- What the Analyze API returns (captions, detected objects and people, OCR/read, smart crops, etc.)
- How to select Visual Features to limit and focus the response
- SDK usage patterns and a full Python example to parse results
- REST usage patterns and a sample query string for the Analyze endpoint
- Practical options (smart crops, language, gender-neutral captions, model versioning)
REST API example
A typical REST Analyze request is performed against the Image Analysis endpoint. Example URL (replace <your-endpoint> and ):- Query parameters:
- features — comma-separated visual features to return (example: caption, people, objects, read, smartCrops).
- model-name — model to use (e.g., latest or a specific version).
- language — language for captions / OCR results.
- api-version — service API version.
- an image URL in the JSON request body, or
- raw image bytes in the request body (binary upload).
SDK usage (C# and Python — conceptual)
SDKs simplify calls and return typed objects. Below are conceptual method signatures to illustrate common patterns. C# (conceptual):Visual features (examples)
Analysis options
You can tune the behavior of the analysis call with these options:- Cropping aspect ratios — request smart-crop suggestions for thumbnail generation or fixed aspect ratios.
- Gender-neutral captioning — enable gender-neutral language for generated captions.
- Language selection — specify language for OCR and captions.
- Model versioning — pin to a specific model for reproducible results.
- Additional flags — options vary between SDKs and REST; consult the model-name and API docs.

Example: setting analysis options
C# (conceptual):Image analysis results
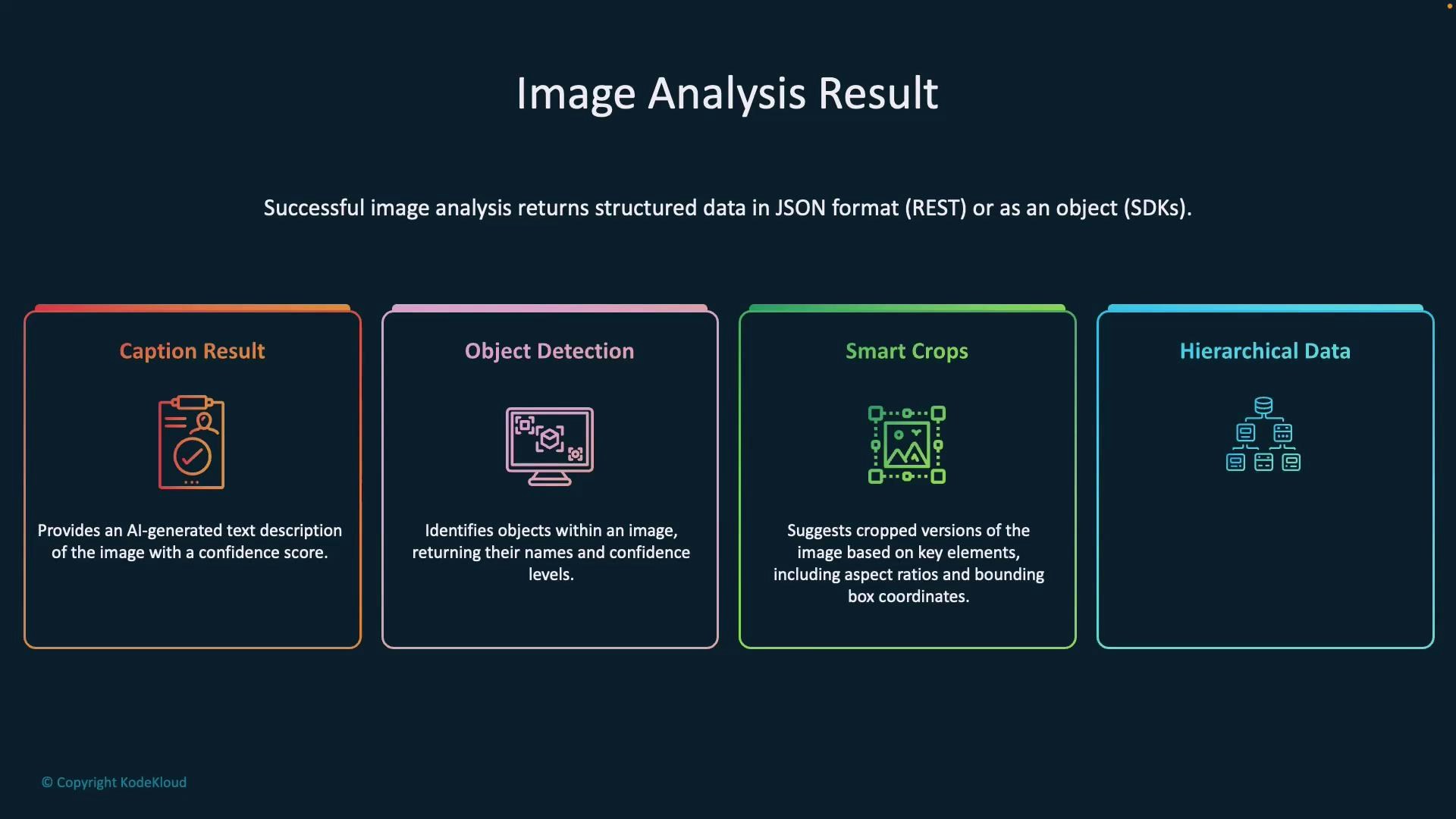
Responses from the service are structured and predictable so you can parse them reliably. Typical top-level sections:- captionResult — best caption and confidence
- objectsResult — array of detected objects with bounding boxes and confidence
- peopleResult — array of people detections with bounding boxes and confidence
- smartCropsResult — suggested crop boxes for requested aspect ratios
- tagsResult / tags — label/tag information and confidence
- read / ocr results — recognized text blocks/lines
- metadata — image dimensions and format
- modelVersion — the model used for inference
- render captions for accessibility,
- draw bounding boxes for objects and people,
- select recommended crops for thumbnails, and
- display detected tags and OCR text in the UI.
Hands-on: Python SDK example
Install the Azure AI Vision package for Python:Replace endpoint and key values below with the endpoint and key from your Azure AI service (Keys and Endpoint in the Azure portal). Never commit production keys into source control.
- Initializes ImageAnalysisClient with your endpoint and key.
- Chooses the visual features to analyze.
- Calls analyze_from_url with optional analysis options.
- Prints the raw JSON response and demonstrates robust parsing of common result sections (people, caption, tags, objects).
Protect your API keys: rotate keys regularly, store secrets in a secure vault (e.g., Azure Key Vault), and avoid hard-coding secrets in source control.
Live demonstration notes and best practices
- Provision an Azure AI service in the Azure portal. Use the Keys and Endpoint values from the portal for your client.
- Use blob storage URLs or public URLs for images. For private images, upload binary image bytes in the request body.
- Gender-neutral captions help avoid gender assumptions in generated text (e.g., “a person hugging a dog”).
- Smart crops return bounding boxes for the aspect ratios you specify—use these to create thumbnails that preserve important content.
- Pin model versions for reproducible results; use “latest” for new features and model improvements.
- Always validate and sanitize service outputs before surface-level display in production applications.
Links and references
- Azure AI Vision overview
- Analyze concept: Image Analysis
- Azure AI services: overview
- Azure portal
- azure-ai-vision PyPI package