- The application queries a contextual data source — typically a vectorized knowledge base of travel guides, web-scraped pages, or documents — to retrieve the most relevant documents.
- Retrieved documents (or document excerpts) are combined with the user’s prompt to form an augmented prompt.
- The augmented prompt is sent to an LLM (for example, GPT-4 via the Azure OpenAI Service), which uses both its parametric knowledge and the retrieved, non-parametric context to generate a grounded answer.
- The application can surface citations or source links from the retrieved documents to improve traceability and factuality.
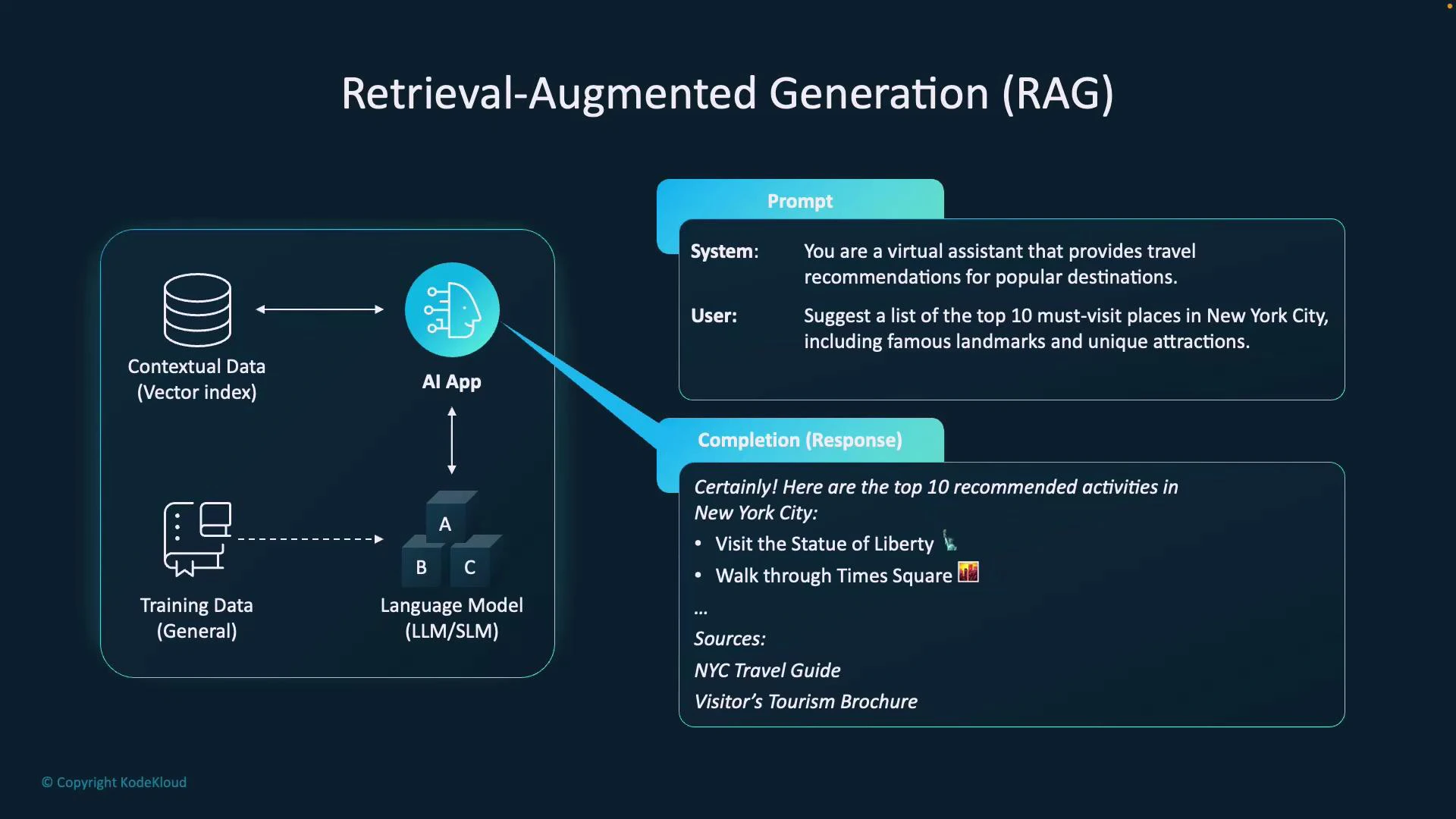
- LLM (parametric knowledge): general knowledge learned during pretraining, useful for fluency, reasoning, and broad knowledge.
- Vectorized contextual store (non-parametric knowledge): embeddings-backed index that retrieves up-to-date or domain-specific facts at query time.
- Orchestration layer: handles embedding queries, retrieval, ranking, prompt assembly (prompt + retrieved context), and invoking the LLM.
- Grounding and citations: the final LLM output can include explicit citations from the retrieved documents, increasing trustworthiness.
RAG separates a model’s static, pretrained knowledge from dynamic external knowledge stored in a vector database. This modularity lets you update or extend the system’s knowledge by re-indexing or refreshing external documents without retraining the model.
- Keeps answers current with external sources.
- Improves factual accuracy by grounding model outputs.
- Enables domain specialization with curated corpora (legal, medical, product manuals).
- Allows scaling: smaller models plus targeted retrieval can match or beat larger models on certain tasks.
Typical RAG orchestration (high-level pseudo-code)
- Embeddings: Use a consistent embedding model for both documents and queries to ensure meaningful similarity search.
- Chunking & context windows: Break long documents into chunks sized for the LLM’s context window; include overlap to preserve continuity.
- Relevance and hallucination mitigation: Rank and filter retrieved passages; include explicit citations so users can verify answers.
- Latency and cost: Retrieval adds a network/compute step — caching and efficient indexing help reduce latency and cost.
- Security & privacy: Be cautious about sensitive data in external knowledge bases; apply appropriate access controls and data redaction.
- Azure OpenAI Service documentation
- Vector databases and embeddings: consider providers like Pinecone, Milvus, or open-source options
- RAG pattern overview and research: search for Retrieval-Augmented Generation and hybrid retrieval + LLM systems