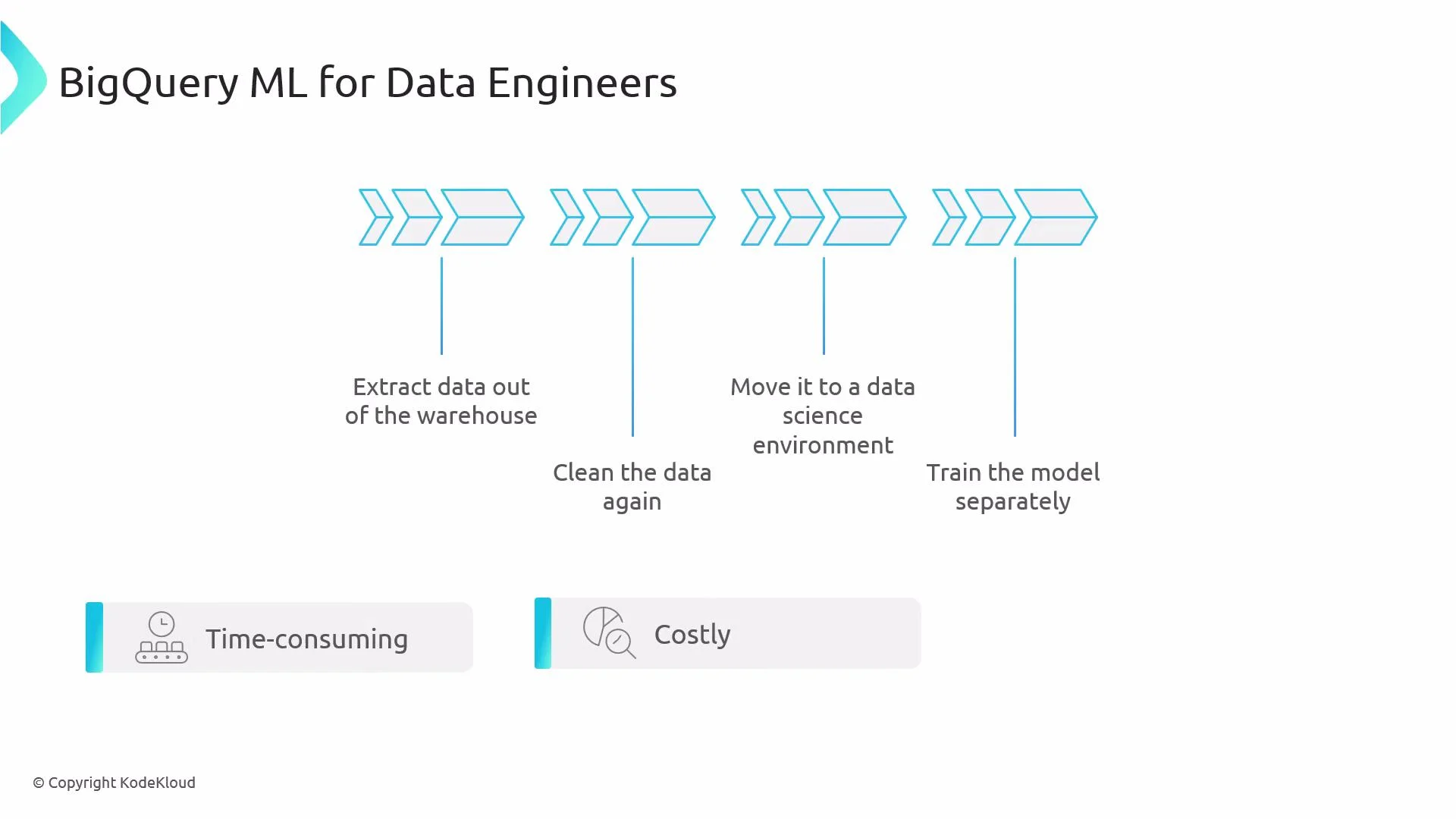
- Keep data inside the warehouse for better security, governance, and lower latency.
- Use SQL-first commands such as
CREATE MODEL,ML.EVALUATE, andML.PREDICT. - Reduce repeated ETL/ELT operations and operational overhead for both engineers and data scientists.
BigQuery ML lets you prototype and deploy many common ML workflows from the BigQuery console, removing data-copy steps and accelerating iteration.
