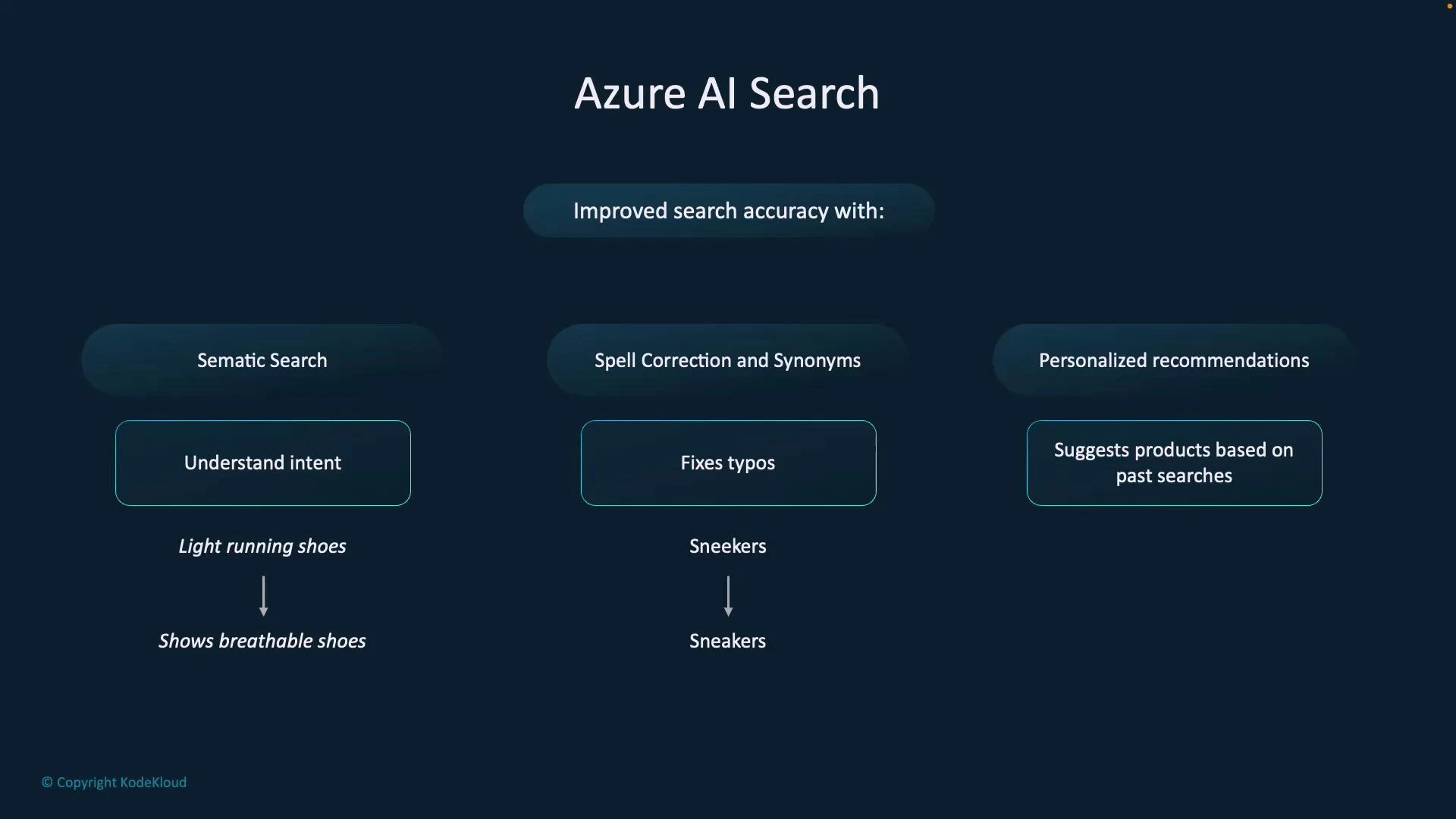
- Exact-match dependency: Traditional keyword search misses items when query terms don’t appear verbatim in product titles or descriptions.
- Typos and misspellings: Users often mistype (e.g., “shose” vs. “shoes”), leading to poor results.
- Vocabulary differences: Different users choose different words for the same concept (e.g., “athletic shoes” vs. “running sneakers”).
- Understands intent and contextual meaning rather than relying only on token frequency.
- Uses semantic ranking to order results by relevance to the user’s intent.
- Provides spelling correction and suggestions.
- Supports synonym maps so different terms map to the same concepts.
- Integrates with personalization services (for example, Azure Personalizer) and user behavior signals to surface relevant products and increase engagement and conversion.
- Higher conversions: Improved product discovery and relevance frequently yield double-digit uplifts depending on scenario and tuning.
- Faster, more relevant results: Reduced search friction improves UX, engagement, and lowers abandonment.

