- Define the API endpoint — point to the API that hosts your custom skill (commonly an Azure Function). Optionally include any required HTTP headers and parameters.
- Determine where the skill should be applied — specify the document context (whole document, section, or field).
- Map input values — map document fields to the skill’s expected inputs (for example, mapping the document’s content field).
- Store the processed output — specify the output field(s) that will be added to the document and indexed.
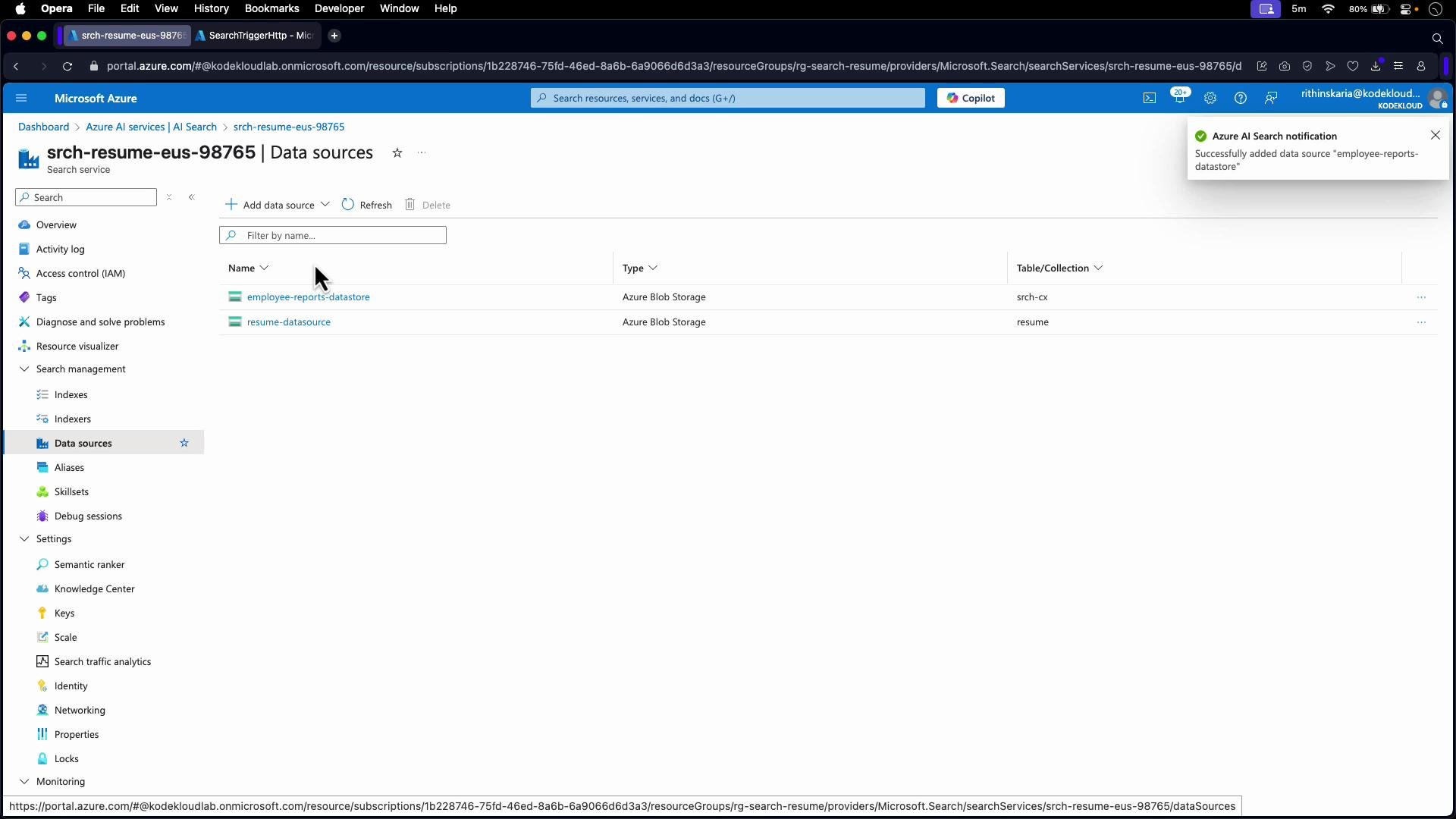
Before you begin, ensure you have an Azure Storage container with input documents, an Azure Cognitive Search service, and a hosted Web API (such as an Azure Function) accessible via HTTPS. You will also need permission to create data sources, skillsets, indexes, and indexers in the Search service.
@odata.type— declares the custom Web API skill type.uri— the HTTP endpoint that implements the skill (include a function key if required).httpHeaders— optional headers for auth or other metadata.context— where the skill is applied (for example,/document).inputs— maps document fields to skill inputs.outputs— names the fields the skill will add to the document.
values array. Each item must include recordId and data (the input fields). The response must return a values array with each recordId and data containing the output fields (for example, employeeIds).
