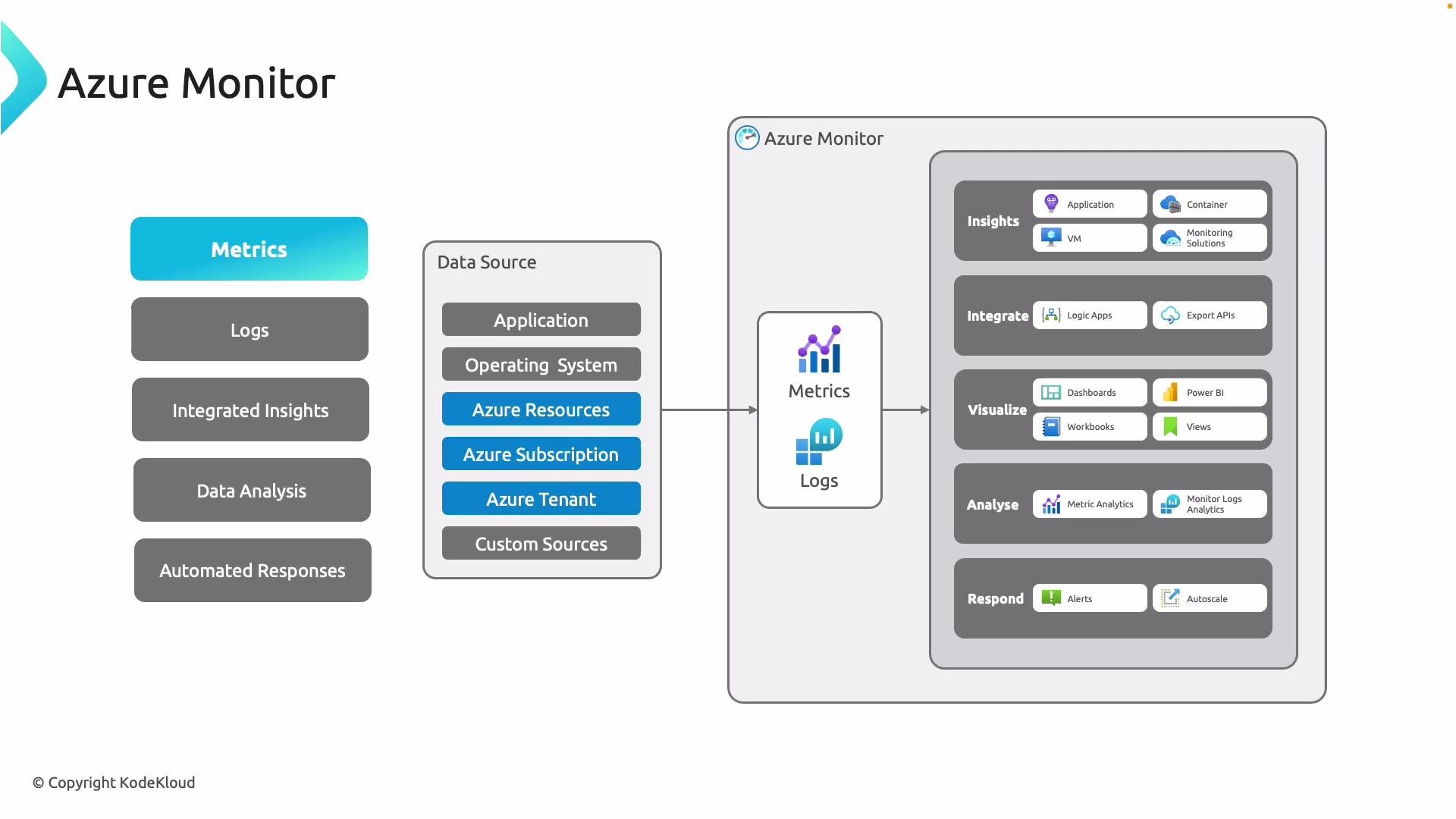
Core capabilities
- Metrics: lightweight numeric data points collected at short intervals (CPU, memory, network). Great for real-time dashboards and alerting.
- Logs: rich event and diagnostic records (traces, exceptions, audit events) stored in Log Analytics for advanced querying and long-term retention.
- Insights & integration: built-in experiences for applications, VMs, containers, networking, and hybrid systems. Use dashboards, workbooks, Log Analytics, and Metrics Explorer to visualize and correlate data. Alerts can trigger automated remediation—scale, restart, notify, or run playbooks.
