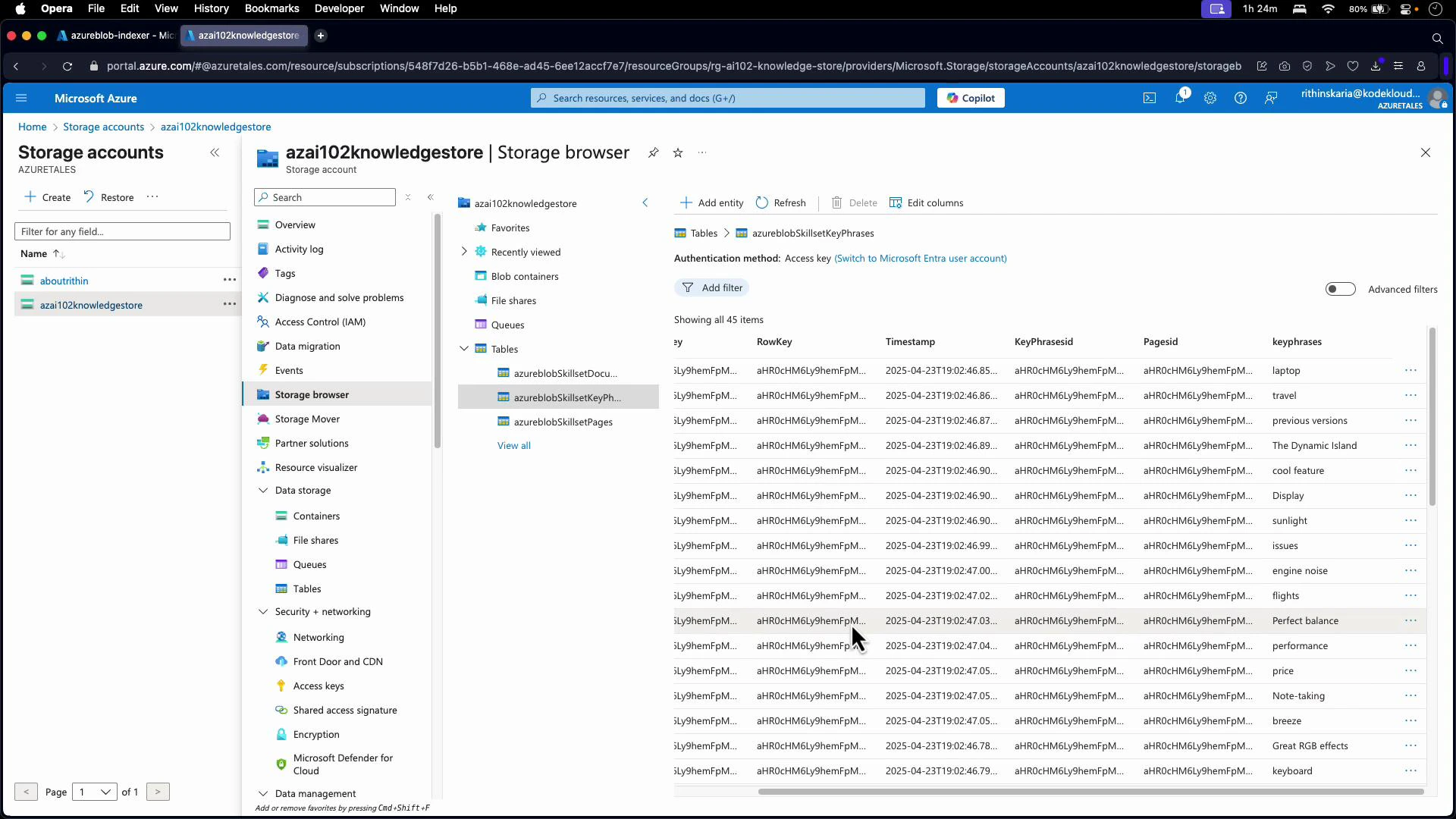
azureblobSkillsetDocument, azureblobSkillsetKeyPhrases, azureblobSkillsetPages). Each table contains rows for pages, key phrases, documents, sentiment, translations, and other enriched fields.
Example: key phrases table showing RowKey, Timestamp, PageId, and key phrase content.
- Sentiment analysis dashboards
- Customer experience reporting
- Archival or compliance workflows
- Downstream ML feature stores
- Map enrichment outputs into specific table names and generated keys
- Project page-level artifacts and nested key phrases
- Persist extracted image binary data to a blob container
- Azure Cognitive Search documentation: https://learn.microsoft.com/azure/search/
- Knowledge store overview: https://learn.microsoft.com/azure/search/search-knowledge-store-overview
- Azure Storage documentation: https://learn.microsoft.com/azure/storage/