The custom Web API must accept and return the Azure Cognitive Search document array format (a
values array with recordId and data for each item). The response must include recordId and data with the output field(s) (for example, employeeIds).EMP-xxxxx format. The custom skill will extract and normalize these identifiers.
req.body.values (an array of records). For each record, extract EMP identifiers from the content input and return them in data.employeeIds inside the response values array.
The example below is resilient: it normalizes matches to EMP-xxxxx, deduplicates results, and handles errors per record.
- Name:
customemployeeskill(for example) - Context:
/document— applies the skill to the entire document - Inputs: map
contentto/document/content - Outputs: map
employeeIdsto targetemployeeIds - URI: Azure Function URL (include function key if required)
- HTTP Method:
POST - Adjust
timeout,batchSize, andhttpHeadersas needed
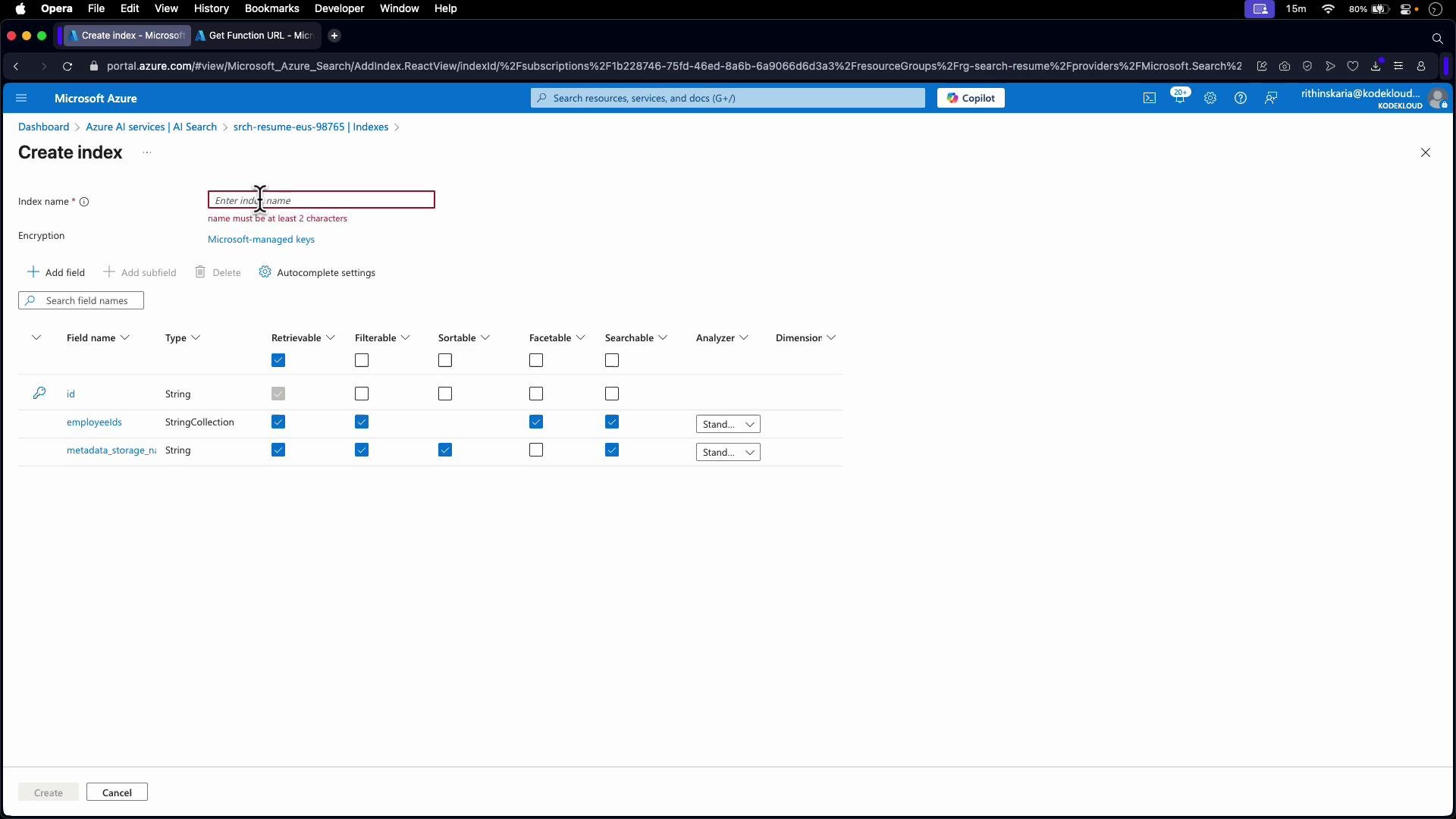
Configure other index fields (for example
id, content, metadata_storage_name) as appropriate.