Metrics vs Logs — quick comparison
Metrics Explorer
Metrics Explorer is the primary UI for graphing real-time and historical metrics. Use it to detect patterns (latency spikes, packet drops), compare resources, and build KPIs (e.g., firewall dropped packets, SQL MI transaction latency).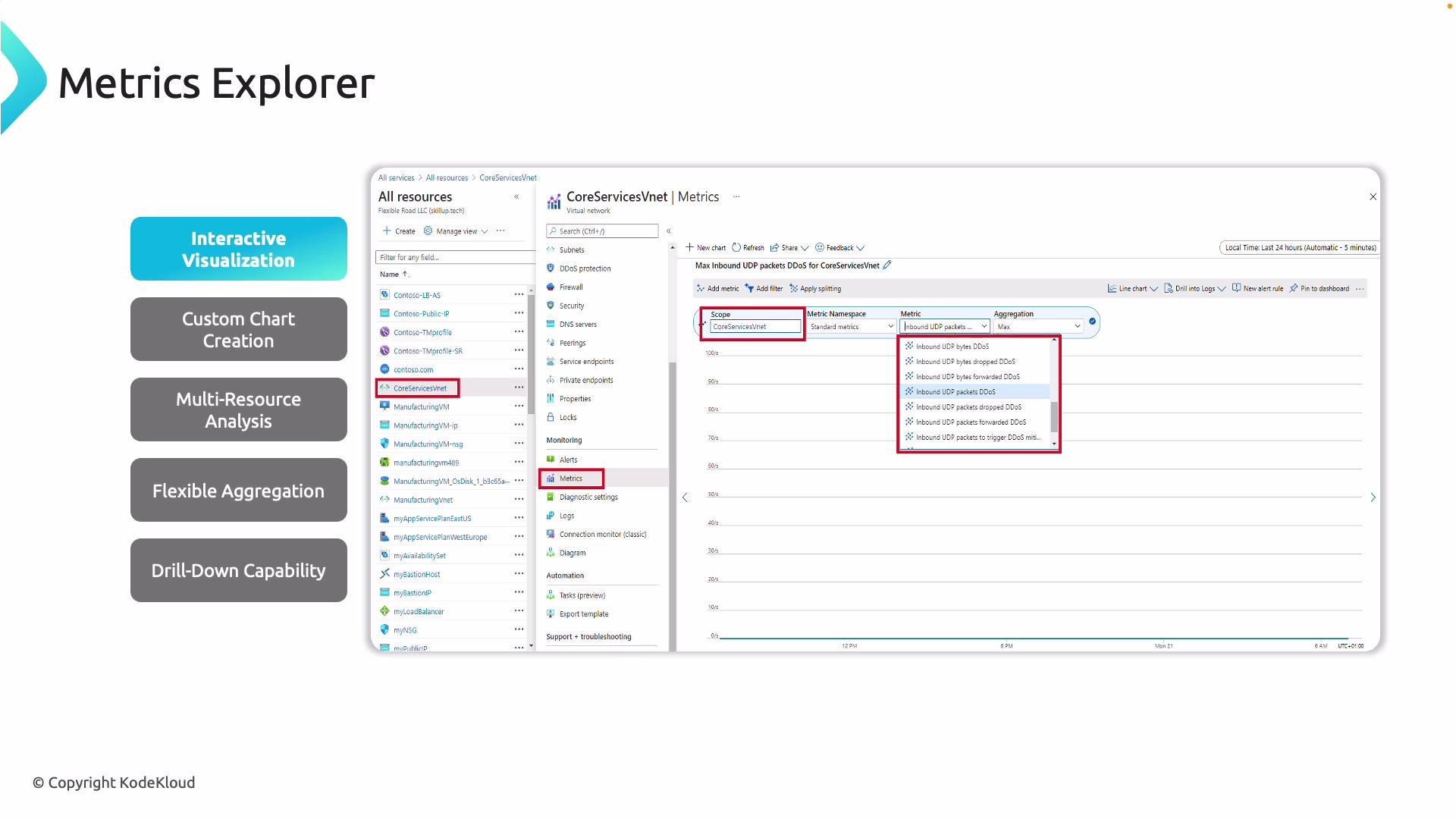
- Compare metrics across multiple resources (throughput across VNets, VM CPU across a pool).
- Use aggregations: Sum, Average, Min, Max, Count.
