
- Keeps data private and traceable.
- Produces domain-specific answers that use company vocabulary.
- Reduces hallucination by providing the model concrete source content.
The critical requirement is that content be retrievable and structured so the search/indexing service can compute semantic embeddings and relevance scores.
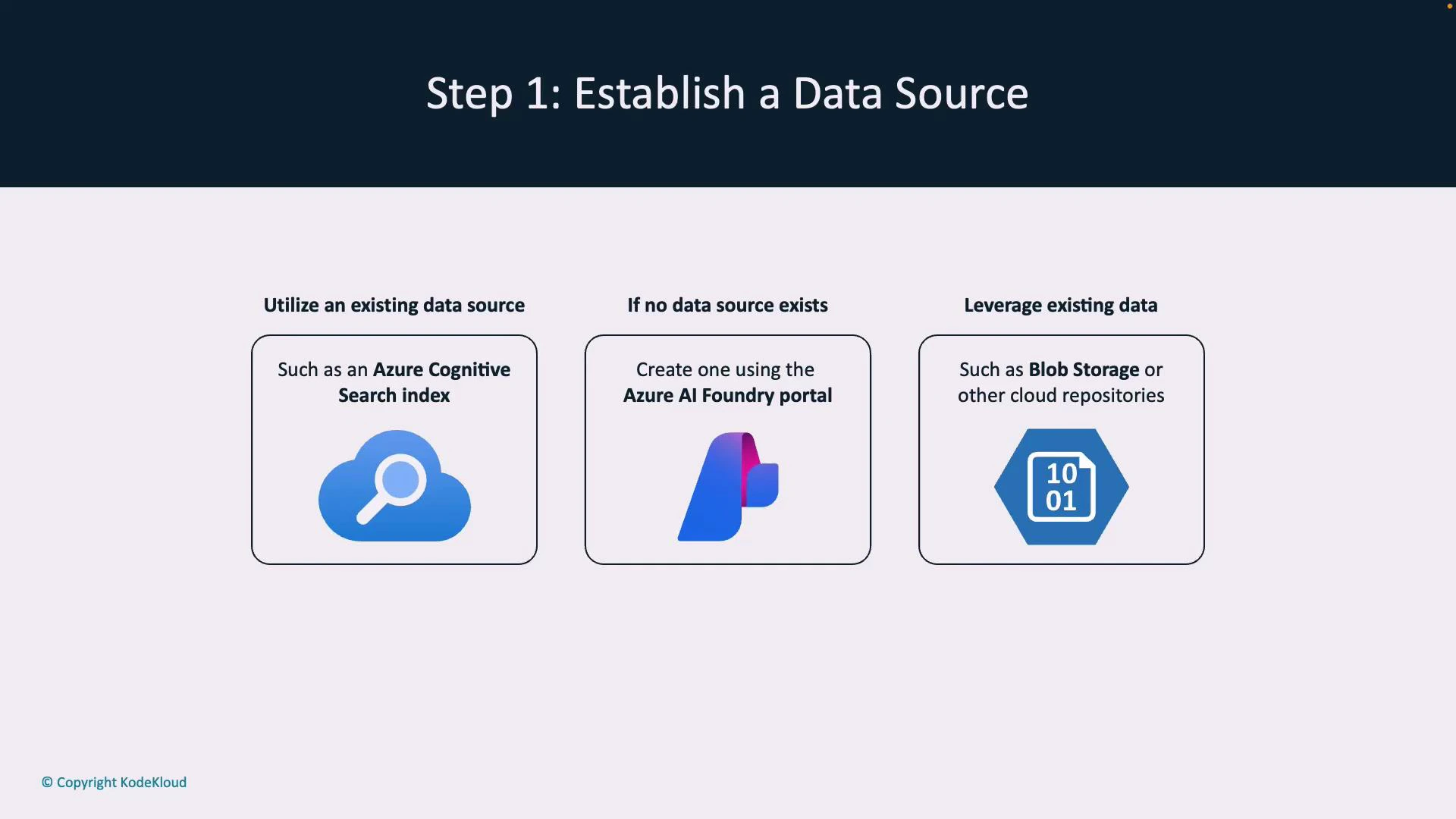
- Azure AI Foundry: Link a prompt flow to a specific data source so prompt flows automatically retrieve context.