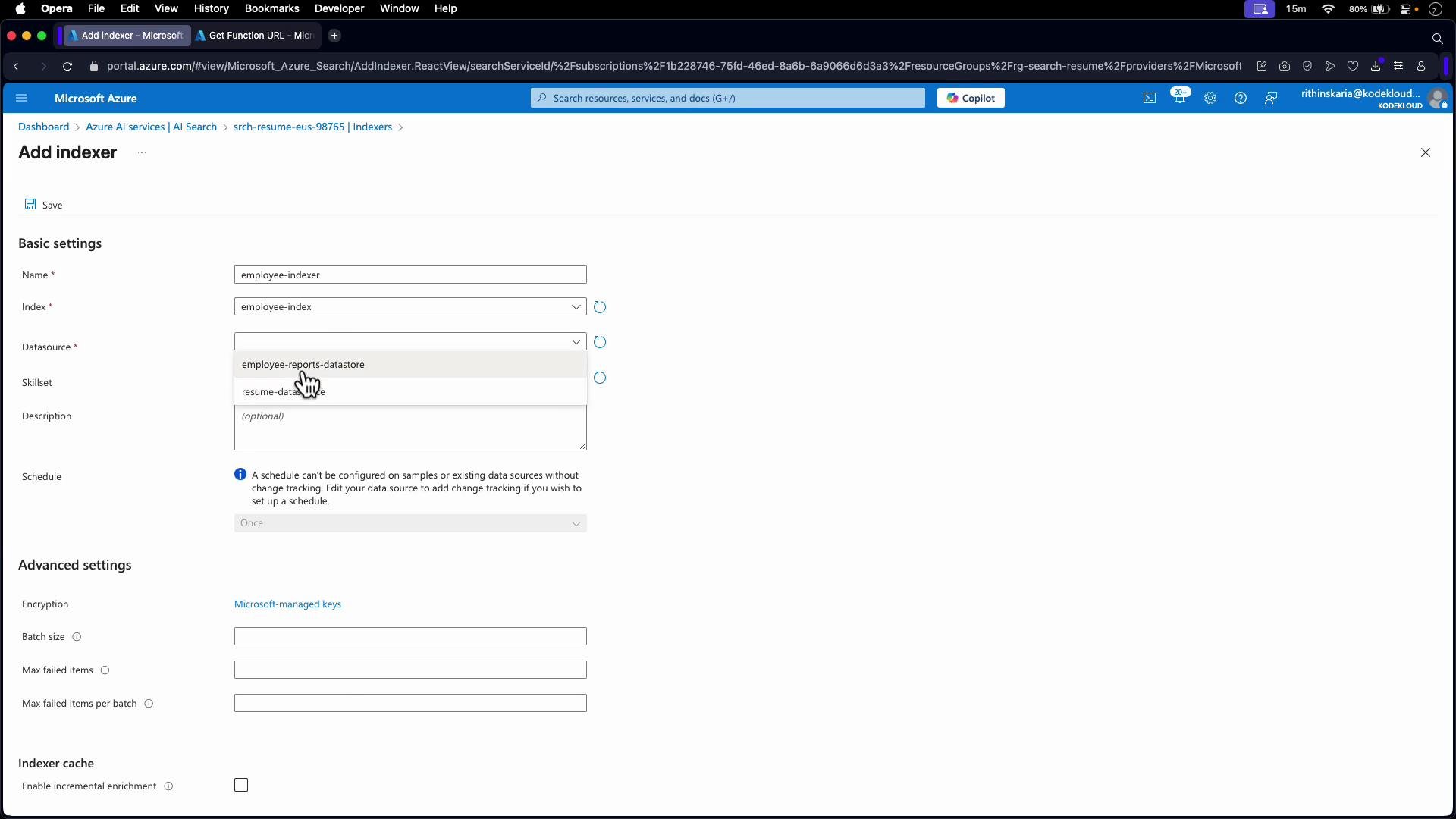
outputFieldMappings, which maps skill outputs into index fields. In the portal this is often a UI mapping; with REST you configure outputFieldMappings directly.
outputFieldMappings:
employeeIds arrays until the custom skill runs and the output mapping is applied.
Example response before enrichment (employeeIds empty):
employeeIds behaves like any other index field: you can search, filter, facet, and sort depending on the field attributes you chose.
Summary
- Implement a Web API (typically an Azure Function) that accepts the
valuescontract and returnsvalueswithdatacontaining your output fields. - Create a custom Web API skill that points to your function, and configure
context,inputs(e.g.,/document/content), andoutputs(e.g.,employeeIds). - Create an index field of type
Collection(Edm.String)to hold the extracted IDs and set retrievable/searchable/filterable options as required. - Configure the indexer with
outputFieldMappingsto map the skill output (/document/employeeIds) to the index field (employeeIds). - Run (or reset and run) the indexer to apply enrichment, then verify that the indexed documents contain the expected results.
- Azure Cognitive Search documentation
- Azure Functions documentation
- Cognitive Search custom skill interface
- Azure Storage account overview
- Search index overview
- Search indexer overview