- Prevent hallucinations by giving models verifiable context.
- Surface organization-specific knowledge not present in base models.
- Enable citations so answers include traceable sources.
Quick workflow: Chat playground (no code required)
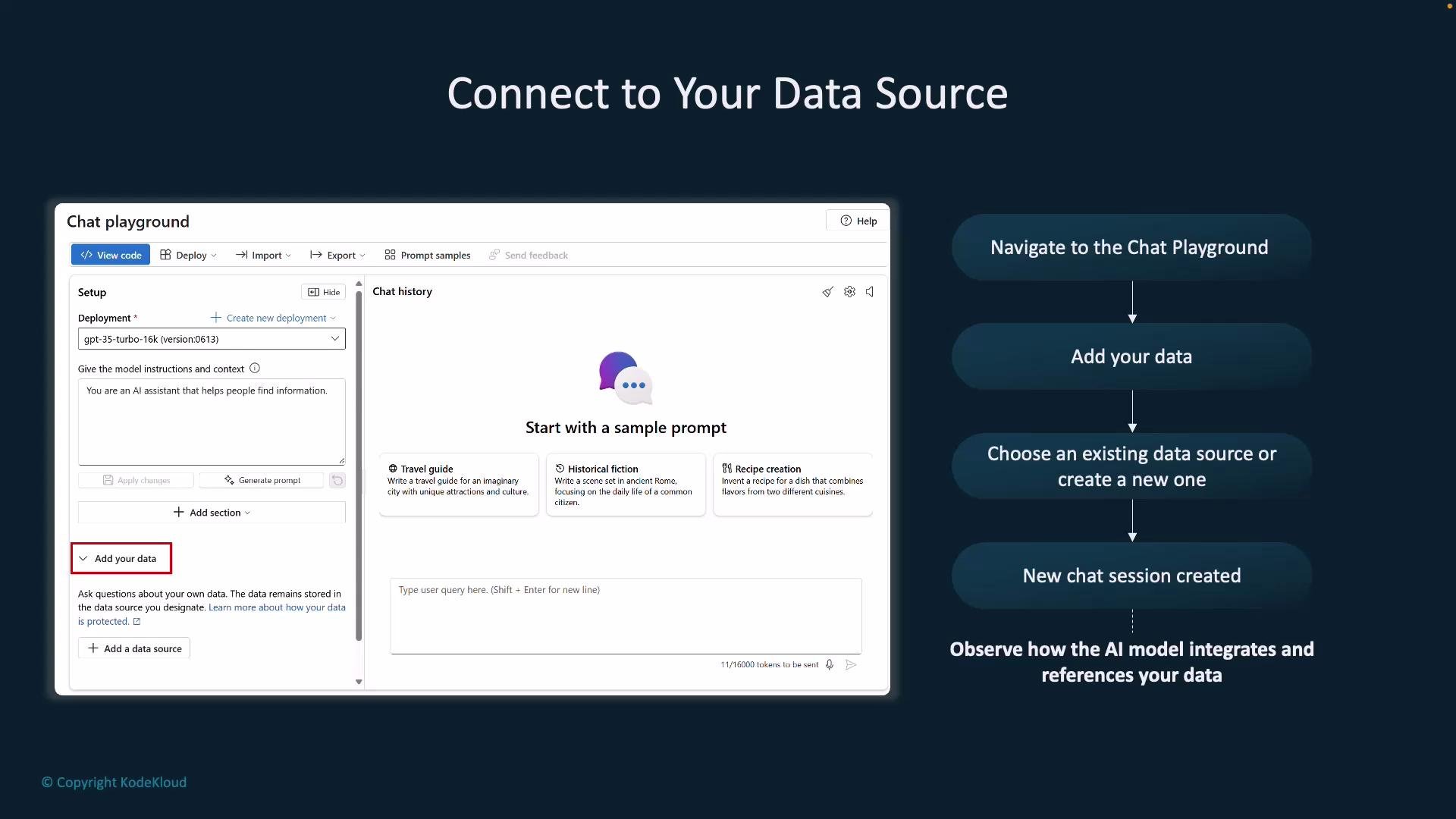
The Azure OpenAI Studio chat playground provides a central UI for composing prompts, selecting deployments, and adding data sources so the assistant can reference documents you control. Use this for rapid iteration before implementing code. Steps to connect a data source from the Chat playground:- Open Chat playground in Azure OpenAI Studio.