- Your application: Pass data-source parameters (or SDK options) with each Azure OpenAI request to specify where to retrieve context.
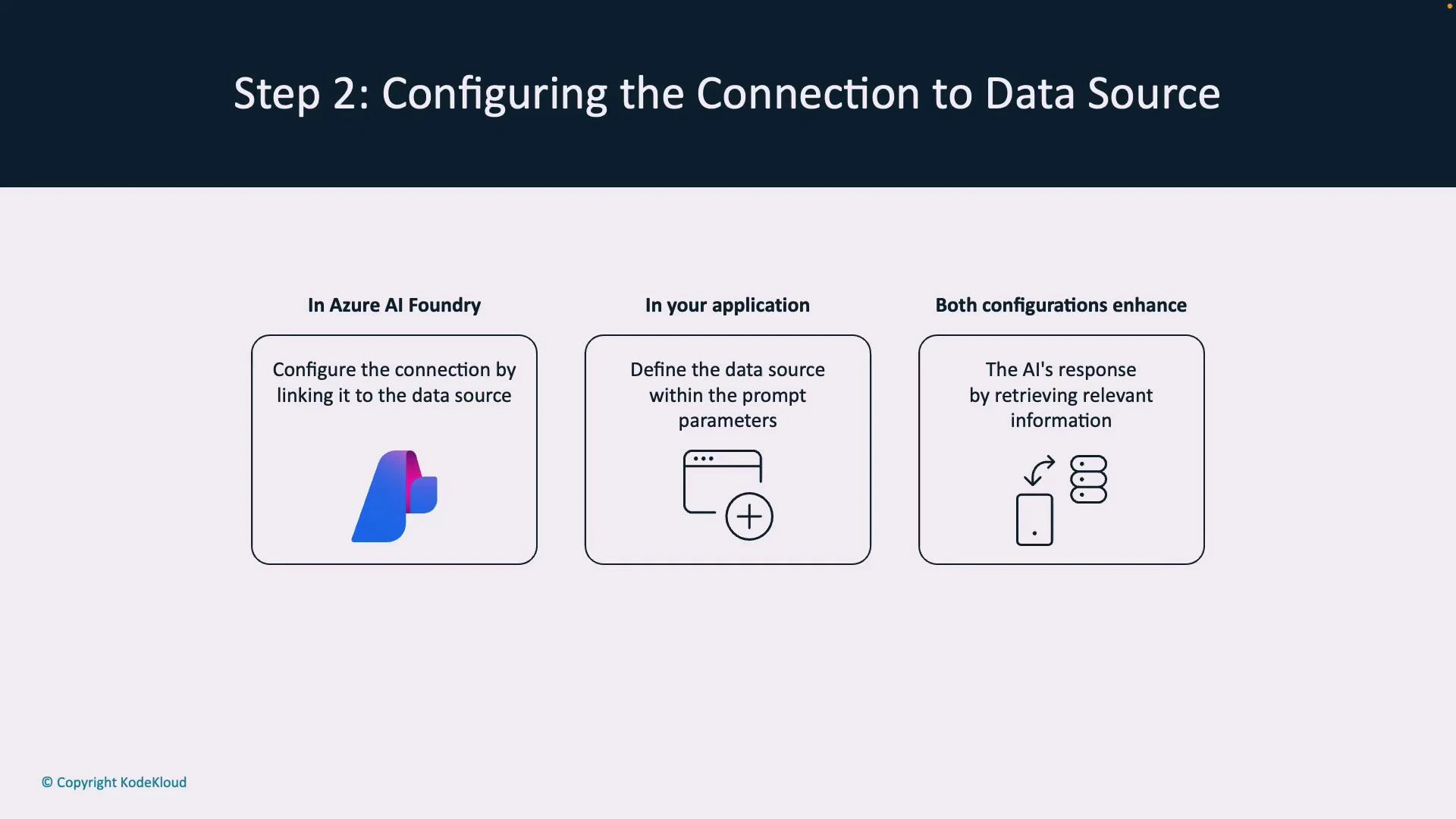
- The client calls an Azure OpenAI model via chat, REST API, or SDK.
- If configured, the system queries the linked index to retrieve and semantically rank relevant documents.
- Retrieved passages are injected into the model’s prompt context so the response is informed by your documents.
