- How functions respond to Cloud Storage uploads for ETL and analytics.
- How Firestore change events enable near-real-time analytics.
- How Pub/Sub + Functions validate and process IoT telemetry.
- How an HTTP-triggered function behind API Gateway supports serverless APIs.
We’ll step through each pattern and show concise example code and architecture notes so you can adapt them to production.
1) File upload processing (Cloud Storage → Function → BigQuery)
Scenario Support tools and automated agents upload car diagnostic logs to Cloud Storage. A Cloud Function triggers on object creation and implements validation, transformation (e.g., CSV → newline-delimited JSON), enrichment (attach metadata), and ingestion into BigQuery for analytics. Why use Cloud Functions here- Automatic, event-driven processing on file arrival.
- Fast, scalable, pay-per-execution model.
- Great for lightweight ETL or invoking a pipeline (e.g., Dataflow) for heavier loads.
- Use content-based deduplication or object metadata to ensure idempotency.
- For large files, trigger a Dataflow job via Cloud Functions rather than processing inline.
- Monitor function retries and error logs; consider a dead-letter bucket.

2) Database change streaming (Firestore → Function → Analytics Pipeline)
Scenario A customer updates contact info or a service-request status in the mobile app. Firestore triggers on document create/update/delete and a Cloud Function reacts to sanitize/enrich the change and push the record into an analytics store such as BigQuery. Why this pattern- Keeps analytics and downstream systems up-to-date without polling.
- Enables event-driven enrichment and fan-out (e.g., publish to Pub/Sub, call external APIs).
- Design idempotent writes (use stable document IDs or dedup keys).
- Consider partial updates and schema evolution — use versioned schemas or schema-checking libraries.
- Use IAM to limit which services can trigger or read data.
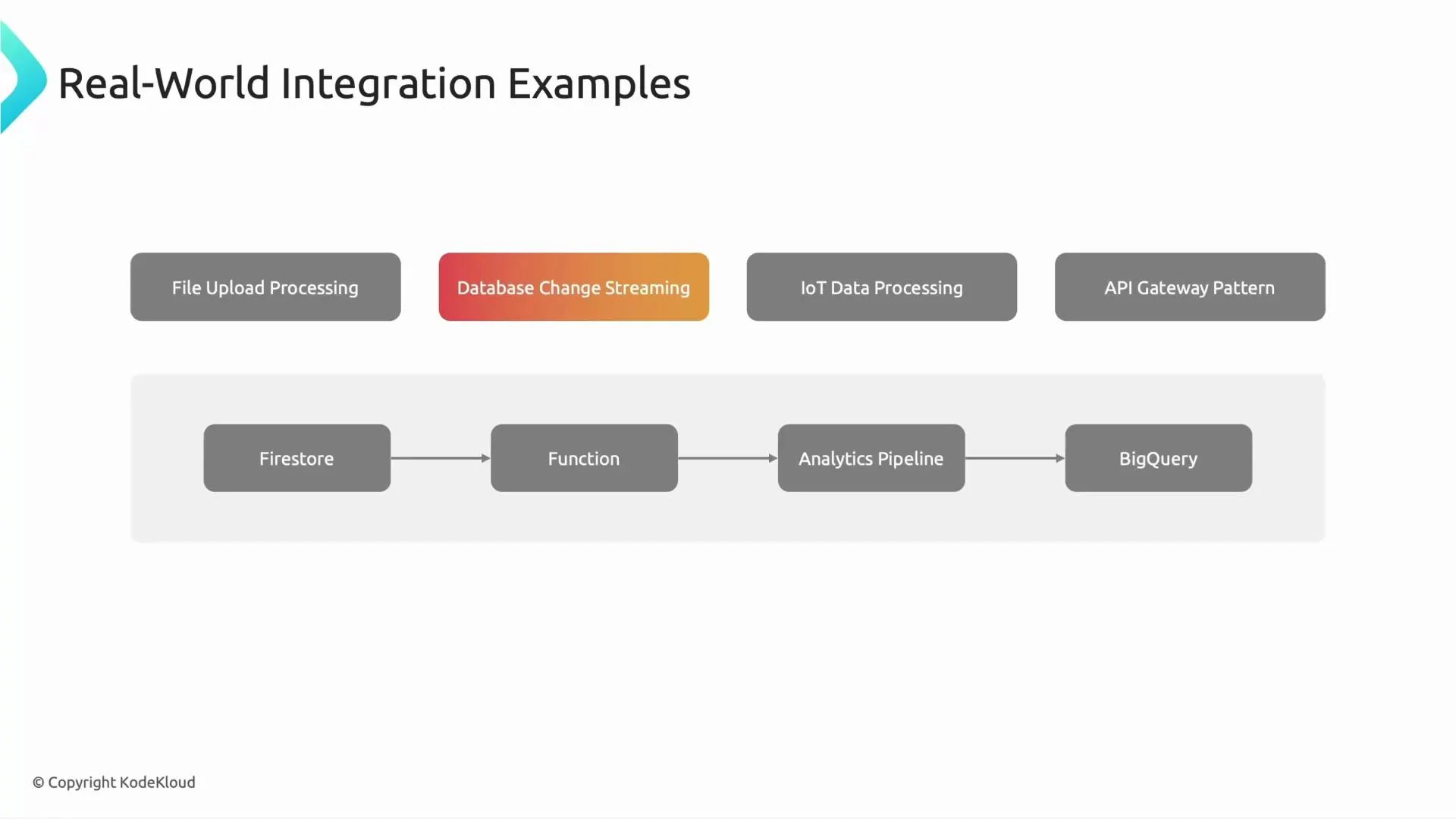
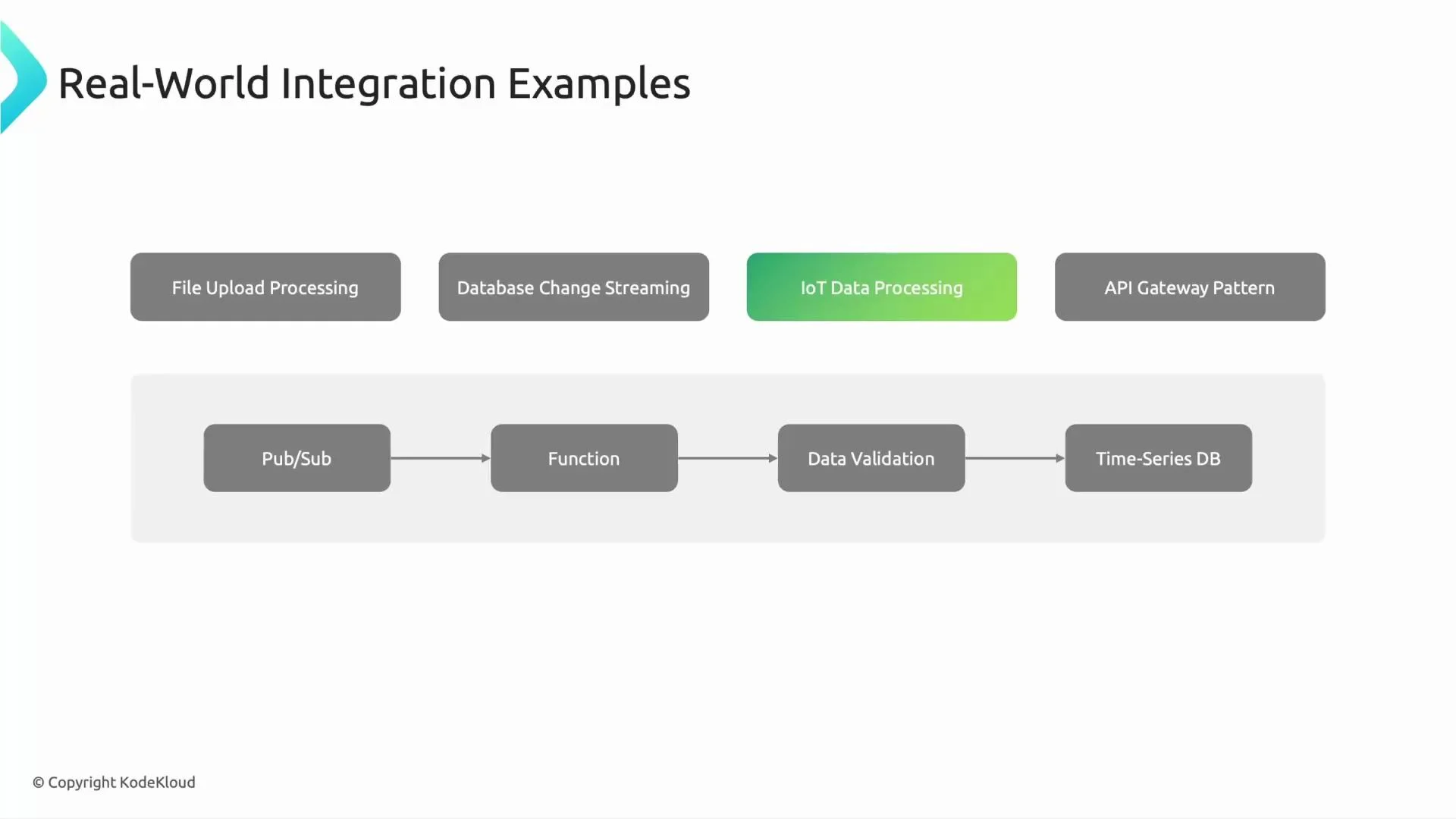
3) IoT / Telemetry processing (Pub/Sub → Function → Time-series DB)
Scenario Cars stream telemetry messages (sensor readings, battery metrics, GPS) to Pub/Sub. Cloud Functions subscribe to those topics, validate incoming messages (timestamps, schema), run anomaly detection or filtering, and store the cleaned data in a time-series store (Cloud Bigtable or a managed time-series solution) for monitoring and predictive maintenance. Why this pattern- Pub/Sub handles high-throughput ingestion and backpressure.