- Drill into specific time ranges for root-cause analysis (e.g., investigate a five-minute window during a DDoS event).
- Save charts to dashboards, create alert rules from charts, and change visualization types (line, area, stacked).
Accessing Metrics Explorer in the Azure portal
Most Azure resources expose a Monitoring blade where you can launch Metrics (Metrics Explorer). You can open Metrics either directly from a resource (resource-scoped metrics) or from the Azure Monitor blade for cross-resource analysis.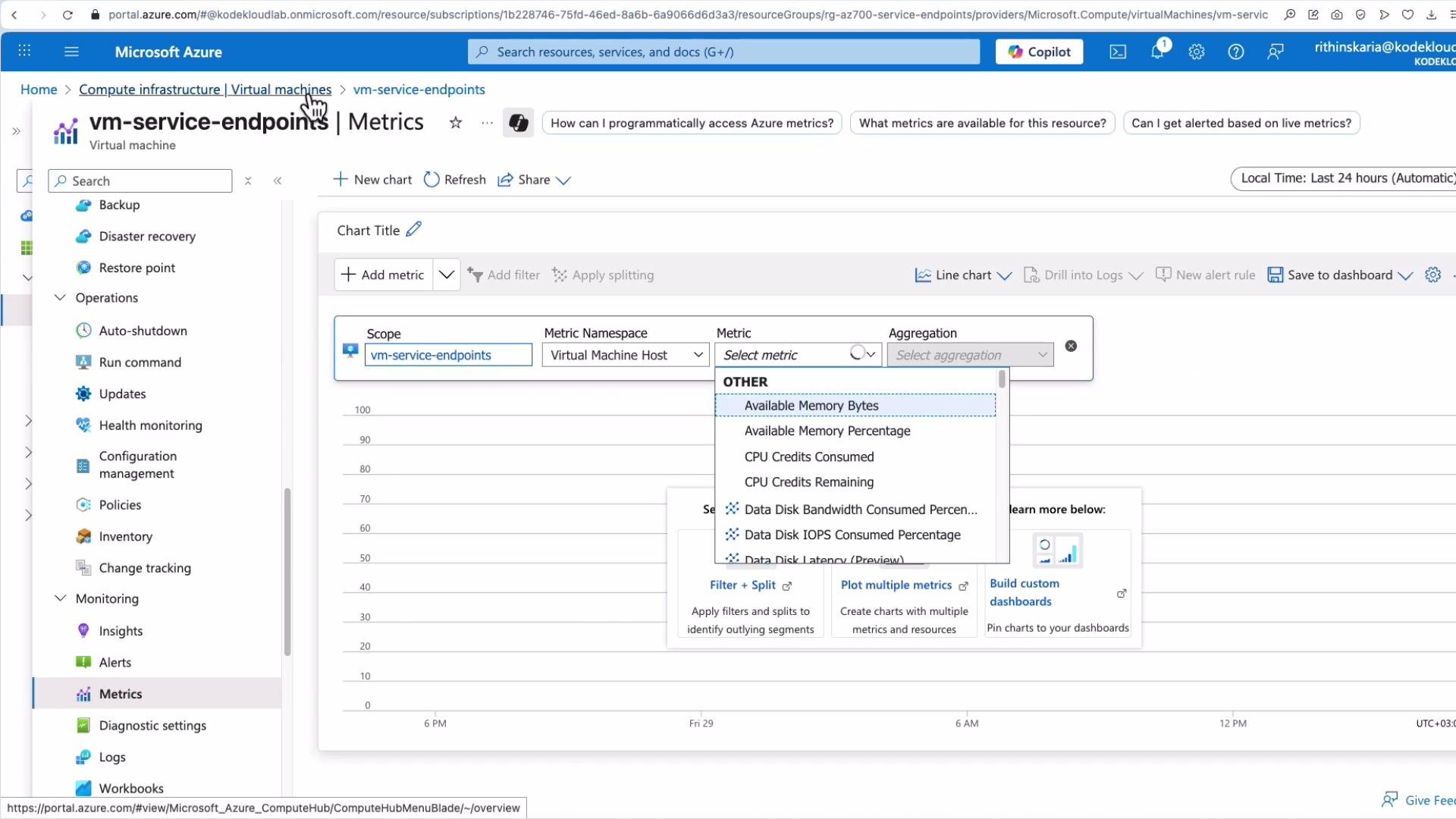
- Open a resource (for example, a virtual machine) in the Azure portal.