- Click Add your data.
- Choose an existing data source (for example, Azure AI Search index) or create one from the dialog.
- After adding, a new chat session is created and grounded in that data — the model can integrate content from your documents and cite sources.
Demo: Indexing a PDF from Azure Blob Storage
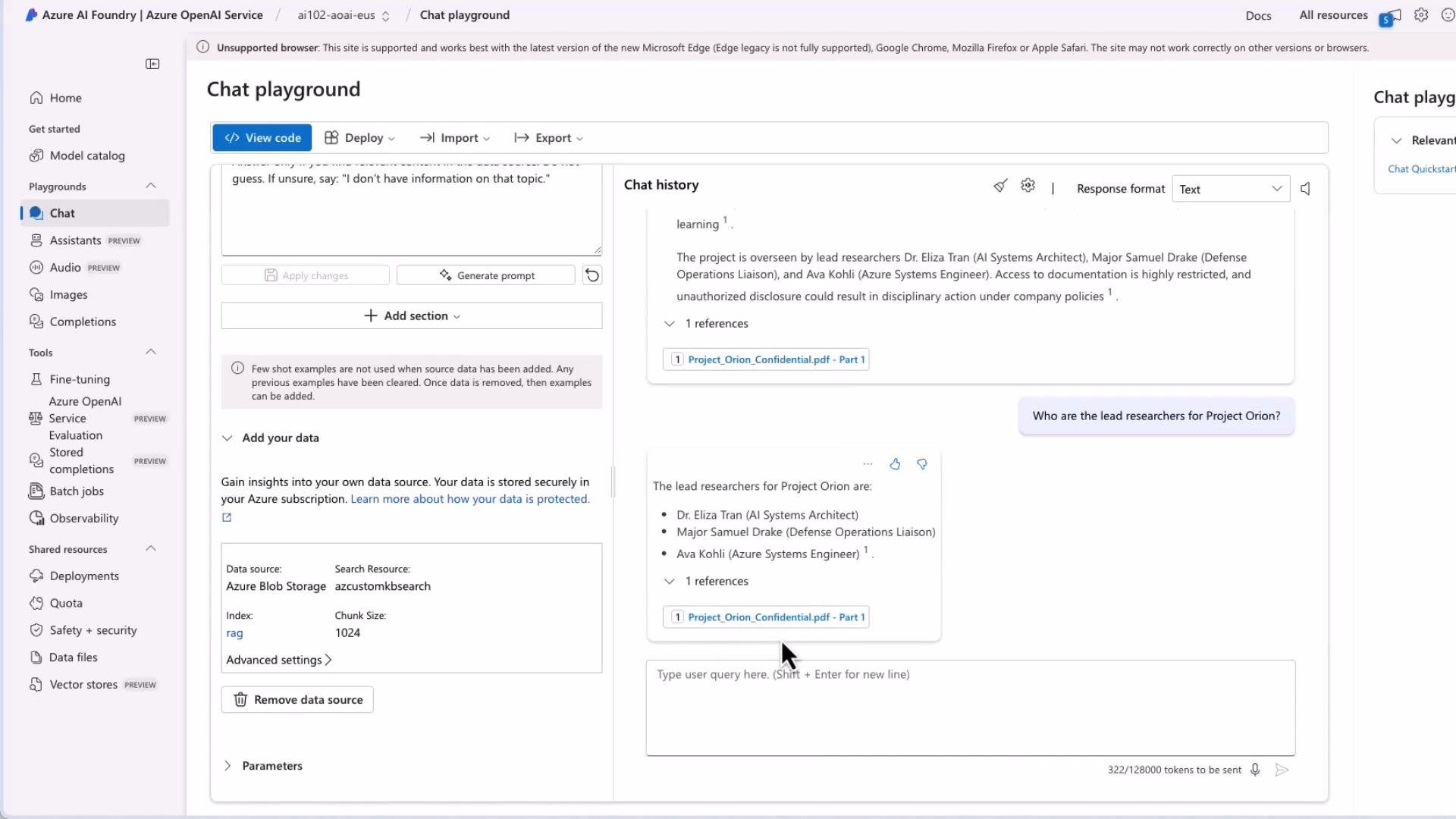
Scenario: You have Project_Orion_Confidential.pdf stored in Blob Storage and want the assistant to answer questions using the PDF content.