- Functions provide lightweight, scalable compute for validation and enrichment.
- Enables near-real-time alerts on anomalies (e.g., sudden temp spikes).
- Use message attributes and ordering keys when sequence matters.
- Configure retry/backoff policies and dead-letter topics for poison messages.
- Choose storage based on query patterns: Bigtable for high-volume point reads, BigQuery for analytics.
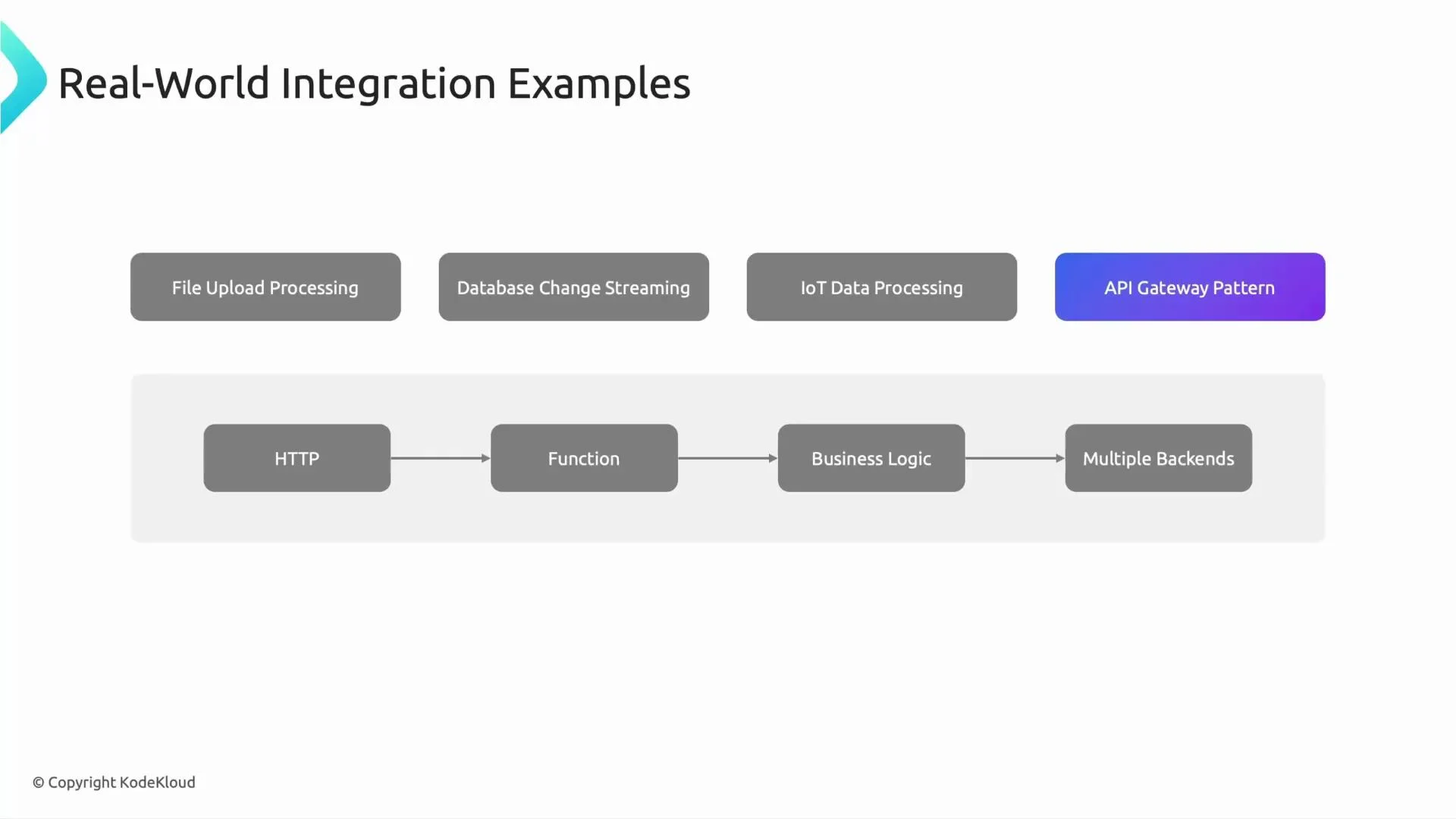
4) API Gateway pattern (API Gateway → HTTP Function → Multiple Backends)
Scenario A mobile app asks, “Show me the nearest Tesla service station with availability tomorrow.” The request routes through API Gateway to an HTTP-triggered Cloud Function, which aggregates availability, location, and user preference services, applies authorization and rate limiting, and returns the combined response. Why this pattern- Serverless APIs with integrated authentication, monitoring, and routing via API Gateway.
- Functions allow flexible orchestration across multiple backends without managing servers.
- Good for low-latency, lightweight orchestration logic.
- Use API Gateway for routing, security (API keys, JWT), and quota enforcement.
- Implement caching for expensive backend calls where freshness allows.
- Monitor latency and cold-starts; consider keeping critical functions warm or using newer runtimes with lower cold-start times.
Summary: Key considerations for production-ready Cloud Functions
- Idempotency: Design functions so repeated invocations don’t cause duplicates.
- Retry semantics: Understand automatic retries (e.g., Pub/Sub vs. HTTP) and use dead-letter topics/buckets if needed.
- Authentication & Authorization: Use IAM, API Gateway, and service accounts to limit access.
- Schema validation: Validate inputs early (JSON Schema, Protobuf) to avoid downstream failures.
- Observability: Export structured logs, set up traces, and instrument metrics and alerts.
- Cost & performance: Choose between inline processing, batching, or delegating to Dataflow/BigQuery for heavy workloads.
When designing these integrations, consider idempotency, retry semantics, authentication/authorization, schema validation, and monitoring so your workflows stay reliable and maintainable.