- Completion endpoint: generate text continuations from a prompt.
- Embeddings endpoint: convert text into numeric vectors for semantic tasks (search, clustering, similarity).
- Chat completion endpoint: structured multi-turn conversational interface using role-based messages.
Completion endpoint
Use the completions endpoint to generate text continuations from a prompt. Replace <your-endpoint> and <deployment-name> with values from your Azure AI Foundry deployment. URL:- The generated text is in
choices[0].text. max_tokenscaps the response length. Tokens are the billing and length units used by the models.- You can control generation randomness and style with parameters like
temperatureandtop_p.
Embeddings endpoint
Use embeddings to convert text into numeric vectors. Store and compare these vectors (e.g., cosine similarity) for semantic search, recommendation, or clustering. URL:data[0].embeddingis the numeric vector representation.- Embeddings are commonly stored in vector databases (e.g., Pinecone, FAISS, Azure Cognitive Search) for fast similarity search.
Chat completion endpoint
Chat completions support multi-turn conversational flows using role-based messages (system, user, assistant).
URL:
- Assistant replies appear in
choices[0].message.content. - The
usageobject shows token counts for prompt, completion, and total (useful for cost tracking). - Chat completions are optimized for multi-turn interactions; maintain the
messagesarray to preserve conversation context.
Not all models support every API type (completions, embeddings, chat). Check the model catalog in your Azure AI Foundry portal to confirm which models support which inference tasks before calling an endpoint.