- From the Monitoring blade, choose Metrics to open Metrics Explorer for that resource.
- Search for a metric such as
Percentage CPUand select an aggregation (Average, Max, etc.). - Add another metric like
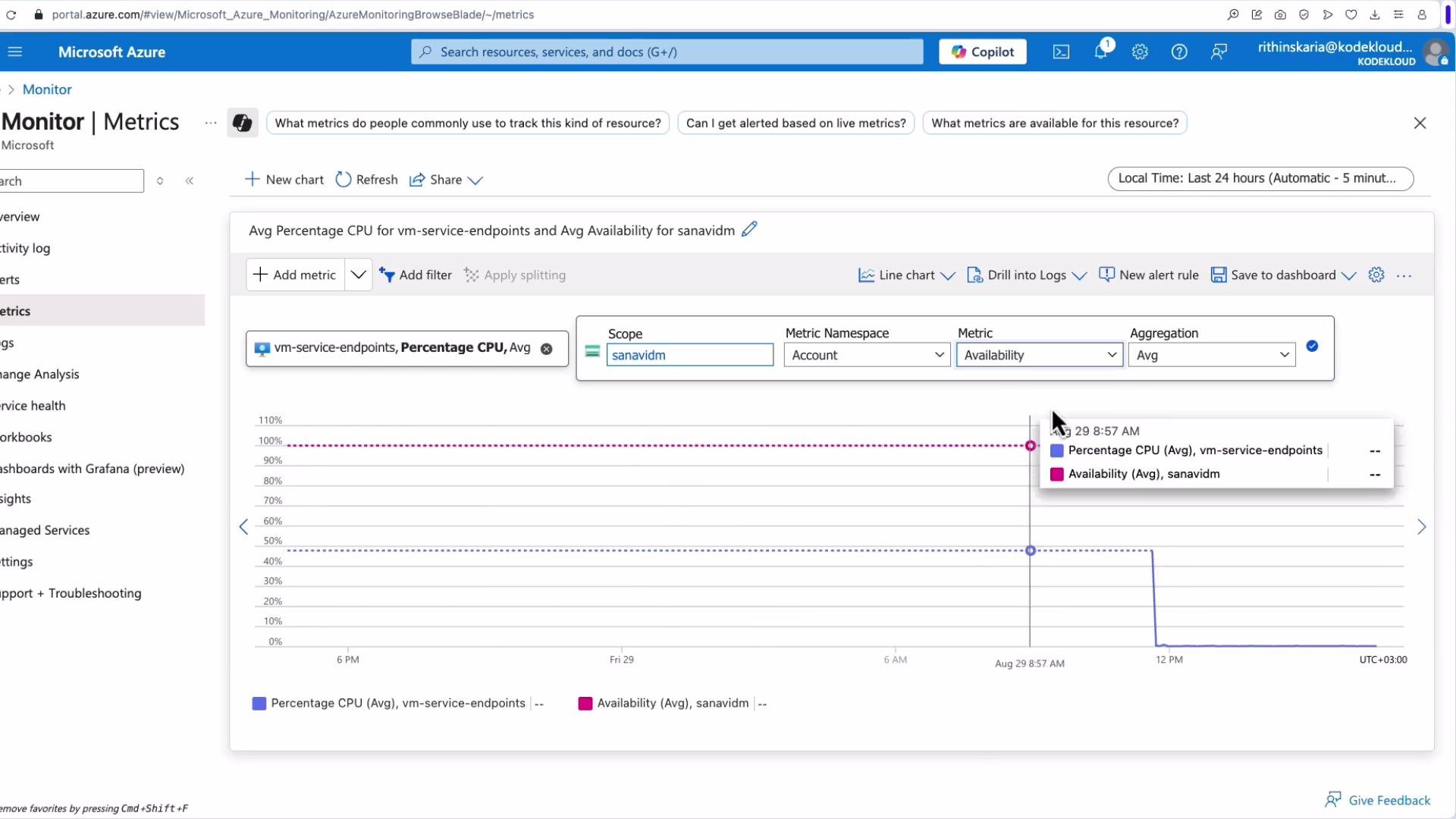
Available Memory %to plot multiple series on the same chart. - For cross-resource analysis, go to Azure Monitor > Metrics and select resources across subscriptions or resource groups—plot VM CPU alongside VNet or storage metrics.
