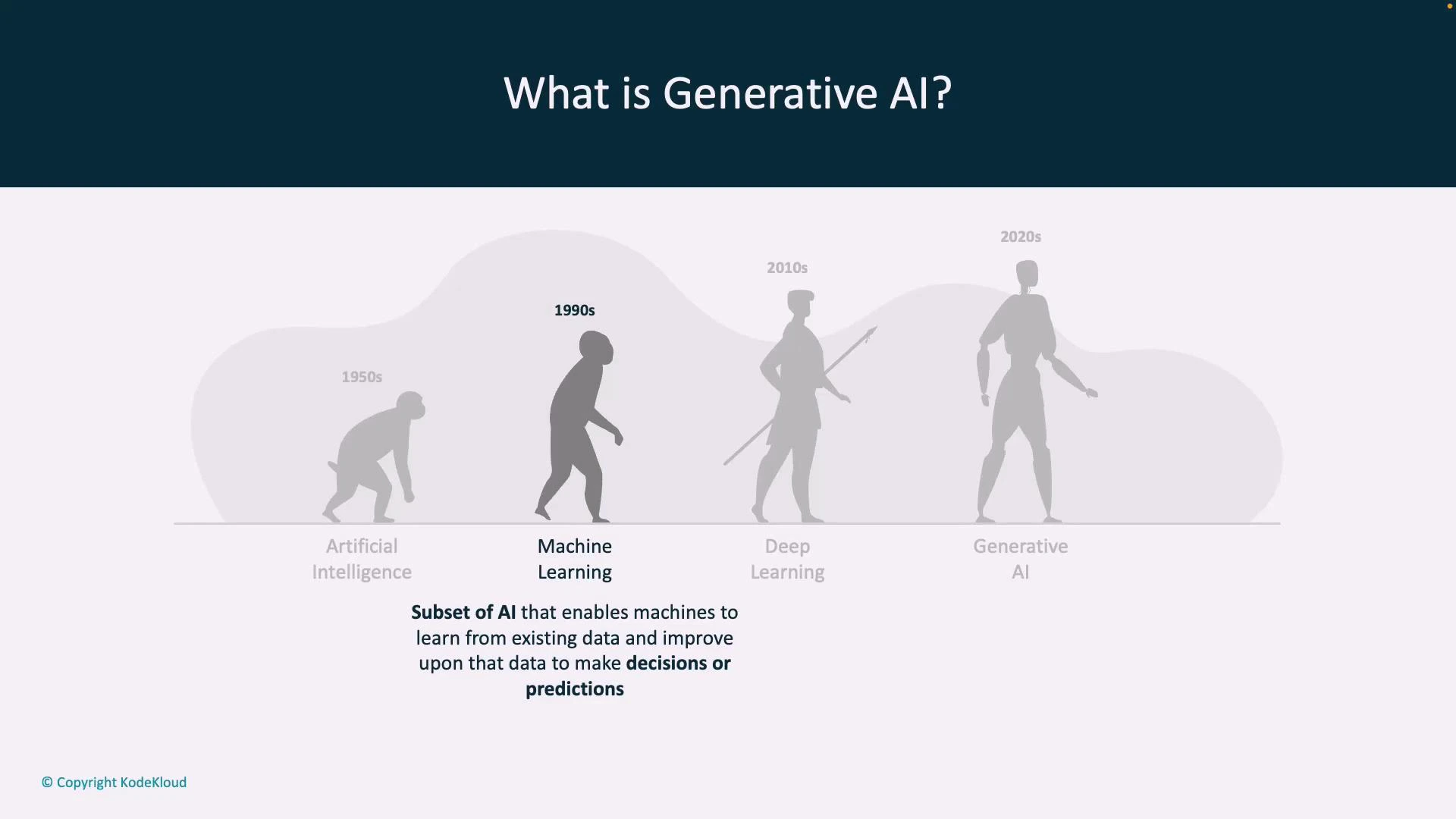
- 1950s — Classical AI: rule-based systems and symbolic reasoning intended to encode expert knowledge explicitly.
- 1990s — Machine Learning: statistical methods that learn patterns and relationships from data rather than relying solely on hand-coded rules.
- 2010s — Deep Learning: multilayer neural networks that learn hierarchical features from very large datasets, enabling breakthroughs in vision, speech, and language.
- 2020s — Generative AI: models that synthesize novel content (text, images, audio, code) by learning the distribution of training data and sampling from it.
- Traditional ML models are often discriminative: they classify or predict a label for input data (for example, “spam” vs “not spam”).
- Generative models learn an approximation of the full data distribution and can sample from that distribution to produce entirely new examples that resemble the training data.
- Variational Autoencoders (VAEs): learn latent representations and generate samples by decoding from the latent space.
- Generative Adversarial Networks (GANs): use a generator and discriminator in competition to produce highly realistic images and other media.
- Transformer-based models and Large Language Models (LLMs): use attention mechanisms and massive training corpora to generate coherent text and support tasks like summarization, translation, and code generation.
Generative models approximate the data distribution and produce novel—but statistically plausible—outputs when sampling from that learned distribution. This enables creation of new images, text, audio, or code that resemble the training examples.
- ChatGPT — conversational text generation and assistants. OpenAI ChatGPT
- DALL·E — image synthesis from text prompts. DALL·E
- GitHub Copilot — AI-assisted code completion and generation. GitHub Copilot
- Content creation: synthetic images, text drafts, music, and video.
- Code generation and automation: boilerplate, function suggestions, and auto-completion.
- Data augmentation: generating synthetic examples for training or simulation.
- Personalization: adapting content to user preferences at scale.
- Hallucinations: models may assert incorrect facts as if they are true.
- Biases: models can reproduce or amplify biases in their training data.
- Copyright and provenance: generated content may inadvertently reproduce copyrighted material. Careful validation, human-in-the-loop review, and responsible deployment are essential.
Generative AI is powerful but not infallible. Outputs can be factually incorrect, biased, or inappropriate—always validate and apply safeguards before using generated content in critical or public contexts.
Further reading and references
- Kubernetes Basics (general reference)
- OpenAI Documentation
- Transformer Models and Attention Mechanisms (Vaswani et al.)