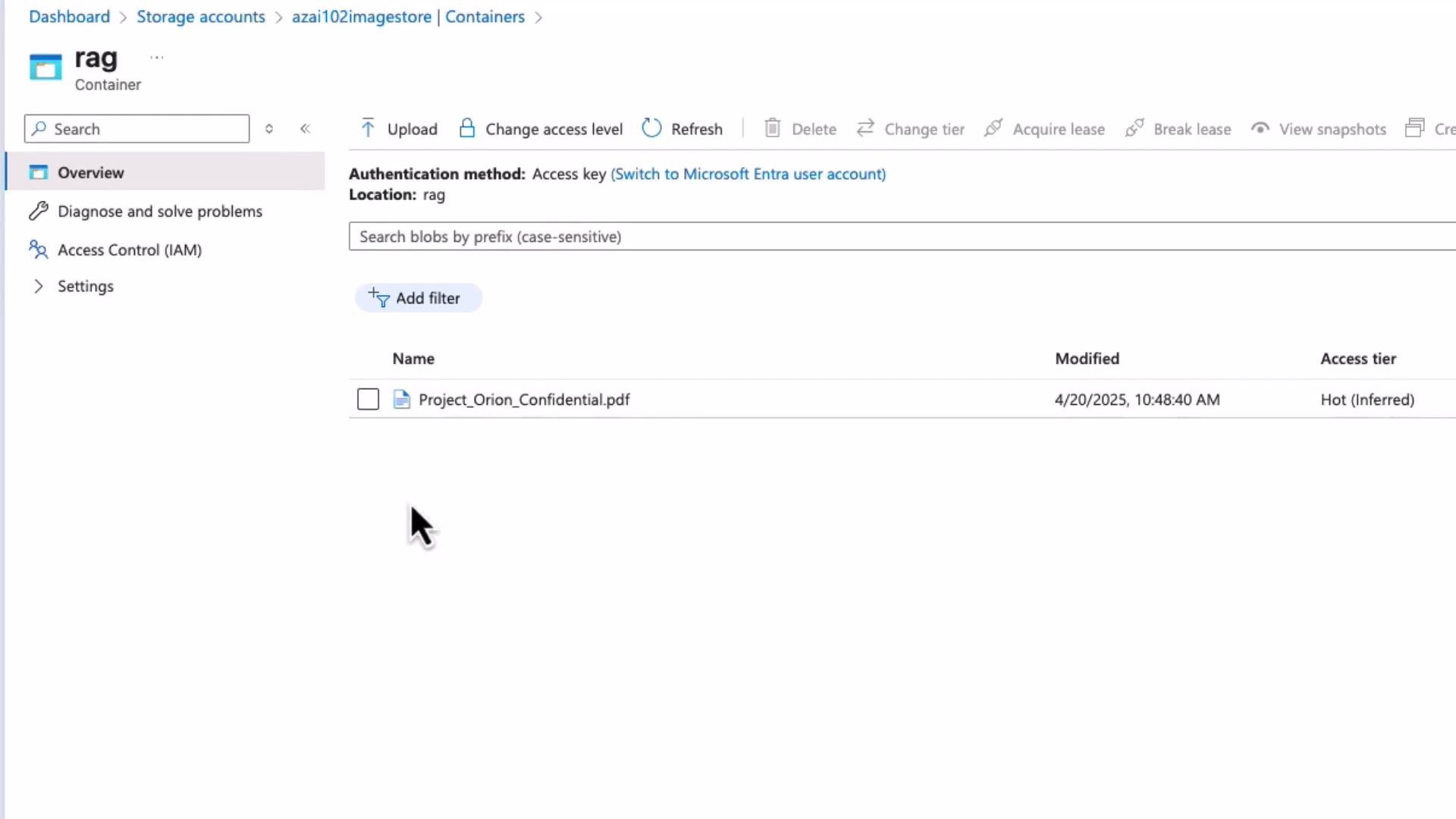
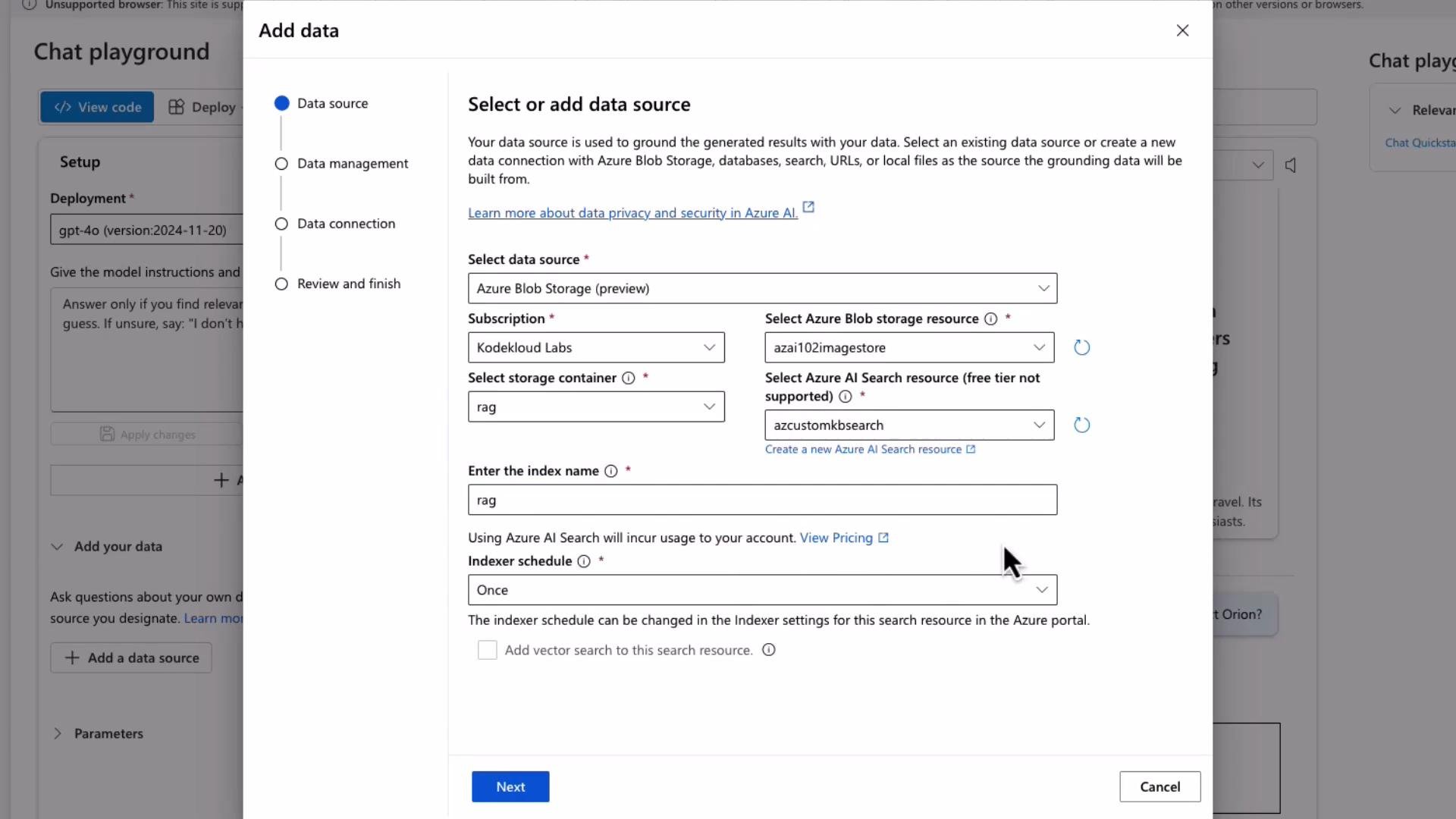
Add the Blob Storage data source
- In the Add data dialog choose Azure Blob Storage and point to the container with your file.
