- Cold start — the time required for a new function instance to initialize before it begins handling requests. Cold starts vary by runtime, language, and generation (first vs second generation), and may range from a few hundred milliseconds to a couple of seconds in many cases. Choose runtimes and function sizes with cold-start behavior in mind if you need low-latency responses.
- Timeout — the maximum runtime before the platform forcibly terminates the function. Google Cloud Functions supports timeouts up to several minutes (check the product documentation for current limits).
- Invocations — how often a function is executed. Cloud Functions integrate with many event sources and are billed per invocation and compute usage. Cloud providers often provide a free tier and quotas; always consult the Cloud Functions pricing and quota pages for up-to-date limits.
- Memory and CPU — you can configure memory which also impacts CPU allocation; larger memory allocations typically get more CPU and can reduce execution time.
- Concurrency and networking — generation and runtime affect whether a function can handle multiple concurrent requests on one instance and how it connects to VPC networks via connectors.

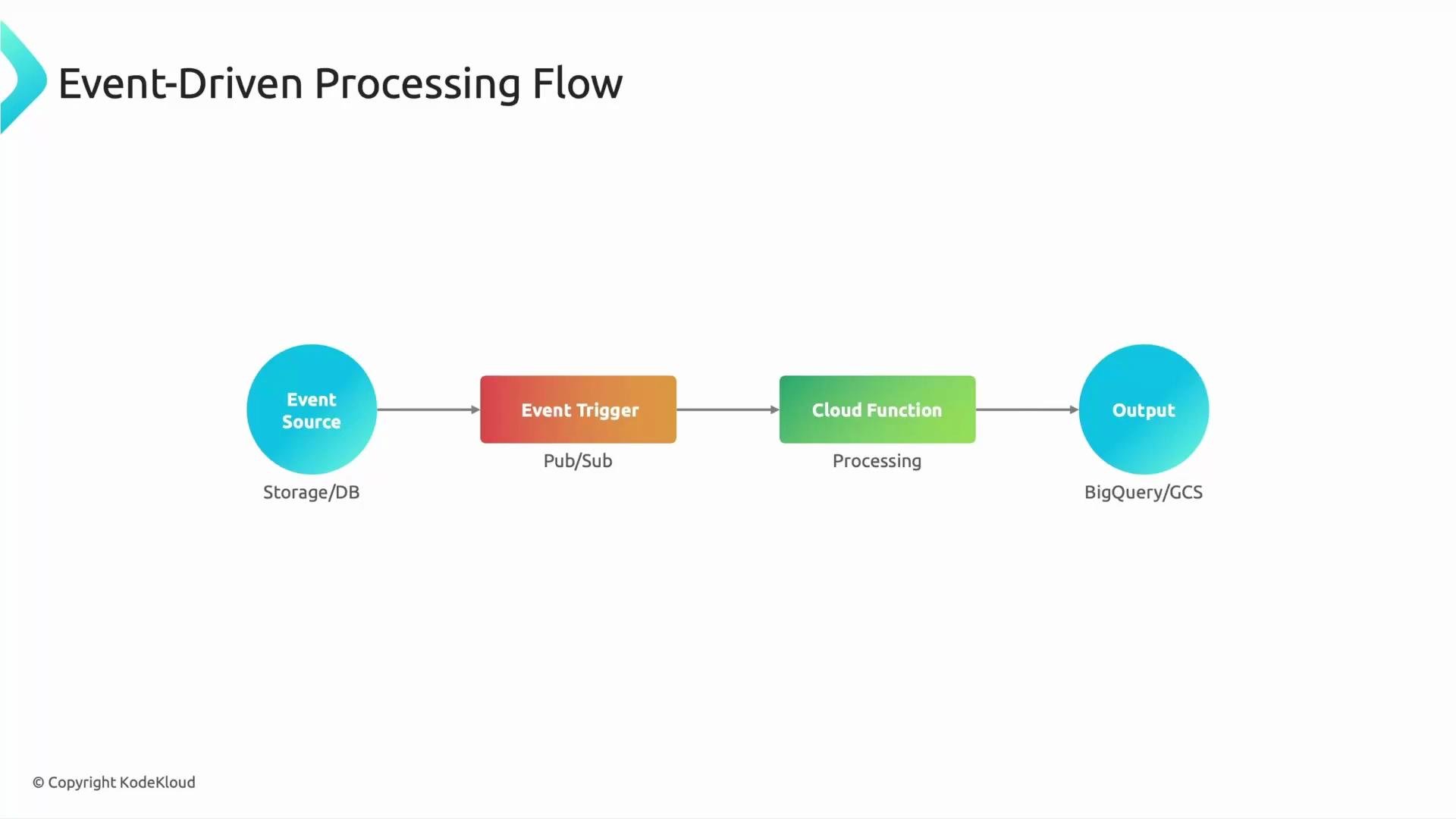
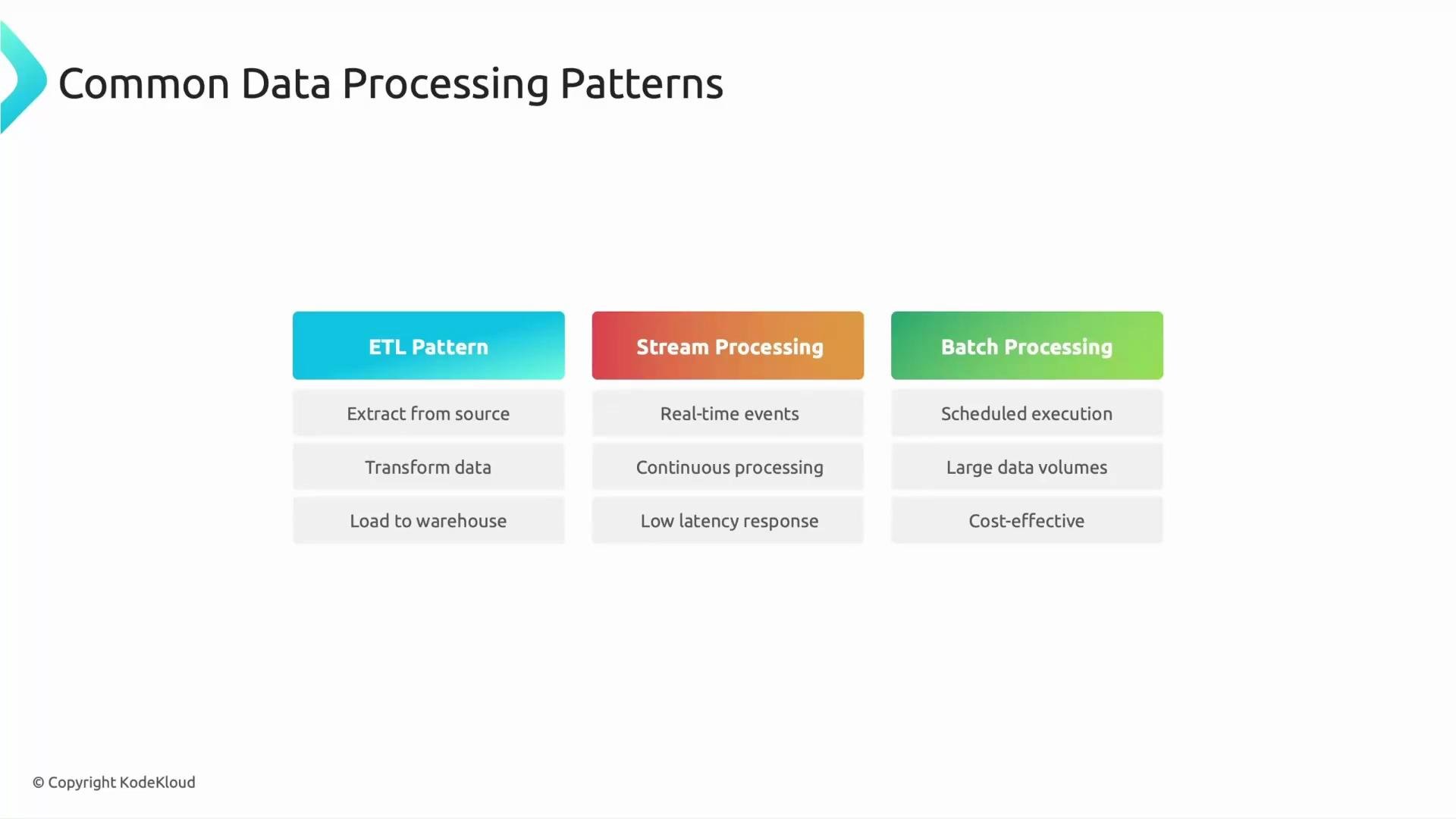
- Keep functions small and focused; use them as glue code for reacting, transforming, routing, and automating data flows.
- Optimize for cold start where needed: choose runtimes with faster startup times, minimize dependency size, and prefer later-generation runtimes or smaller deployment artifacts.
- Use batching strategies (grouping multiple events into one processing job) to improve throughput and reduce per-invocation overhead where applicable.
- For high-throughput or long-running processing, evaluate concurrency settings, batching, and alternative compute options such as Cloud Run or Dataflow depending on throughput, cost, and latency requirements.
- Ensure the function’s service account has least-privilege IAM permissions (e.g., read access to GCS objects, write access to BigQuery tables).
- Monitor cold starts, error rates, latency, and costs using Cloud Monitoring and Logs to tune memory, concurrency, and retry strategies.
Cloud Function quotas, free tiers, and supported features change over time and can differ by generation and region. Always consult the official Google Cloud documentation for current limits and pricing before production use.
- Cloud Functions Pricing
- Cloud Functions Quotas
- Google Cloud Run documentation
- Google Cloud Dataflow documentation
- Kubernetes Concepts — if considering alternative orchestration