- Which features keep players most engaged?
- What are the patterns for in-app purchases?
- How can we personalize the player experience in near real time?
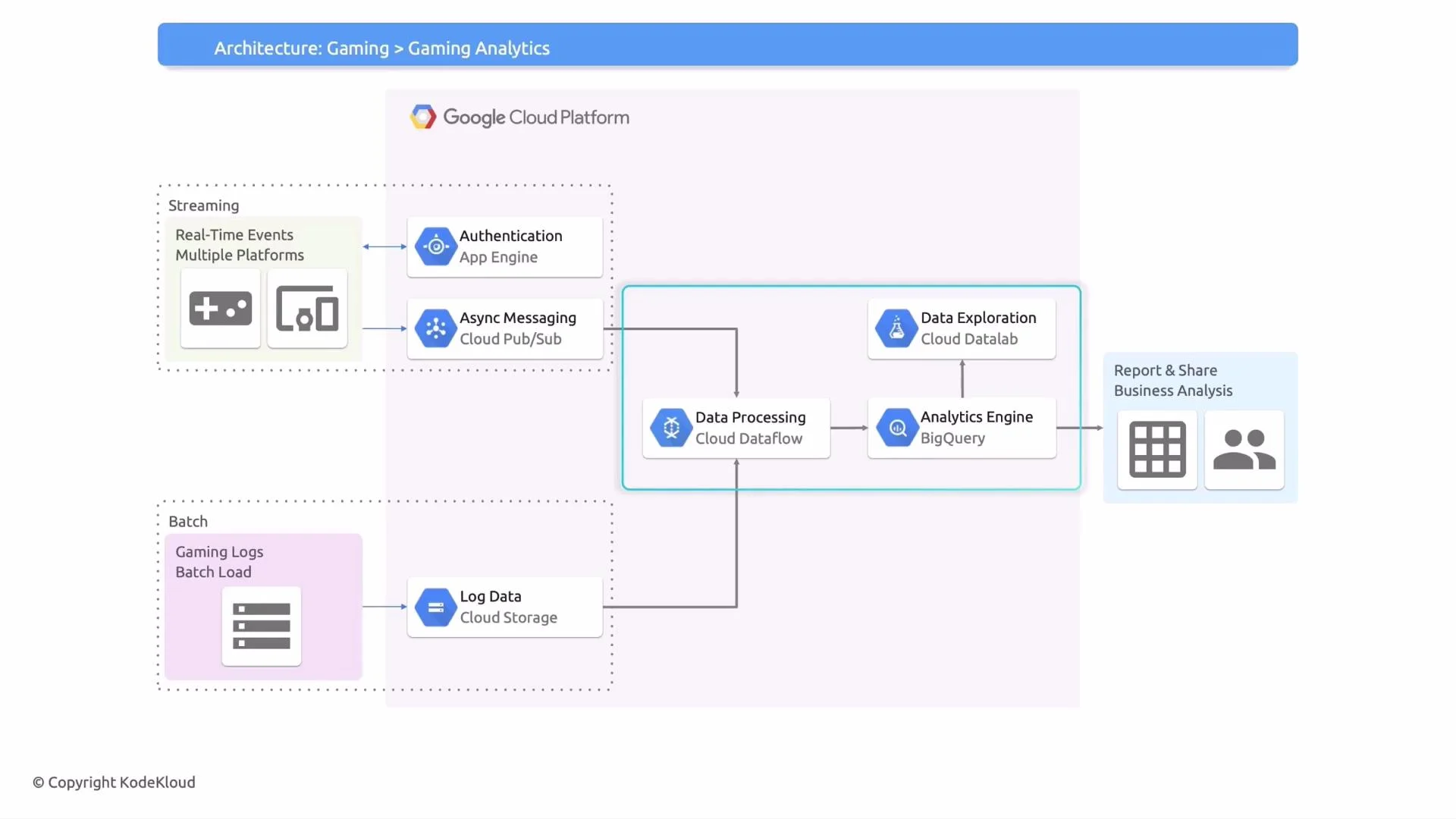
High-level overview
This architecture contains two primary data flows:- Batch (logs and historical data) for offline processing and long-term analysis.