- Select an Azure Cognitive Search resource — this service builds the index and returns semantically ranked documents to Azure OpenAI.
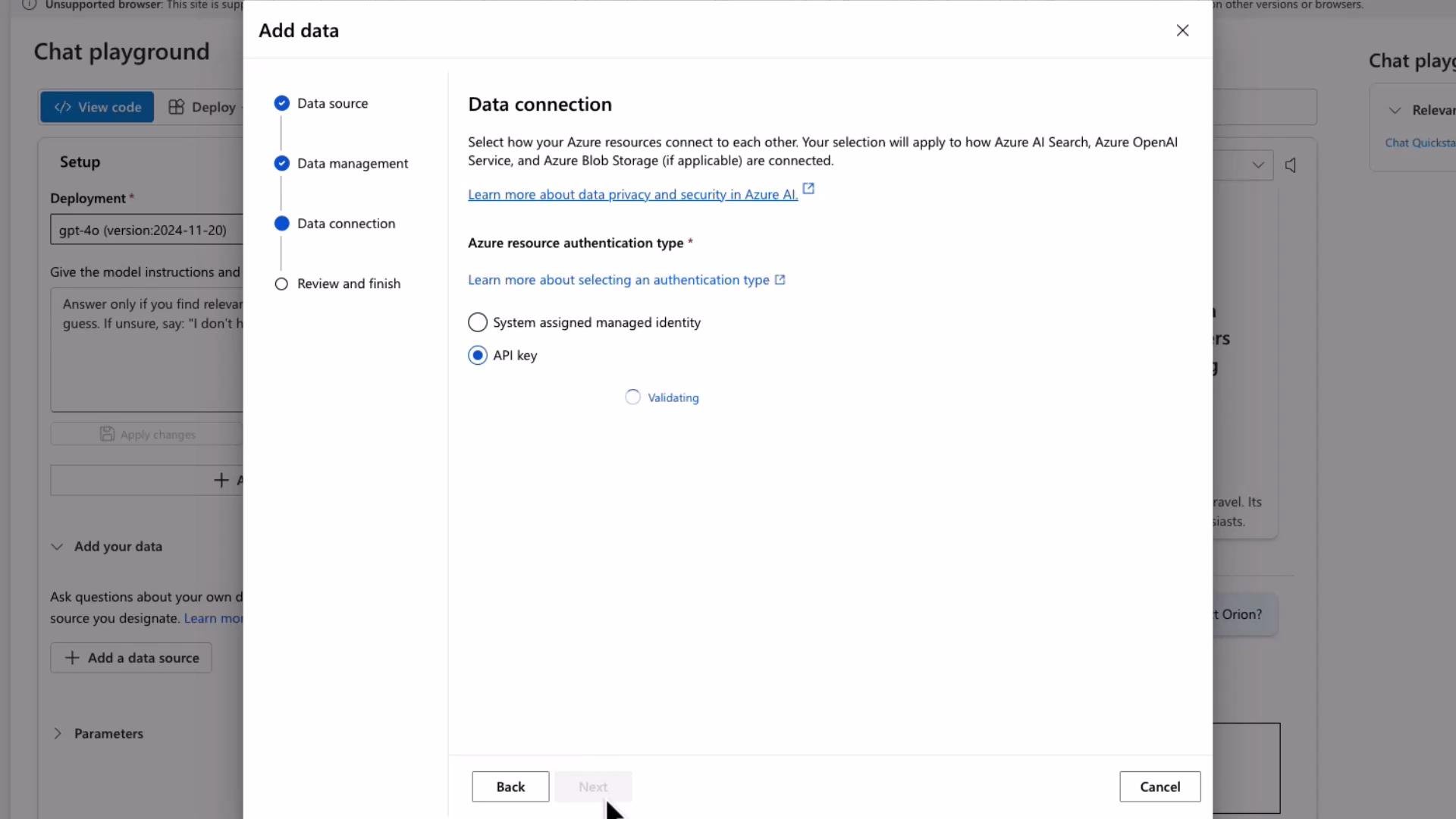
- Provide an index name (for example, rag) and configure authentication (API key or managed identity).
