What is image classification?
Image classification trains a model to assign one (or more, in multi-label setups) label(s) to an entire image. For example, given a photo of fruit, an image classification model predicts whether the image contains an apple, a banana, or an orange.
How image classification works
- Training: Feed many labeled images to a supervised model so it can learn representations for each category.
- Inference: For a new image, the trained model outputs the most likely label(s) and often a confidence score.
- Prepare dataset (images + labels).
- Train model (transfer learning with a pre-trained backbone is common).
- Evaluate and tune.
- Deploy for inference.

- Product recognition — identify products for checkout or cataloging.
- Medical imaging — classify scans for anomalies (tumors, fractures).
- Automated tagging — label photos for search, organization, and recommendations.
What is object detection?
Object detection goes further than classification: it identifies and localizes every instance of one or more object categories within an image. For each detected object the model typically returns a class label, a localization box (bounding box), and a confidence score. For example, instead of saying the image contains fruit, an object detector draws bounding boxes around each apple, banana, and orange and labels them individually.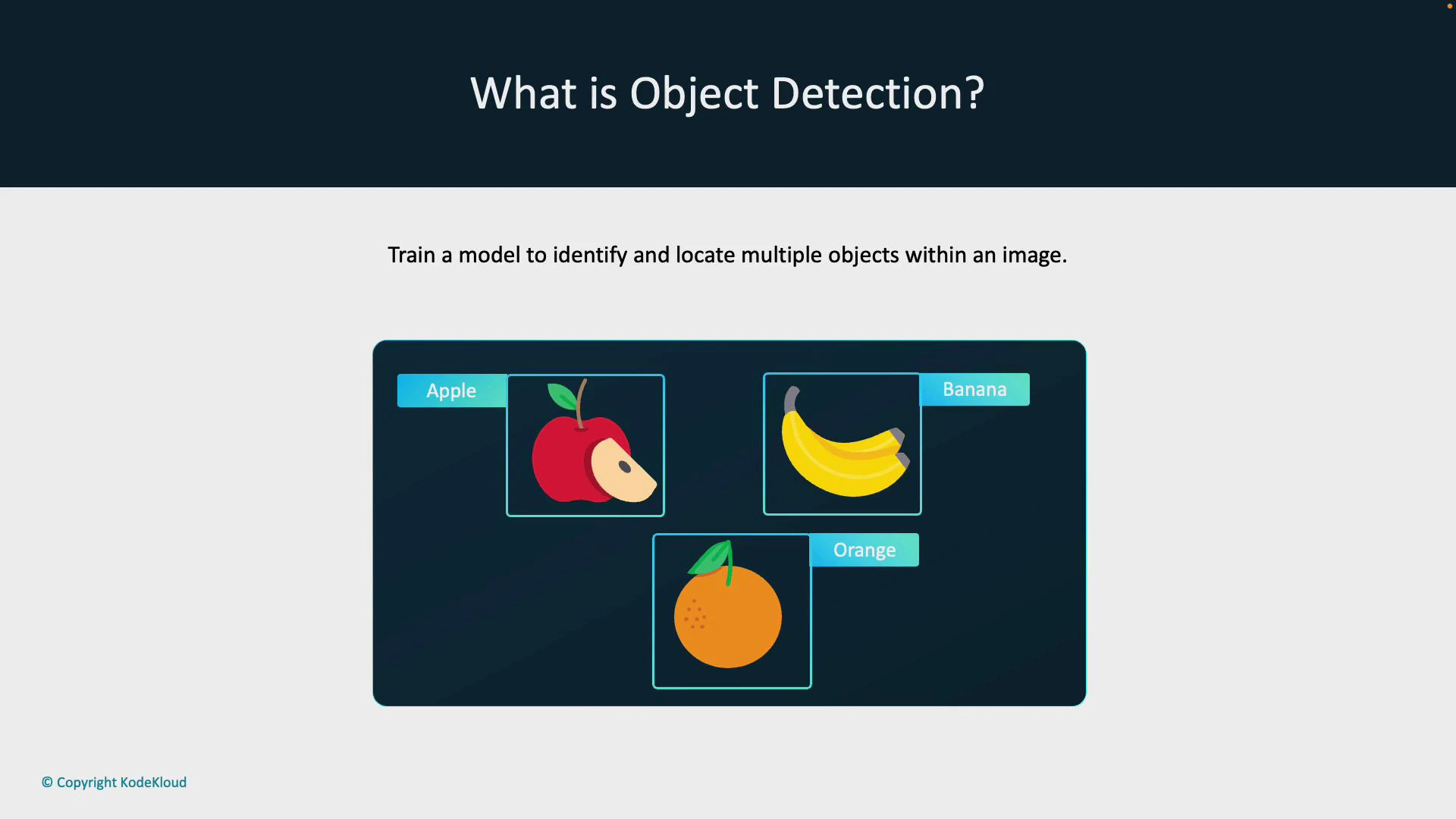
How object detection works
- Training: Train on images where each object instance is annotated with a class label and coordinates for a bounding box (or polygon/mask for more advanced models).
- Inference: For a new image, the model predicts one or more bounding boxes with associated class probabilities and confidence scores. Post-processing (e.g., non-maximum suppression) typically refines overlapping detections.
Key distinction: image classification assigns a label to the whole image; object detection locates and labels each object instance and returns coordinates (e.g., bounding boxes) plus confidence scores.
- Self-driving cars — detect pedestrians, vehicles, and road signs for navigation and safety.
- Surveillance — locate and track people or objects across camera feeds.
- Warehouse inventory — count and locate products or packages automatically.
Quick comparison
Common annotation formats and a small example
- COCO (JSON) — widely used for detection and segmentation.
- Pascal VOC (XML) — older but still common for bounding-box tasks.
- YOLO formats — compact text-based annotations per image.
Best practices
- Use transfer learning with pre-trained backbones (ResNet, EfficientNet, MobileNet) for faster convergence.
- Ensure high-quality annotations: accurate bounding boxes and consistent labels are crucial.
- Balance classes or use augmentation to address imbalanced datasets.
- Validate with appropriate metrics: accuracy/ROC for classification, mean Average Precision (mAP) and IoU thresholds for detection.
Annotation quality matters: incorrect or inconsistent labels/bounding boxes degrade both classification and detection model performance. Invest time in review and quality control.
Links and references
- COCO dataset and format
- ImageNet
- OpenCV documentation
- Microsoft Custom Vision
- A guide to mean Average Precision (mAP)