- Ingest content from Azure Blob Storage, SQL databases, Cosmos DB, or flat JSON files.
- Apply built-in or custom AI enrichments (cognitive skills) to extract key phrases, detect language, perform sentiment analysis, run OCR on images, and identify entities like people, places, and product attributes.
- Persist enriched outputs in structured formats for downstream analytics, relevance tuning, or integration with other applications.

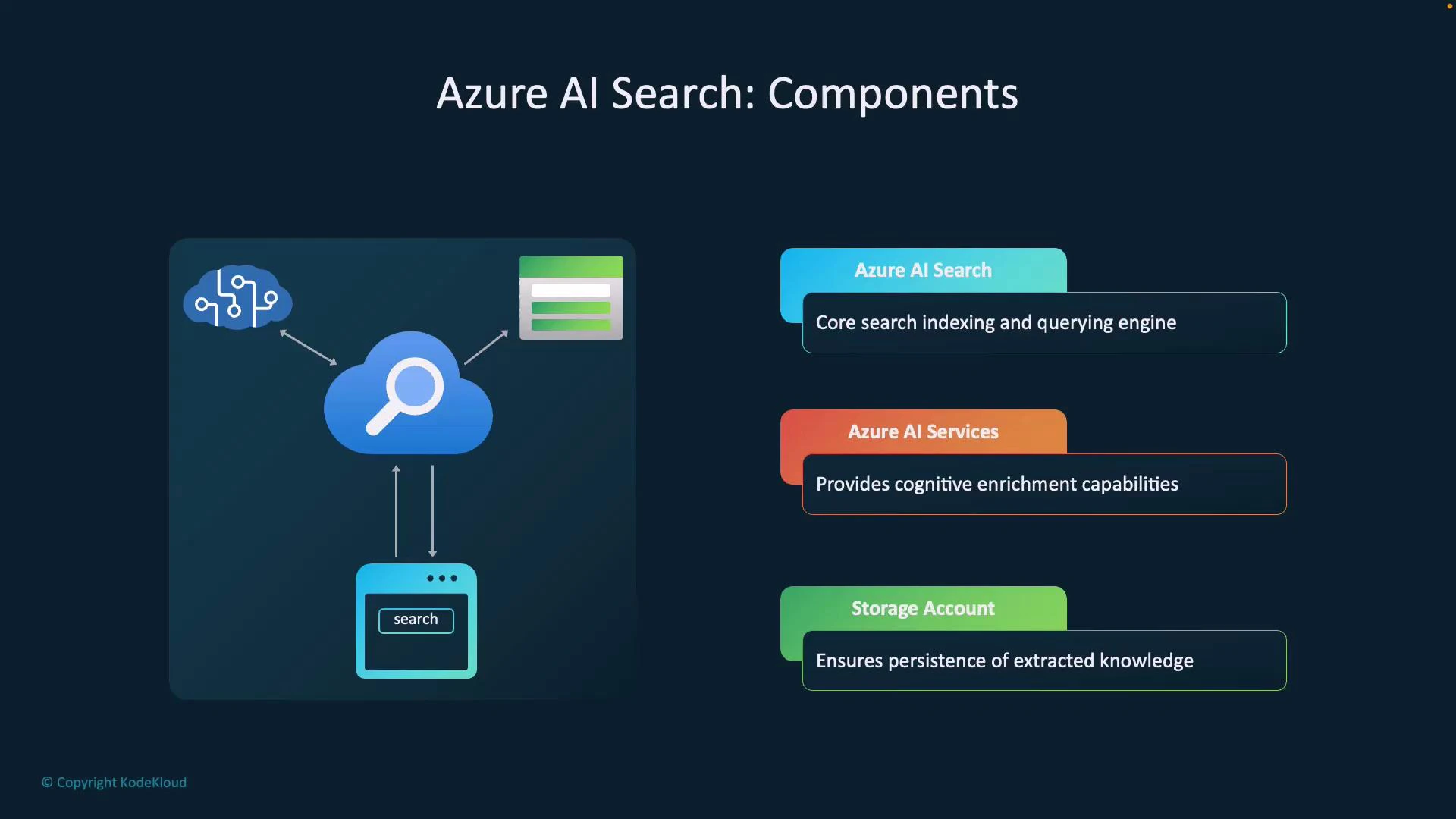
- AI Search (core): Indexing and query engine that stores documents and serves search requests.
- Azure AI Services / cognitive skills: Optional AI enrichments used during indexing to extract meaning from unstructured content.
- Storage account: Persists intermediate and final artifacts (enriched documents, knowledge store outputs) for durability and reprocessing.