- Save and let the platform ingest and index the document. A status indicator shows ingestion progress; once complete, the chat session can return citations from the indexed file.
REST integration: key considerations
- Each REST request to the Azure OpenAI endpoint for RAG-enabled interactions should include a data_sources array. This tells the model where to look for external content (for example an Azure Cognitive Search index).
- Authentication for the data source is managed through the search resource (or other data service), not the Azure OpenAI resource. Ensure the access method you pick (API key or managed identity) is configured correctly and the identity has appropriate permissions.

SDK overview and typical flow
Azure OpenAI SDKs (used with Azure OpenAI deployments) simplify integration in languages like Python and C#. Even when using the SDK you still supply a messages array and a data source object to indicate where to find ground-truth content. Typical steps:- Install the Azure OpenAI/OpenAI SDK for your language.
- Create a client (API key or identity-based auth).
- Define chat messages (system + user).
- Attach a data_sources object (endpoint, index, authentication).
- Send the request and process the response.

- Azure AI Search — primary index for grounding (GA).
- Azure Cosmos DB for MongoDB vCore — document-level grounding (preview).
- More connectors are being added — check Azure release notes for updates.

Tip: pick a connector that matches where your documents live and your required retrieval semantics.
When to let the service retrieve vs. app-side retrieval
Two common patterns:- Service-side retrieval: include data_sources in the API call and let Azure OpenAI + Azure Cognitive Search handle retrieval + generation. Simpler; less client code.
- App-side retrieval: query Cognitive Search from your app, select top-K docs, and include the content in messages. Offers more control over retrieval, filtering, and privacy.
When integrating data, choose between (a) letting the OpenAI service call your search index via the data_sources parameter in the API, or (b) performing retrieval in your application (query search), then sending the retrieved content as context. Both approaches are valid—pick one that meets your latency, cost, and security requirements.
Authentication for data sources is tied to the search/data resource, not the Azure OpenAI resource. Ensure the identity (API key or managed identity) you configure has appropriate permissions to access the search index or storage.
Example: Python end-to-end (Azure Cognitive Search + Azure OpenAI)
This simplified Python example shows one common pattern:- Query Azure Cognitive Search to get top-K documents.
- Format these documents into a context.
- Call Azure OpenAI chat completions with messages containing the context.
- Print the assistant response.