-
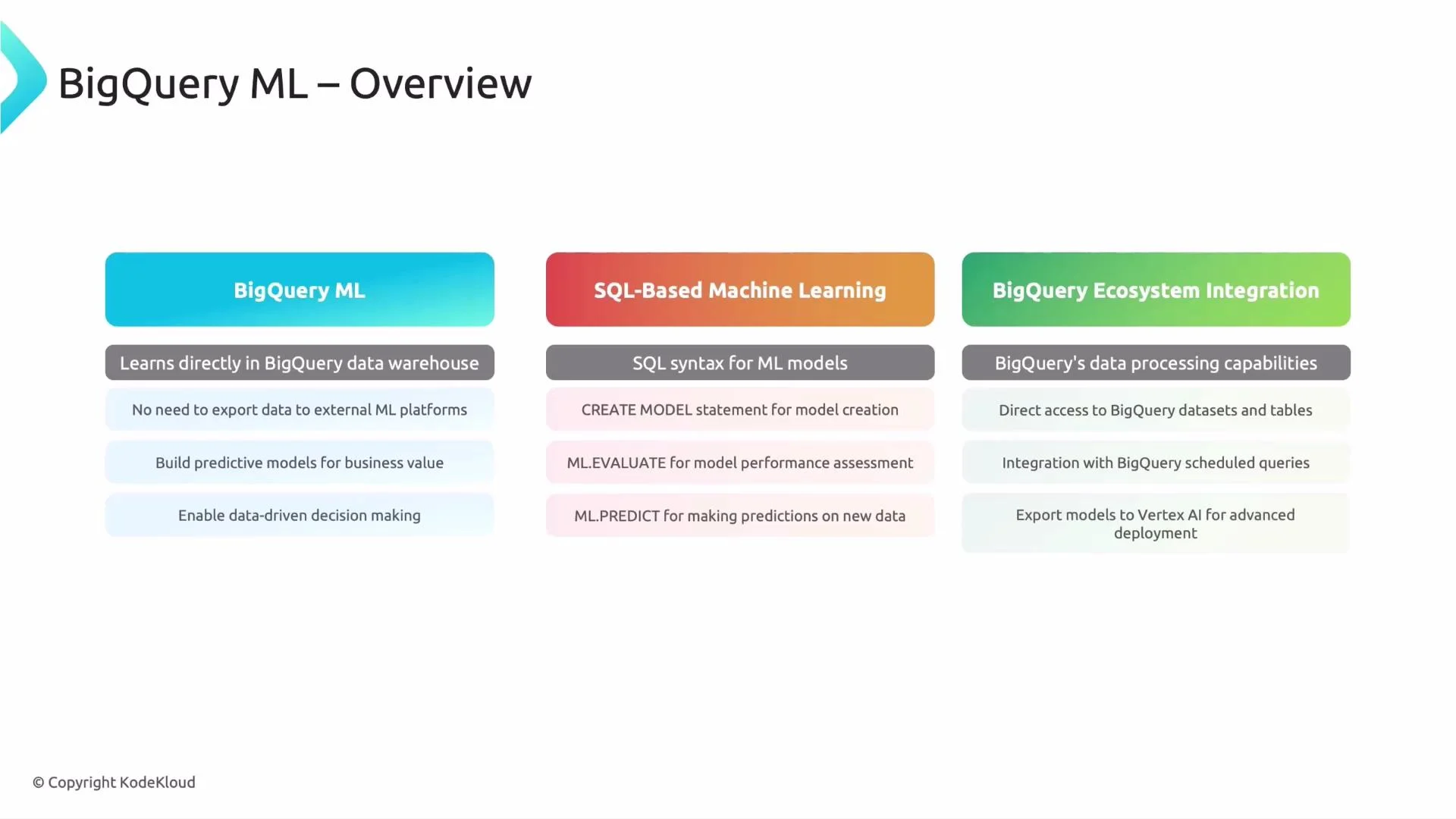
BigQuery ML (in-warehouse training and serving)
- Models live alongside your tables and views and benefit from BigQuery’s storage, IAM, and query optimizations.
-
SQL-based engine
- Operate models with SQL statements (train, evaluate, predict). Teams comfortable with SQL can quickly adopt ML.
-
Ecosystem integration
- BigQuery ML integrates with scheduled queries, Cloud IAM, audit logs, and can export models to Vertex AI for advanced workflows.
Example: training a simple classification model
- Training and prediction consume BigQuery compute (slots) and incur query costs comparable to other BigQuery operations. Monitor usage and budget accordingly.
- Use Cloud IAM roles and dataset-level controls to govern who can create, export, or run models.
- For advanced model types (deep learning, custom training/serving), export models to Vertex AI or integrate with other Google Cloud services.
Training and serving models in BigQuery consume compute and may increase costs. Monitor query cost, slot usage, and apply least-privilege access controls.
- BigQuery ML documentation: https://cloud.google.com/bigquery-ml
- BigQuery overview: https://cloud.google.com/bigquery
- Vertex AI (for exporting models and advanced ML workflows): https://cloud.google.com/vertex-ai