Inspecting models and deployments in Azure AI Foundry
Review the model catalog in Azure AI Foundry to pick the right model for your task (for example, embeddings vs chat). Filter by inference task to narrow the available models.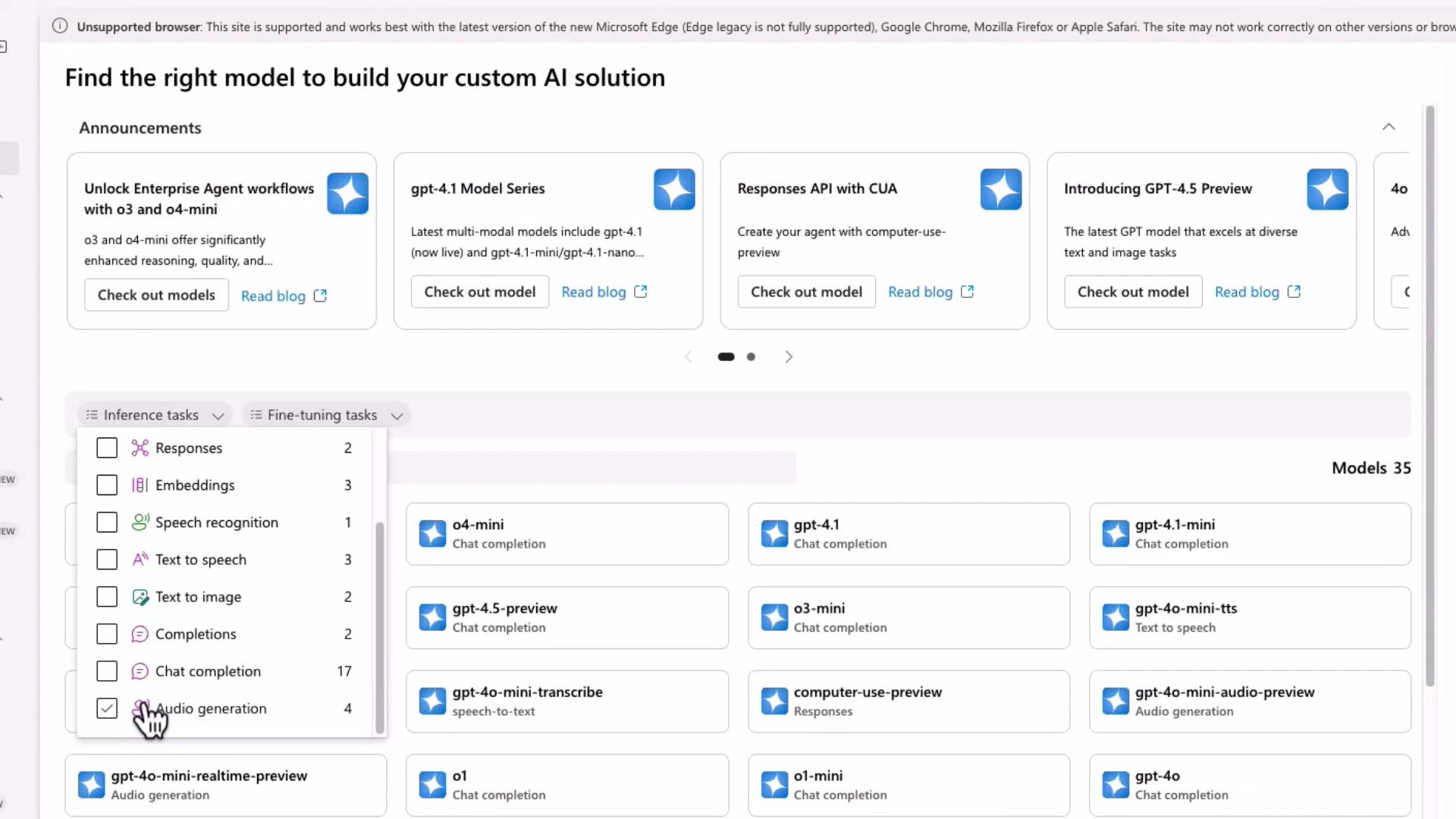
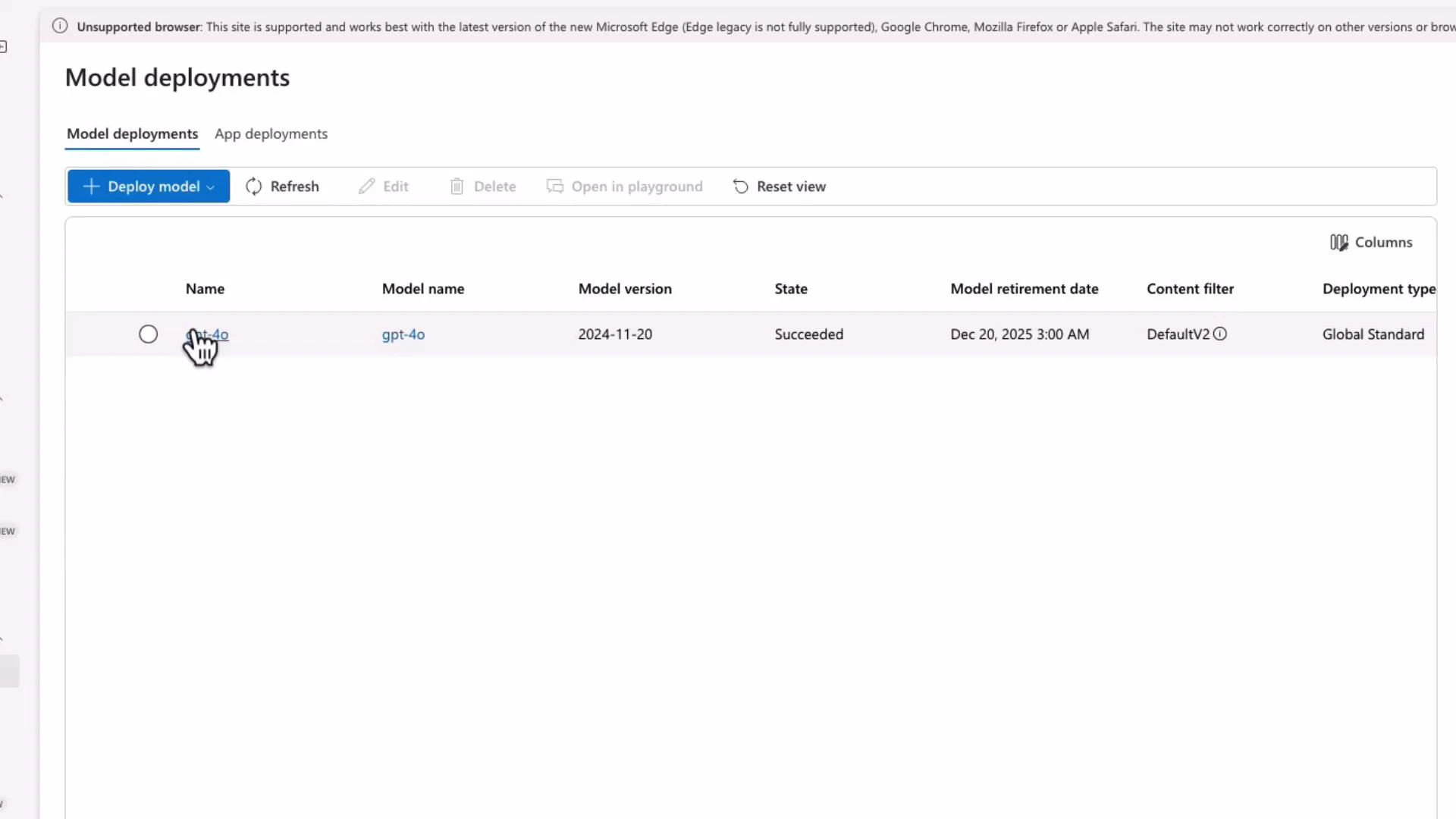
- The deployment page displays the REST endpoint you will call from applications or tools like Postman and curl.
- Use a clear, consistent deployment name — this name appears in the request URL path.
Example: calling the chat completion endpoint with curl / Postman
Set your API key in your shell or PowerShell environment. Bash (Linux/macOS):- Add the
Content-Type: application/jsonheader (Postman will do this automatically for JSON bodies). - Add an
api-keyheader with your Azure API key. - All inference requests (completions, embeddings, chat/completions) require POST.
Keep your API key secure. Never commit keys to source control or expose them in client-side code. Rotate keys regularly and restrict usage with appropriate IAM policies.
Final notes and best practices
- Confirm the model you plan to use supports the required API type (completion, embedding, or chat).
- Use
max_tokens,temperature, andtop_pto control response length and randomness. - Track token usage via the response
usageobject to monitor costs. - For streaming responses, advanced control, or SDK usage, consult the official docs and your Foundry deployment settings.
- Azure OpenAI REST API reference: https://learn.microsoft.com/en-us/azure/cognitive-services/openai/reference
- Azure AI Fundamentals / Foundry docs: https://learn.microsoft.com/azure/ai-services/
- Kubernetes and containers (context for deployments & infra): https://kubernetes.io/docs/