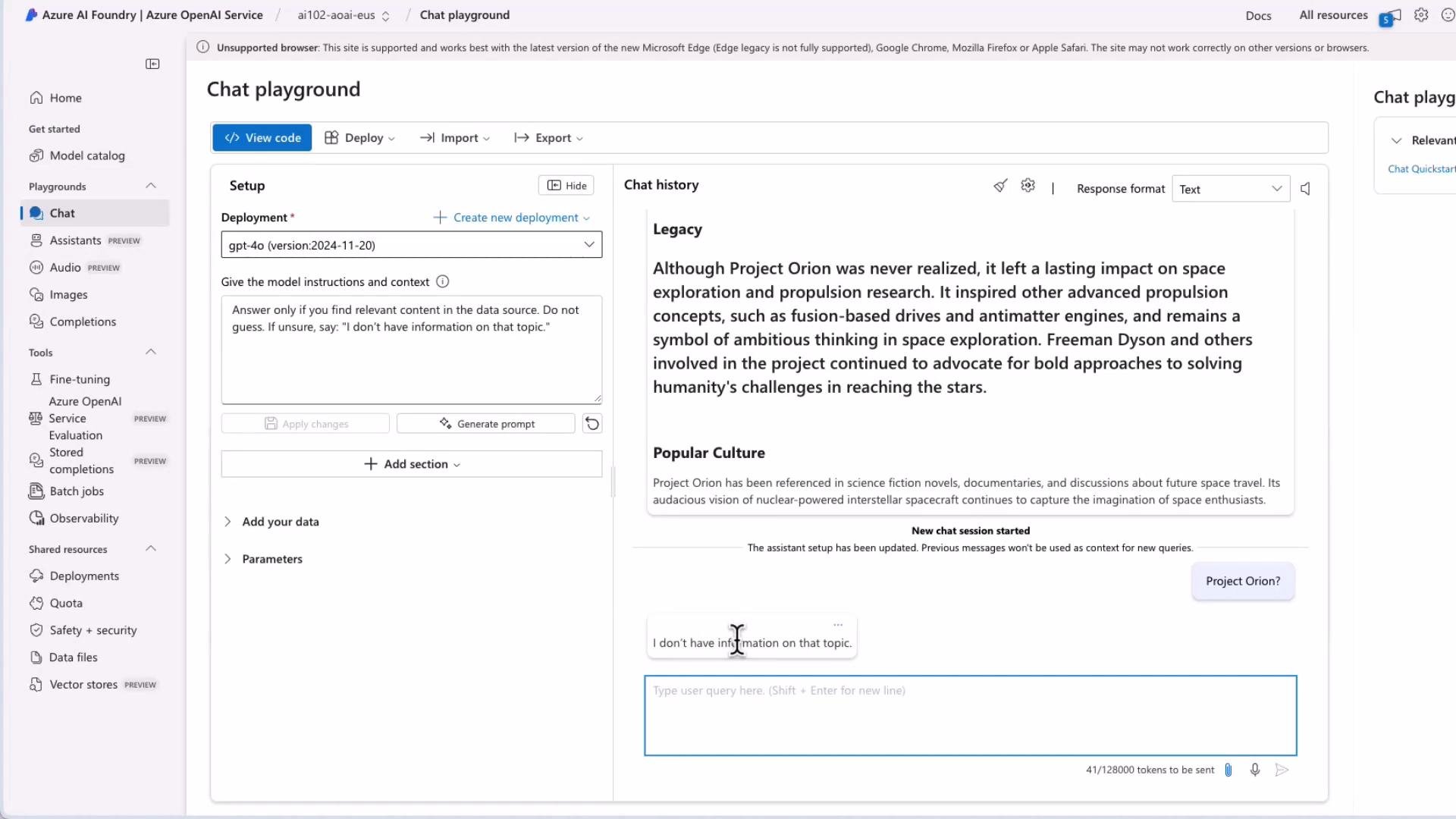
- If documents are indexed and retrieved, the assistant responds with a supported answer and cites the source.
- If no relevant documents are found, the assistant replies: “I don’t have information on that topic.”
Closing notes and references
- Ensure Azure Cognitive Search and its authentication method (API key, managed identity) are configured properly — data-source auth is tied to the search resource.
- Use clear system messages to constrain the assistant and reduce hallucinations.
- Choose between service-side retrieval (data_sources parameter) and app-side retrieval (explicit queries) based on latency, cost, and security trade-offs.
- Monitor Azure release notes for new data-source connectors and SDK updates.
- Azure OpenAI Service documentation
- Azure Cognitive Search documentation
- Azure Blob Storage documentation