At a glance
- Cloud Data Fusion: visual, code-free data integration and orchestration (built on CDAP). Best for building repeatable, enterprise-grade ETL/ELT pipelines that integrate across many systems.
- Cloud Dataprep (by Trifacta): serverless, ML-assisted data preparation for cleaning, profiling, and exploratory transformation. Best for analysts and business users working on messy datasets.
What each service is best at
-
Cloud Data Fusion
- Visual, drag-and-drop pipeline builder with many pre-built connectors.
- Designed for complex ETL/ELT, orchestration, pipeline lineage, and enterprise reuse.
- Orchestrates jobs and typically delegates execution to compute engines such as Dataproc or Dataflow.
- Best for data engineers building scheduled or event-driven integration across systems (databases, warehouses, streams, and lakes).
-
Cloud Dataprep (by Trifacta)
- Serverless, point-and-click interface with ML-assisted suggestions for cleaning and transforming data.
- Generates versioned transformation “recipes” and provides interactive profiling and suggestions.
- Executes transformations on a managed platform and writes outputs to BigQuery, Cloud Storage, etc.
- Ideal for analysts and business users performing ad-hoc cleansing and exploratory data preparation.
How Dataprep’s ML-powered recipes work
When you connect a dataset in Cloud Dataprep, the service profiles the data and proposes suggested transformations — for example:- Detecting and standardizing date formats
- Trimming whitespace or normalizing case
- Detecting likely column types, malformed values, or outliers
Comparing the two in practical scenarios
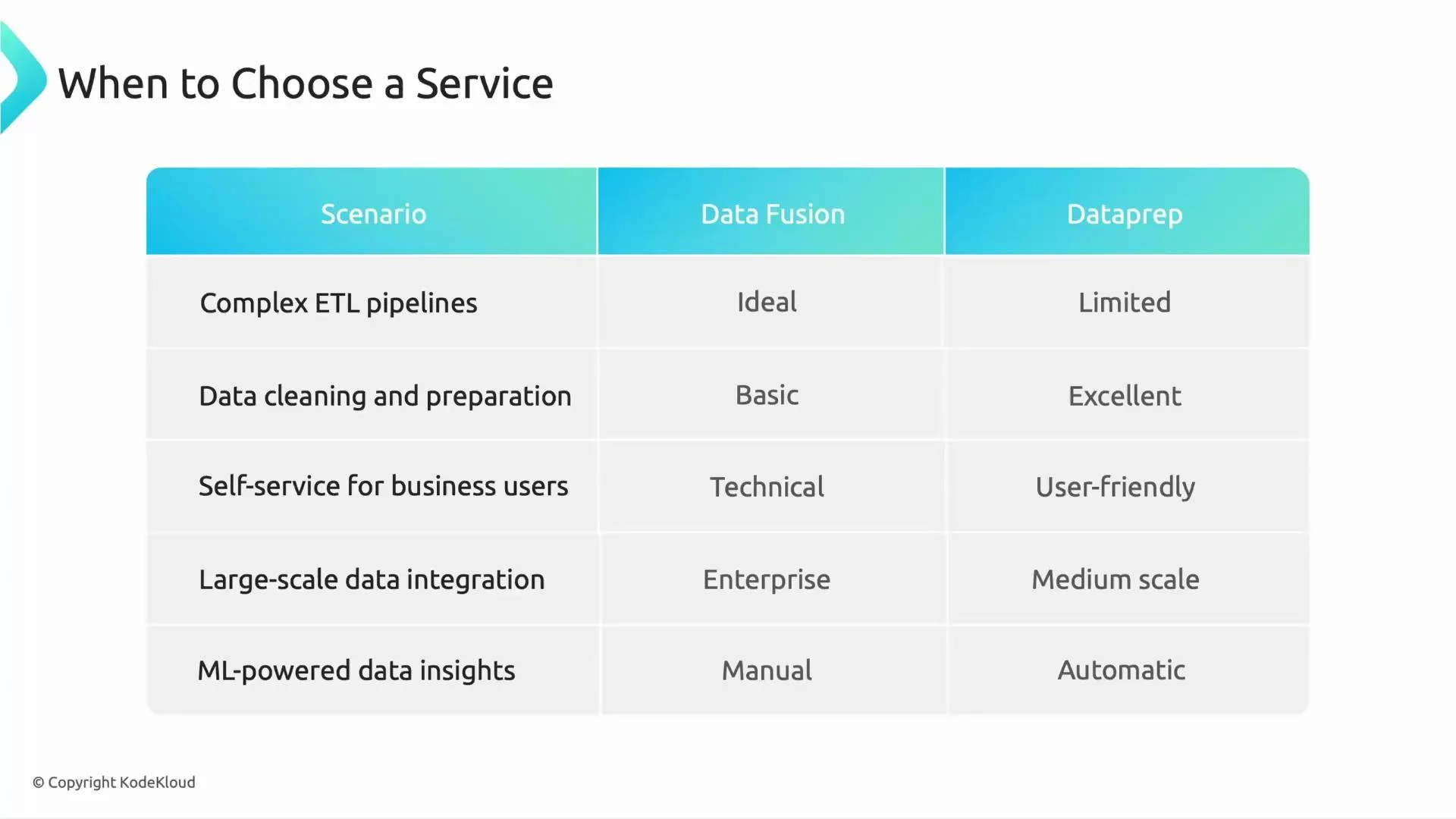
- Use Cloud Data Fusion when your priority is building complex, repeatable ETL/ELT pipelines that integrate and orchestrate across many systems at scale.
- Use Cloud Dataprep (Trifacta) when you need interactive data cleaning, profiling, and transformation for messy datasets — especially for business users or analysts who prefer a point-and-click UX.
- For self-service data preparation, Dataprep’s UX and ML suggestions make it far more approachable than Data Fusion’s engineering-oriented interface.
- For enterprise-wide integrations requiring custom orchestration, reusable components, and operational tooling, Data Fusion is the better fit.
- Execution model: Dataprep executes transformations serverlessly on its managed infrastructure; Data Fusion orchestrates and delegates compute to engines such as Dataproc or Dataflow depending on pipeline configuration.
Feature comparison table
Quick decision checklist
- Need enterprise orchestration, complex joins across systems, or operational pipelines? -> Cloud Data Fusion.
- Need fast profiling, automatic suggestions, and a UX for non-engineers to clean messy data? -> Cloud Dataprep.
- Need both? Consider Dataprep for initial cleaning and profiling, then move prepared datasets into Data Fusion workflows for enterprise orchestration.
Use Cloud Data Fusion to move, integrate, and orchestrate data across systems at scale. Use Cloud Dataprep (Trifacta) to interactively clean and transform datasets, especially when you want ML-powered profiling and versioned transformation recipes.
Summary
- Cloud Data Fusion: visual, code-free orchestration and integration tool for engineers; ideal for large-scale ETL/ELT and enterprise pipelines. Relies on underlying compute engines to execute work.
- Cloud Dataprep (Trifacta): serverless, ML-assisted data preparation for analysts and business users; excellent for profiling, cleaning, and preparing messy data with versioned recipes and automated suggestions.
Links and references
- Cloud Data Fusion documentation
- Cloud Dataprep (by Trifacta) documentation
- Google Cloud: Data integration products comparison