- Batch processing collects and processes data in periodic, large chunks.
- Streaming processing ingests and processes data continuously in small increments, close to real time.
-
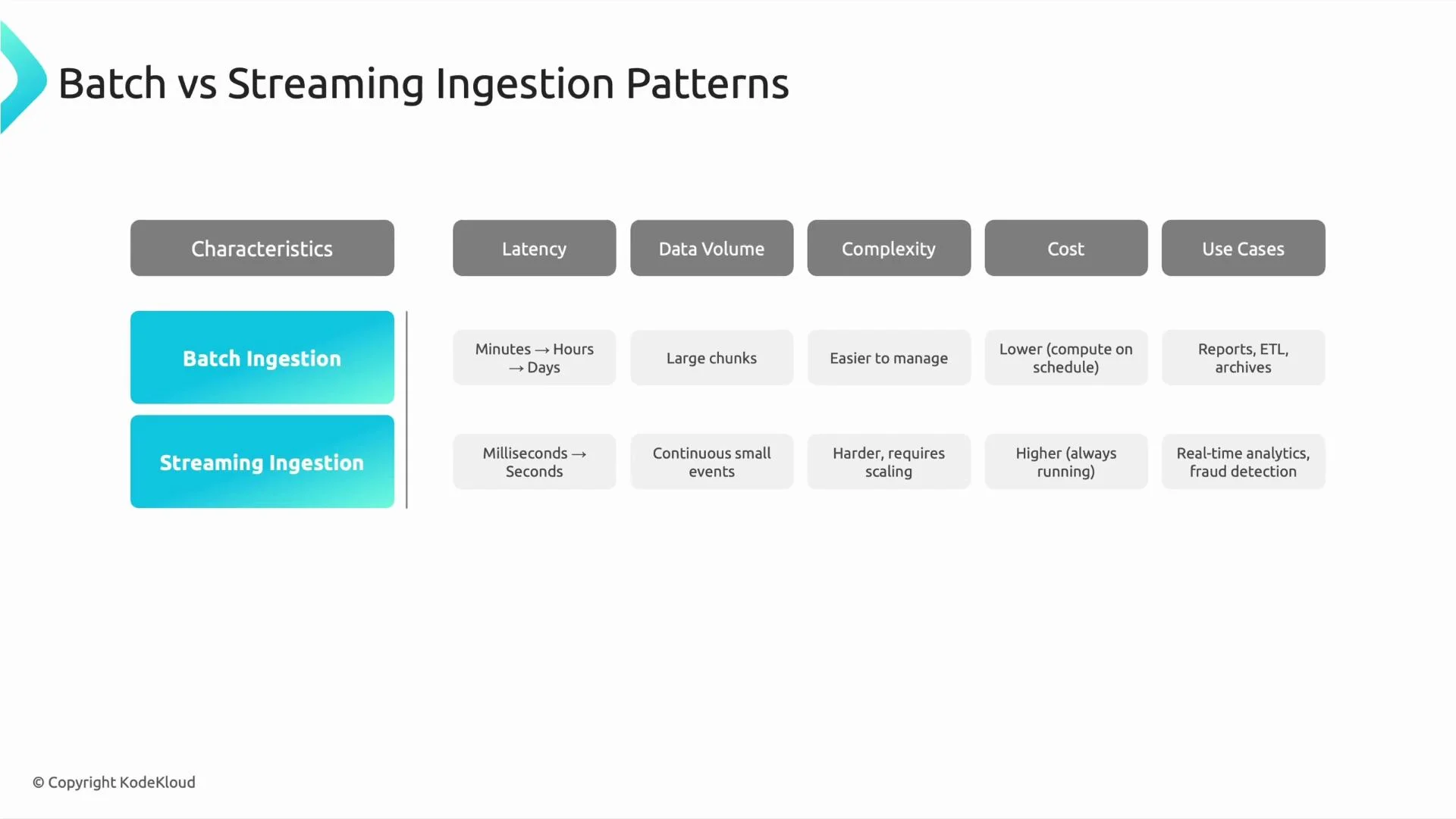
Latency
- Batch: Acceptable when results can wait until the next scheduled run (e.g., daily aggregates). Processing time is dominated by I/O and large-volume transformations.
- Streaming: Required for low-latency needs where decisions must be made immediately (monitoring, live dashboards, alerts).
-
Data volume and throughput
- Batch: Efficient for high-throughput bulk operations (e.g., monthly billing exports or archival ingestion).
- Streaming: Optimized for steady event rates or bursty small messages; scales horizontally for high-throughput event streams.
-
Complexity and correctness
- Batch: Easier to reason about — deterministic runs, straightforward retries, and simple recovery patterns.
- Streaming: Requires handling out-of-order events, duplicates, windowing, and long-running state. Checkpointing and state management are essential.
-
Cost and resource utilization
- Batch: Lower compute cost when jobs run on schedule and resources are de-provisioned otherwise.
- Streaming: Continuous resource allocation and autoscaling needs can increase cost; evaluate trade-offs against latency requirements.
- Batch examples:
- Summarize website traffic daily to generate aggregated reports.
- Monthly billing and invoicing runs.
- Bulk ETL jobs and cold data archival.
- Streaming examples:
- Process clickstream events to power real-time personalization.
- Monitor live stock prices for trading systems.
- Real-time fraud detection and alerting on payment events.
- Choose batch if:
- Results are tolerant of minutes/hours/days of delay.
- You need simpler operational models and easier reprocessing.
- Workloads are periodic and process large volumes at once.
- Choose streaming if:
- You need sub-second to second latency for decisions or user experiences.
- You require continuous processing of events and immediate alerting.
- You must support real-time analytics, monitoring, or fraud detection.
- Consider hybrid when:
- You want immediate insights via streaming and reliable, complete historical processing via batch (e.g., stream-first analytics + nightly reconciliation).
- Tightly coupled streaming: Producers push directly to processing and storage for minimal end-to-end latency.
- Loosely coupled streaming: Use durable message brokers (e.g., Pub/Sub, Kafka) to decouple producers and consumers for resilience and replayability.
- Lambda / Hybrid: Combine a streaming layer for real-time needs and a batch layer to compute comprehensive, recomputed views for correctness.
Many production architectures combine batch and streaming: stream for immediate insights and batch to reprocess or reconcile historical data for correctness and completeness.
Streaming systems are powerful but add operational overhead: expect to manage state, ensure fault tolerance, and handle out-of-order or duplicate events. Plan for monitoring, checkpointing, and replay strategies.
- Google Cloud Pub/Sub: https://cloud.google.com/pubsub
- Apache Kafka: https://kafka.apache.org/
- Apache Beam (unified batch & streaming model): https://beam.apache.org/
- Google Cloud Dataflow (Apache Beam runner): https://cloud.google.com/dataflow
- Change Data Capture (CDC) patterns (Debezium): https://debezium.io/
- Explore how streaming ingestion platforms are implemented on GCP, focusing on Pub/Sub, Dataflow, and how to design tightly coupled vs loosely coupled topologies for scalability and reliability.
- Prototype a small streaming pipeline and a batch job for the same dataset to compare operational trade-offs (latency, cost, accuracy).
- Review monitoring and alerting strategies for streaming (latency SLOs, processing lag, checkpoint health).