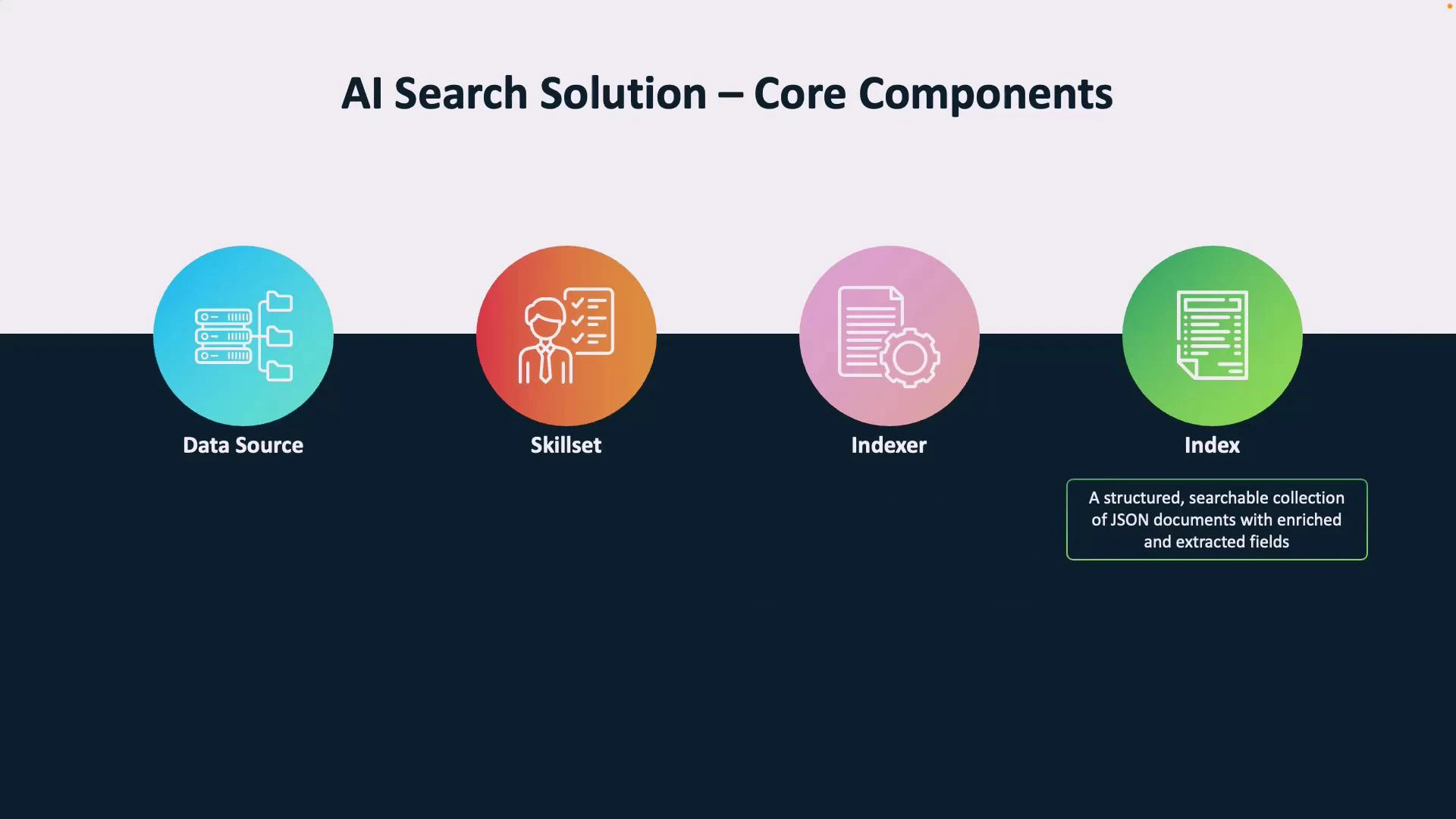
- Data source: Where raw content resides — Azure Blob Storage, Cosmos DB, SQL, or uploaded JSON. This is the indexing origin.
- Skillset: A sequence of AI enrichments (built-in cognitive skills or custom skills) to extract entities, detect language, perform OCR, sentiment analysis, or other transformations.
- Indexer: Orchestrates fetching data from the data source, applies the skillset, and writes enriched documents to the index. Indexers run on schedules, on demand, or can be event-driven (Event Grid, Azure Functions).
- Index: The final searchable artifact — a structured collection of JSON documents with enriched and extracted fields.
Design indexes with query patterns in mind: choose which fields are searchable, retrievable, facetable, filterable, and sortable to balance relevance and performance.
- Configure your data source (Blob, SQL, Cosmos DB, or JSON upload).
- Create a skillset to enrich content (built-in or custom cognitive skills).
- Point an indexer at the data source and attach the skillset.
- Optionally persist enriched artifacts to a knowledge store (Storage Account).
- Index the structured documents into an index.
- Query the index via the Search API using semantic ranking, filters, facets, and personalized signals.