Diagnostics, Logs, and destinations
Platform metrics are useful out of the box but are retained for a limited period. To capture diagnostic logs or retain data beyond default retention, configure Diagnostic settings per resource. Diagnostics let you select log and metric categories (which vary by resource) and route them to destinations for analysis or archival.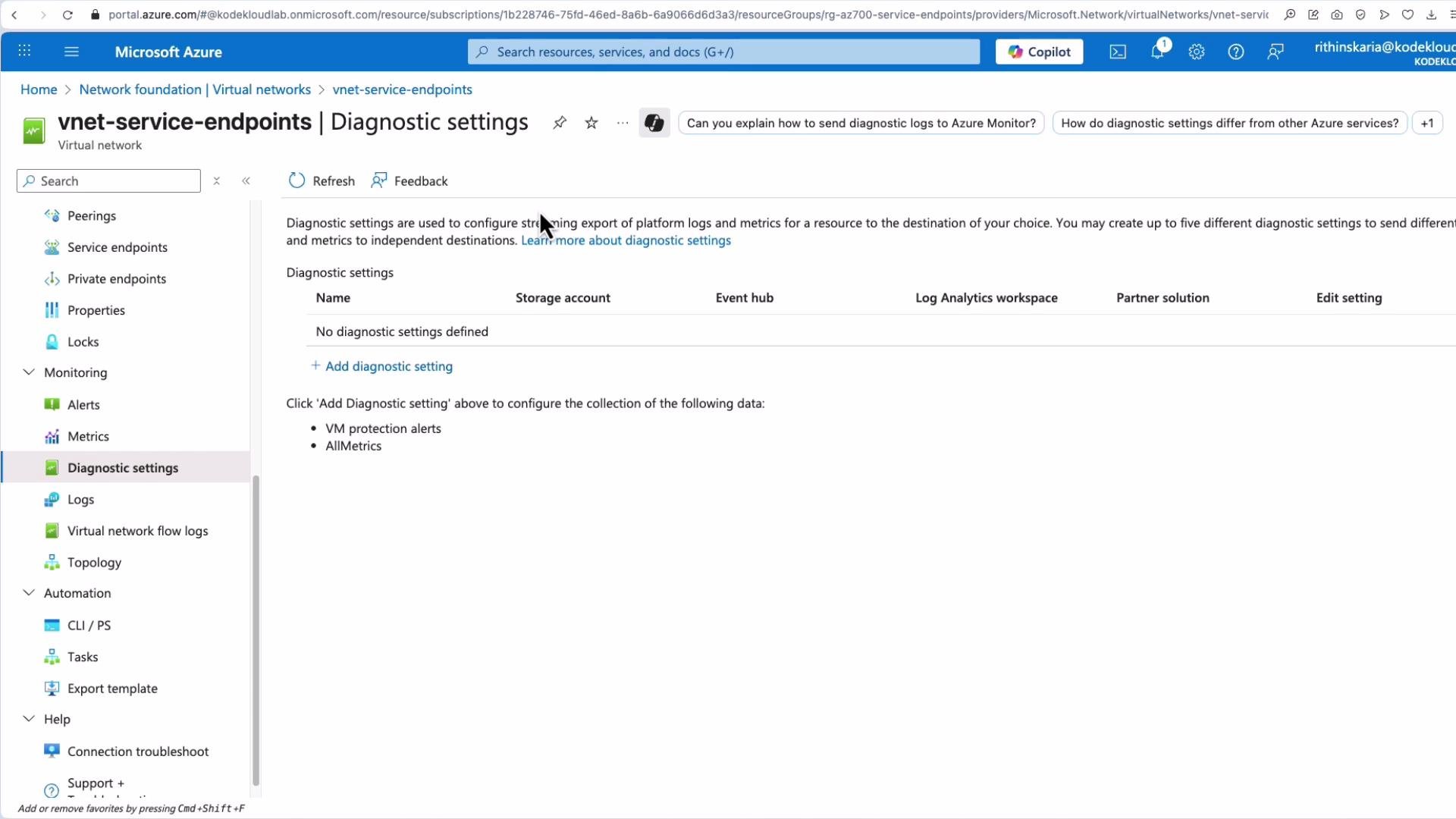
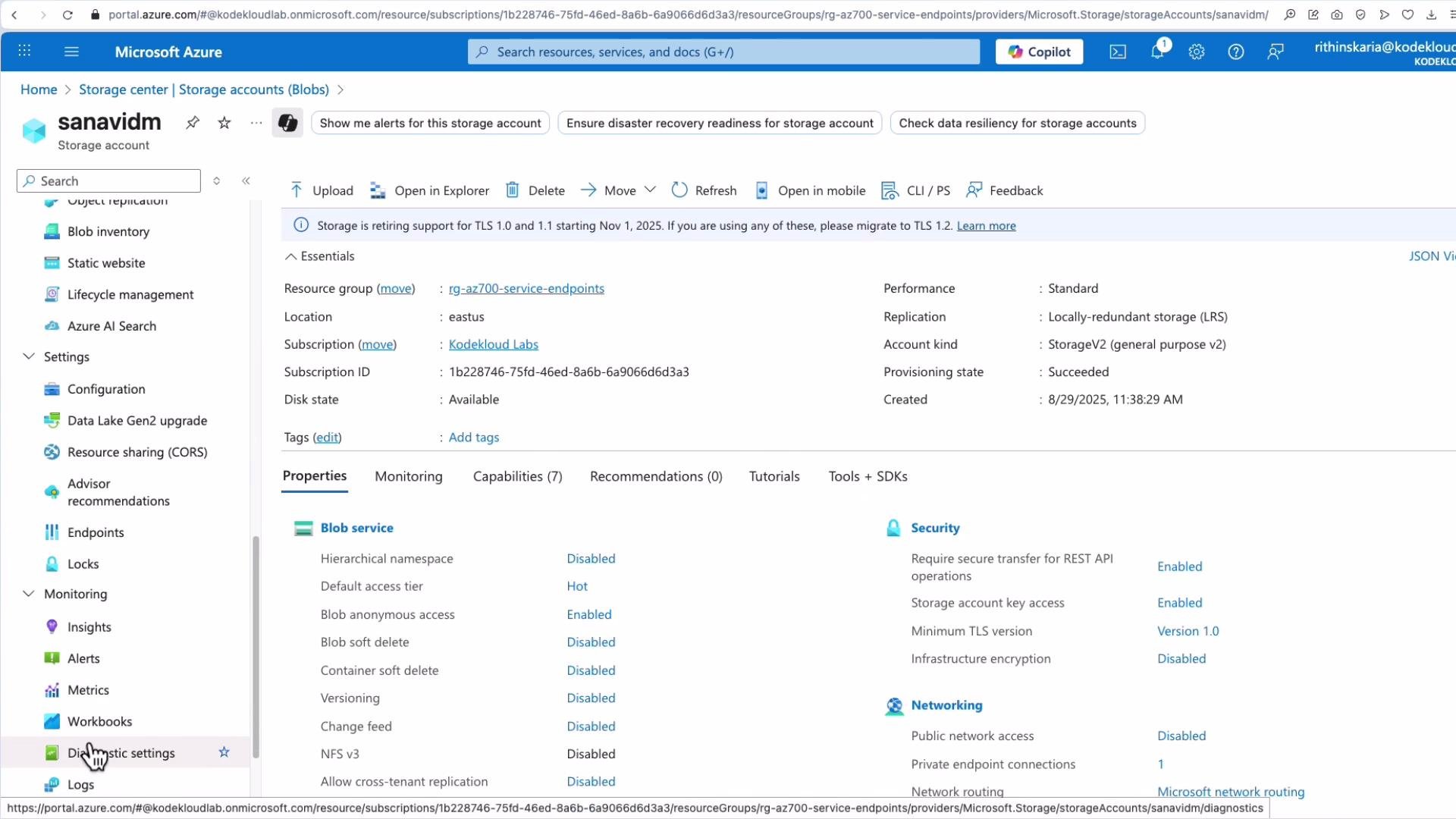
StorageRead, StorageWrite, StorageDelete), transaction metrics, and audit logs, then send them to a destination of your choice.