- Streaming (real-time player events) for live monitoring, personalization, and leaderboards.
Batch layer
Batch pipelines handle periodic ingestion of log files and historical telemetry such as match histories, receipts, server logs, and scheduled exports. Typical pattern:- Clients and servers write log files on a schedule (hourly, daily).
- Files land in Cloud Storage (data lake) with partitioned paths and lifecycle policies.
- Cloud Dataflow (Apache Beam) processes the raw files to clean, transform, and enrich data.
- Outputs are written to BigQuery for analytics or back to Cloud Storage as Parquet/Avro for downstream consumption.
- Cloud Storage: durable, low-cost storage for raw/archived files and partitioned datasets.
- Dataflow: unified batch + streaming processing (Apache Beam) with autoscaling and built-in windowing/aggregation.
Real-time (streaming) layer
For live gameplay and near-real-time use cases (fraud detection, personalization, leaderboards), the system captures events on every player action (start game, complete mission, purchase). Ingestion and processing flow:- Clients (mobile, web, console) send authenticated events to a front-end API (App Engine, Cloud Run, or managed API gateway).
- The front-end validates, authenticates, rate-limits, and publishes events to Cloud Pub/Sub.
- Cloud Pub/Sub provides durable, scalable buffering to absorb traffic spikes.
- Cloud Dataflow (streaming mode) performs sessionization, enrichment (joins to player profiles), aggregations, and windowed computations.
- Streaming results are written to BigQuery for analytics or to low-latency stores (e.g., Memorystore, Cloud Bigtable) for personalization and fast lookups.
- Decoupled producers and consumers via Pub/Sub make the ingestion layer resilient to spikes.
- Dataflow’s streaming capabilities support stateful processing (sessions, deduplication, sliding windows).
Analytical and data processing layer
Cloud Dataflow operates as the central processing engine for both batch and streaming workloads using the Apache Beam model. Processed datasets land in BigQuery where teams can run ad-hoc SQL, build dashboards, and train models with BigQuery ML. Key capabilities:- Unified processing model for consistency between batch and streaming logic.
- High-throughput analytic storage in BigQuery with integration to notebooks and BI tools.
- Support for data science workflows (managed notebooks, BI dashboards, and BigQuery ML).
Historically, older managed notebook environments were used for interactive analysis; many teams now prefer modern managed notebook solutions. Choose the managed notebook that best fits your environment and lifecycle needs.
Component summary
Best practices and considerations
- Design schema and partitioning strategies in Cloud Storage and BigQuery to optimize query performance and cost.
- Use Pub/Sub dead-letter topics and monitoring for reliable streaming pipelines.
- Implement idempotent event producers and Dataflow deduplication to handle retries.
- Choose the right low-latency store based on access patterns: Memorystore for caching, Bigtable for large, scalable key-value lookups.
- Monitor system cost and performance with Cloud Monitoring and Logging; set alerts for ingestion/backlog growth.
Summary
- Batch pipelines: use Cloud Storage as a data lake, process with Cloud Dataflow, and store analytics-ready tables in BigQuery.
- Streaming pipelines: validate events at an authenticated front end, publish to Cloud Pub/Sub, process in streaming Dataflow, and deliver near-real-time results to BigQuery or low-latency stores.
- Analytics & ML: BigQuery supports SQL-based exploration, BI, and model training (BigQuery ML); notebooks and visualization tools enable insights and dashboards.
Links and references
- Cloud Dataflow Documentation
- BigQuery Documentation
- Cloud Pub/Sub Documentation
- Cloud Storage Documentation
- Designing stream-processing architectures on GCP