Never hard-code secrets (endpoint, keys) in production code. Store credentials in environment variables or a secure secrets store and load them at runtime.
For local testing, put your Azure Language endpoint and key in environment variables (or a .env file) and load them at runtime. The samples below assume you already have those values available.
At-a-glance: capabilities and common SDK methods
For full API reference and details about model versions, see the Azure AI Language Service documentation: https://learn.microsoft.com/azure/cognitive-services/language-service/
Language detection
Detects the language of a text and returns a confidence score. It supports automatic detection across many scripts (Latin, Arabic, Chinese, etc.). You can optionally provide a country hint to influence detection, but it is not required.
Key phrase extraction
Extracts prominent words and short phrases (topics) from text. This is helpful for search indexing, content tagging, and summarization—best applied to longer passages.
Sentiment analysis
Classifies documents (and sentences) as positive, neutral, negative, or mixed and returns confidence scores. Useful for product feedback, social-media analysis, and customer support automation.
Named entity recognition (NER)
NER extracts entities such as people, organizations, locations, datetimes, addresses, emails, and URLs from text. Use this to populate structured metadata, build knowledge graphs, or enhance search relevance.
Entity linking
Entity linking (or entity resolution) maps recognized mentions to entries in an external knowledge base (for example, Wikipedia). This disambiguates mentions such as “Paris” (city) vs “Paris” (person) and provides authoritative metadata (IDs and URLs).
Summarization
Summarization creates concise representations of long documents. You can choose:- Extractive summarization — select the most important sentences verbatim.
- Abstractive summarization — generate a rewritten, shorter summary.

Personally Identifiable Information (PII) detection and redaction
PII detection identifies sensitive data such as names, phone numbers, emails, and Social Security numbers. After detection you can redact or mask values to help meet privacy and compliance requirements (for example, GDPR or HIPAA).
Example: single Flask app that runs multiple analyses
You can combine multiple analyses in a single application, keeping each call focused and handling errors per document. The example below shows how to load credentials, initialize a client, and call several analyzers (language, key phrases, sentiment, NER, entity linking, and PII) from a Flask route. This compact pattern is suitable for demos and small apps — for production, add proper error handling, rate limiting, and secrets management.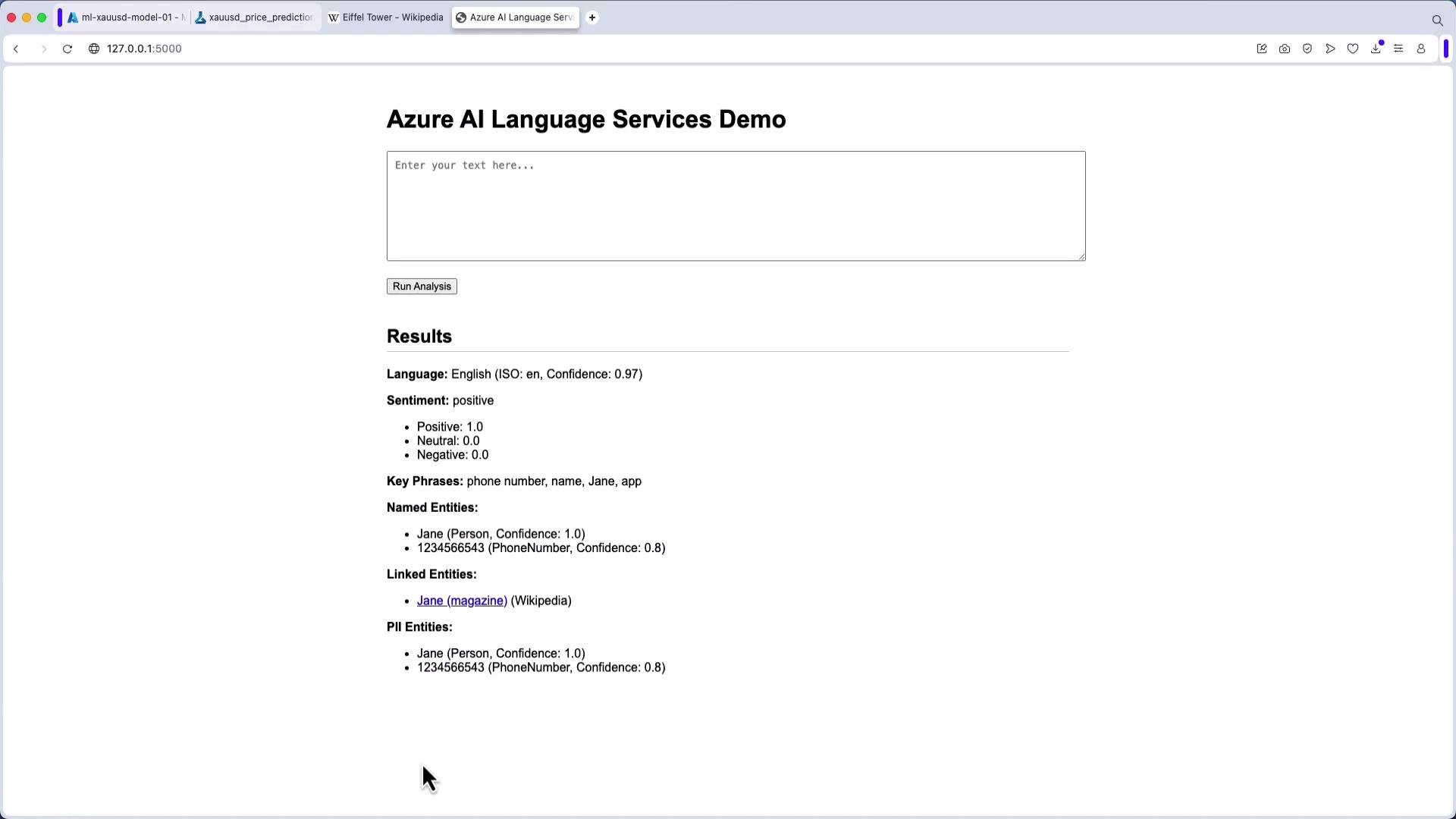
Best practices
- Never embed secrets in code. Use environment variables or a secret store.
- Validate and sanitize inputs (especially if integrating with user-generated content).
- Use batch processing for high-throughput scenarios and handle rate limits.
- For compliance, store and handle redacted data according to your organization’s privacy policies.
- Check model/version and SDK docs as behavior and method names can change over time.
Links and references
- Azure AI Language Service documentation: https://learn.microsoft.com/azure/cognitive-services/language-service/
- Azure SDK for Python (Text Analytics package): https://pypi.org/project/azure-ai-textanalytics/
- GDPR overview: https://gdpr.eu
- HIPAA information: https://www.hhs.gov/hipaa/index.html