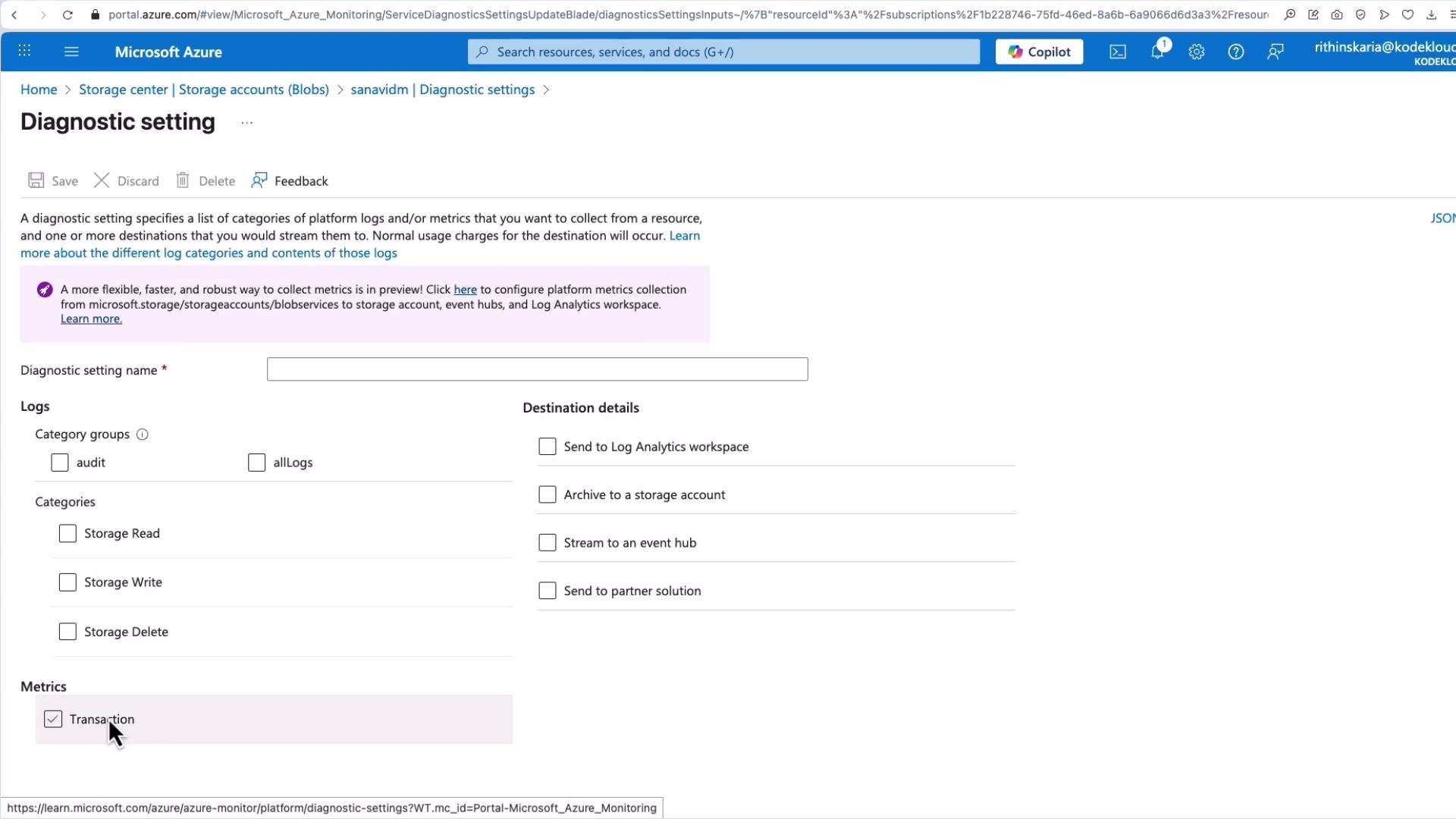
Metrics in Metrics Explorer are available out-of-the-box (typically with a 90-day view). For longer retention or advanced queries, send diagnostics to a Log Analytics workspace, a storage account for archival, or Event Hubs for streaming to external systems.
Next steps and recommended learning path
- Configure Diagnostic settings for resource types that matter to your service-level objectives (NSG flow logs, VM guest diagnostics, storage analytics).
- Build dashboards and workbooks to visualize KPIs and correlate metrics with logs.
- Create alert rules from metrics and logs to automate responses (auto-scale VMs, trigger runbooks, notify teams).
- Learn Log Analytics and Kusto Query Language (KQL) for powerful cross-resource analysis and threat hunting.
- Azure Monitor overview: https://learn.microsoft.com/azure/azure-monitor/
- Log Analytics and KQL: https://learn.microsoft.com/azure/data-explorer/kusto/query/
- Metrics and Metrics Explorer: https://learn.microsoft.com/azure/azure-monitor/essentials/metrics-overview