- You choose grounding behavior: strict grounding (use only retrieved content), hybrid (combine with model knowledge), or fallback responses.
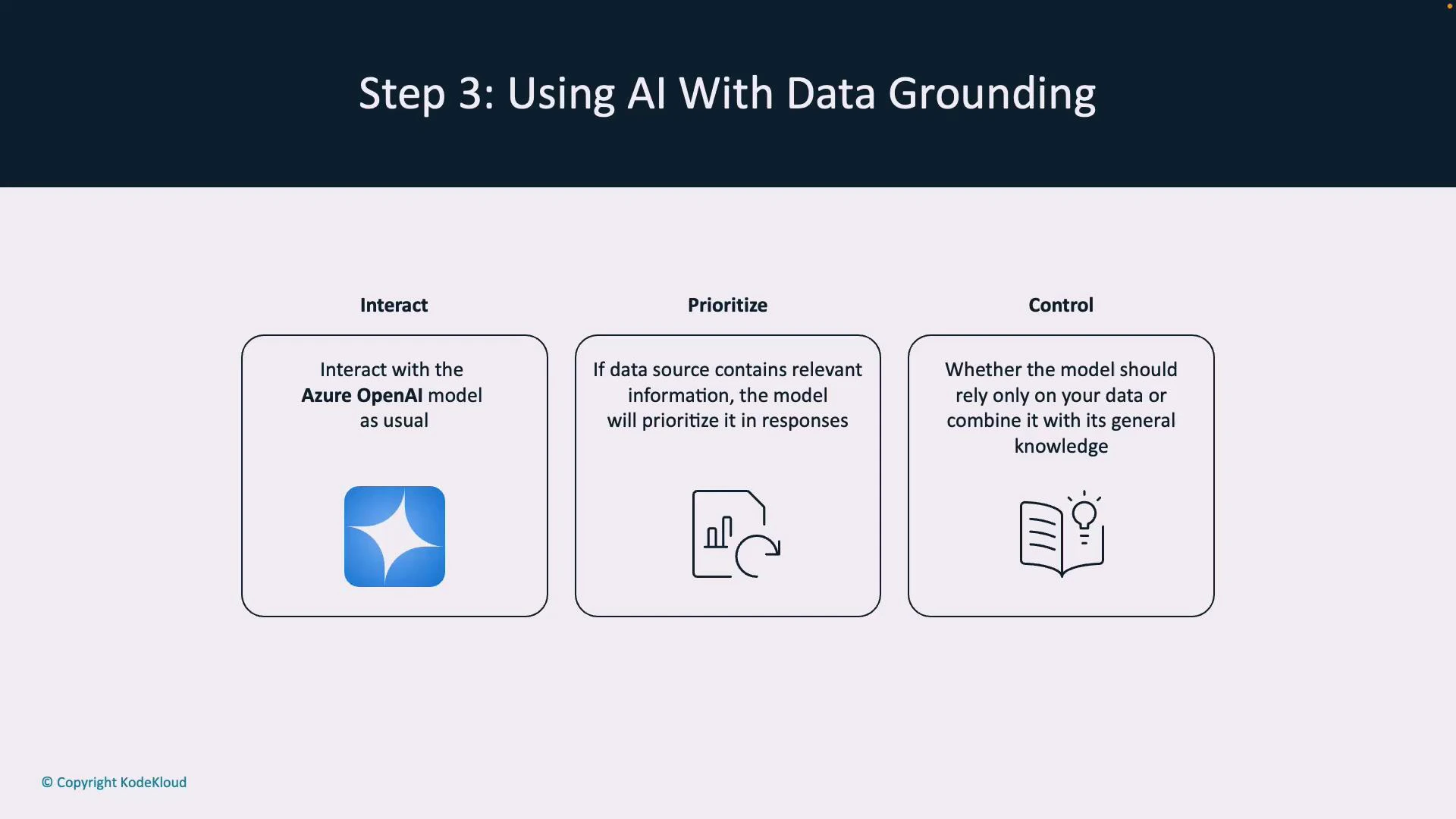
To enable semantic retrieval and ranking, you typically need an Azure Cognitive Search (Azure AI Search) index. The search service indexes documents and returns ranked results and embeddings that are passed into the model as prompt context.
