What are interleaved tables?
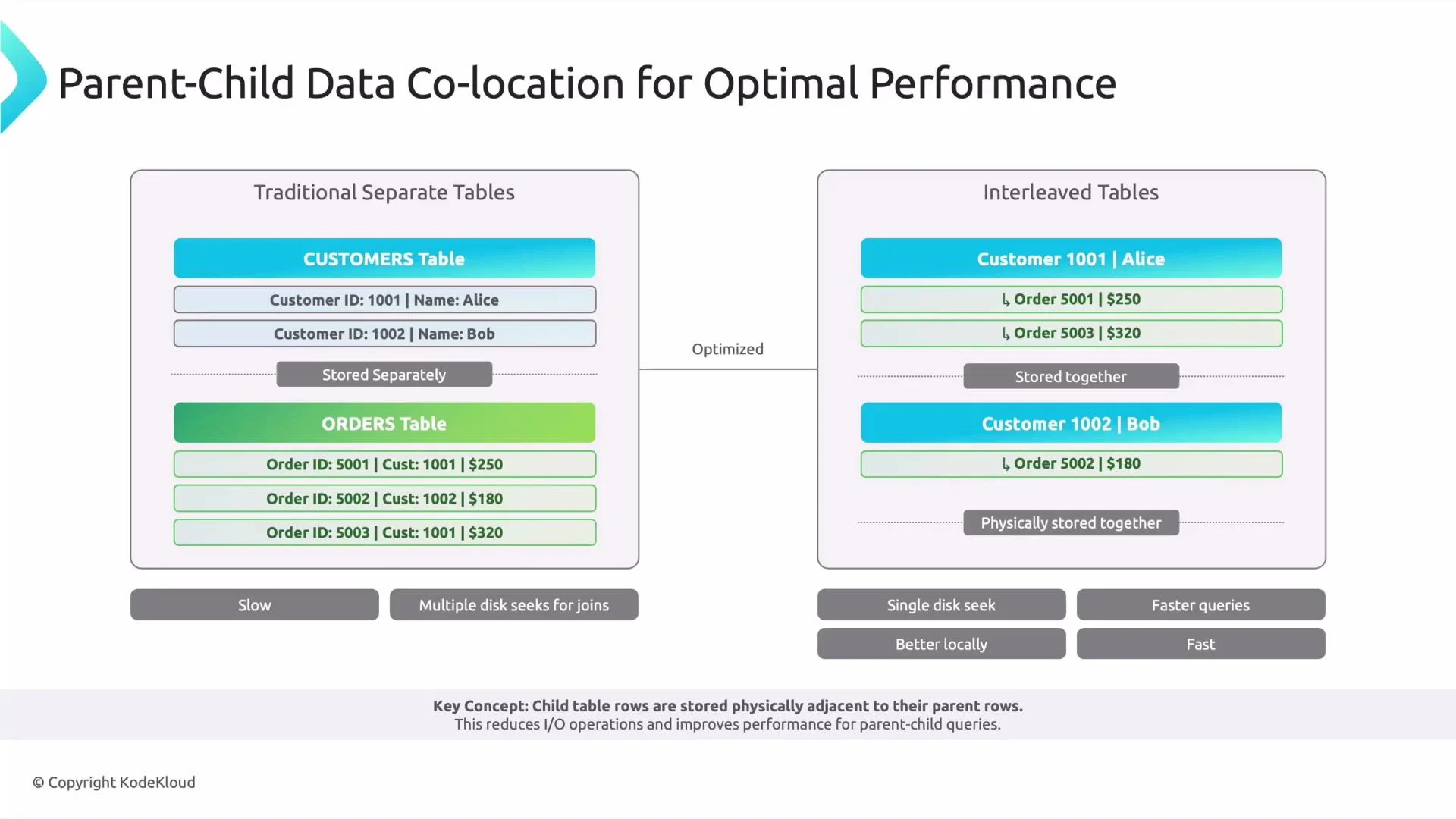
- Interleaved tables physically co-locate parent and child rows in Cloud Spanner so related rows are stored next to each other on disk.
- This row locality reduces disk seeks and improves latency and throughput for queries that fetch a parent with its children together.
- In a typical relational layout (for example,
CUSTOMERandORDERSlinked byCustomerId), rows might be stored far apart, requiring multiple seeks. With interleaving, each customer row is stored adjacent to its order rows, often enabling a single disk seek for parent + children retrieval.
When to use interleaved tables
- Use interleaved tables when child rows are logically dependent on the parent and are rarely queried independently.
- Common scenarios include user profiles with recent activity, account pages with purchase history, audit logs grouped by entity, and other parent-centric read patterns.
- Avoid interleaving when child rows require frequent independent access, independent scaling/distribution, or when the child’s lifecycle is decoupled from the parent.
Be careful: interleaving enforces a primary key dependency and cascade deletes. If your application deletes parents frequently or requires independent child retention, interleaving may not be appropriate.
Important technical notes
- A child table’s primary key must include the parent’s primary key as a prefix — this ordering drives physical colocation in Spanner.
- Deleting a parent automatically deletes its interleaved child rows (
ON DELETE CASCADE). - Interleaving changes only the physical storage layout, not the logical relational model.
Example DDL
A common pattern is to createOrders interleaved under Customers so that orders are colocated with each customer:
Ordersuses(CustomerId, OrderId)as the primary key so Spanner colocates orders under the corresponding customer.ON DELETE CASCADEremoves interleaved children automatically when the parent is deleted.
Use interleaved tables when the child rows are tightly bound to the parent and you typically read or delete them together. Interleaving improves locality and read performance but implies cascade deletes and a primary key dependency.