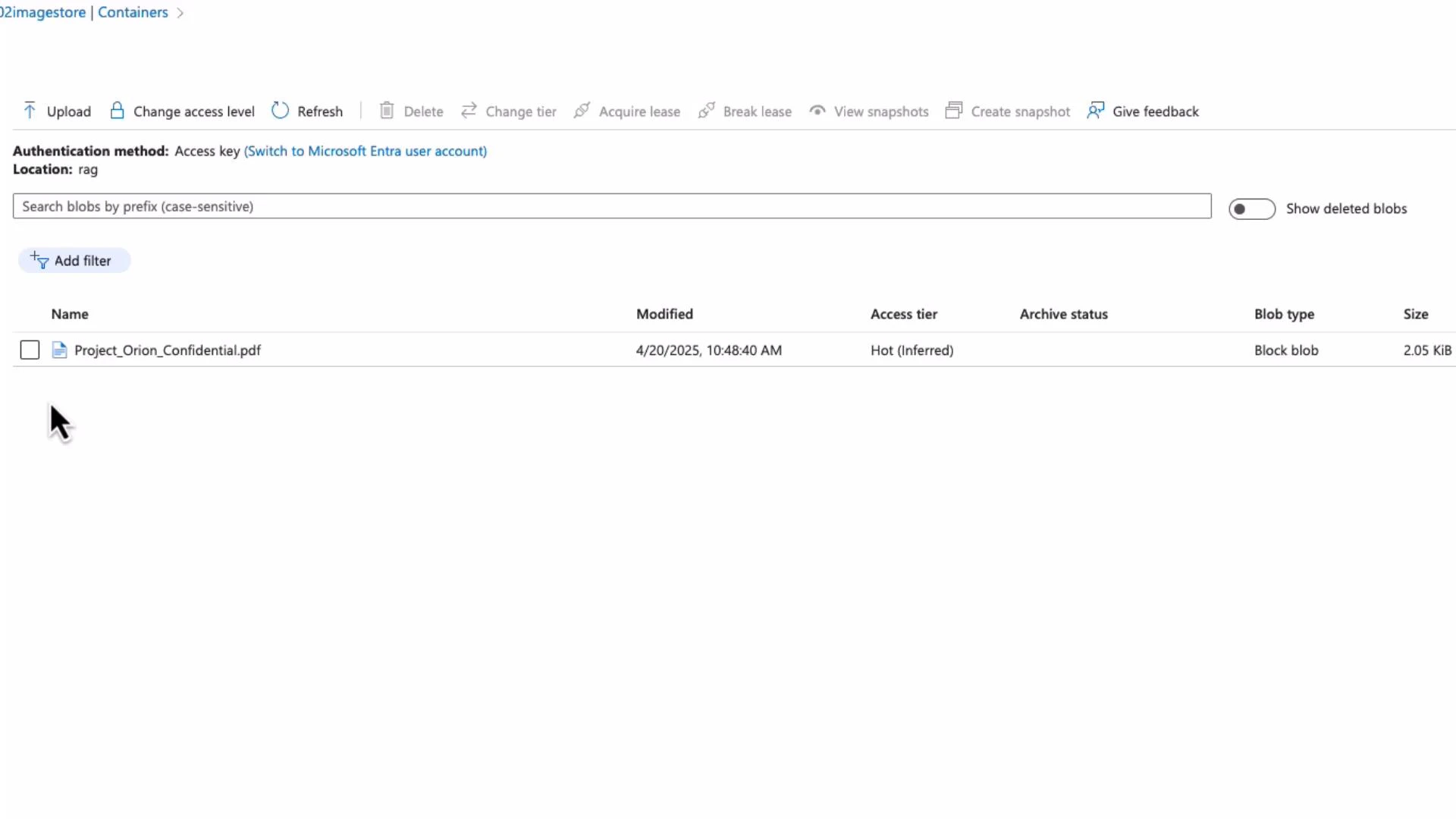
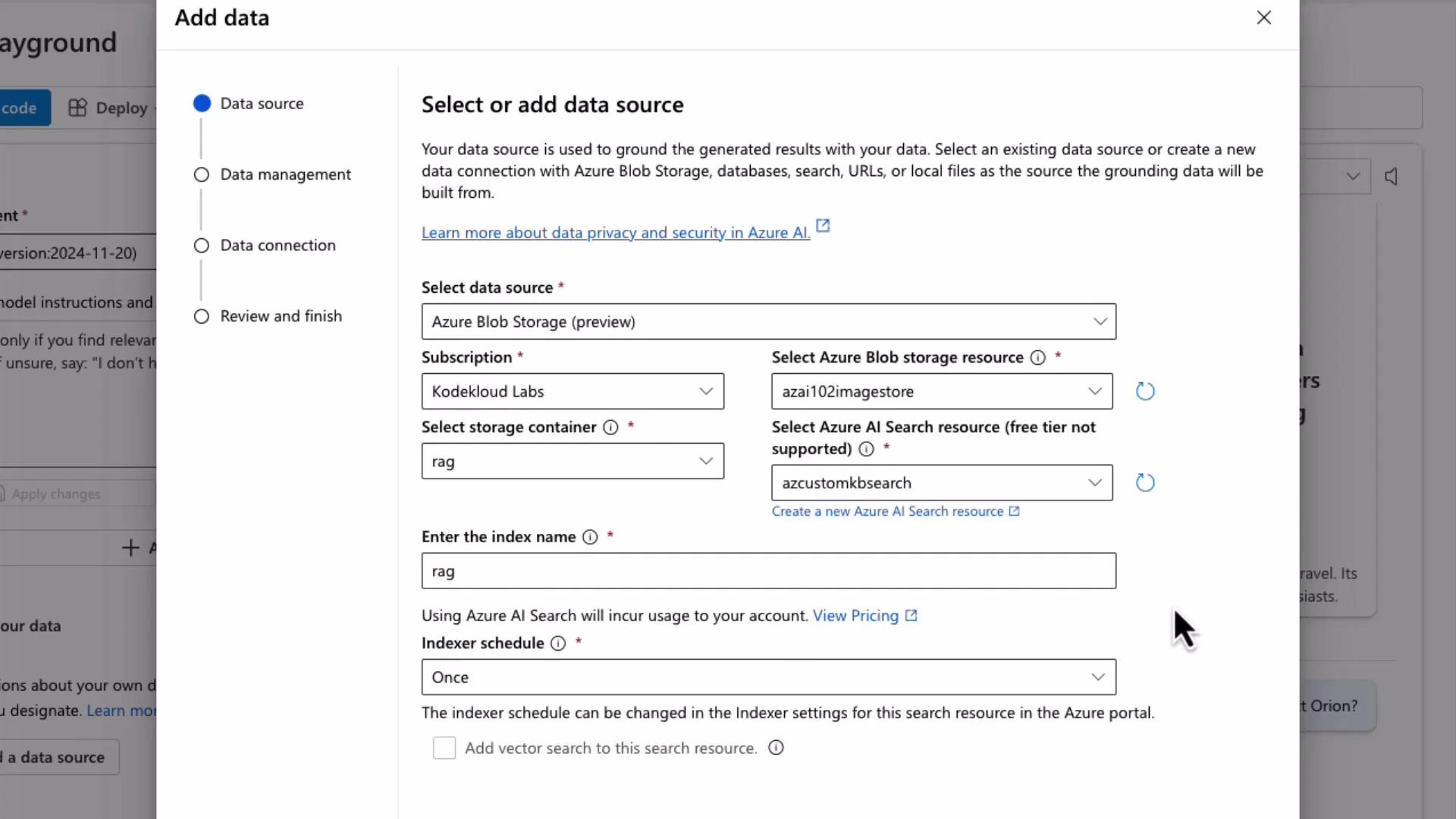
- Add Blob Storage as a data source (point to the container holding Project_Orion_Confidential.pdf).
- Select an Azure AI Search resource to host the index.
- Provide an index name (e.g., “rag”) and set an indexer schedule (e.g., “Once”) to start ingestion.
- Grounded responses: Use RAG to ground Azure OpenAI outputs in your private documents without fine-tuning.
- Build the pipeline: Index your content (Azure AI Search), connect it with Azure AI Foundry and/or your app, and inject retrieved passages into prompts.
- Control behavior: Use system messages and prompt design to enforce strict grounding or allow hybrid responses.
- Reduce hallucination: Use semantic ranking, explicit source citation, and safe fallback system instructions to avoid fabricated answers.
- Azure OpenAI Service documentation
- Azure Cognitive Search overview
- Azure Blob Storage introduction
- Fundamentals of RAG