- Centralized governance across heterogeneous storage and analytic systems.
- Apply policies and quality checks without migrating data.
- Improve discoverability and trust for data consumers.
How Dataplex models your data
Dataplex introduces a simple three-tier logical model to represent and govern an entire data estate: Lake → Zone → Asset. This hierarchy maps naturally to business domains and data lifecycles so teams can operate independently while following consistent governance.- Lake: A logical grouping of data aligned to a domain (for example, customers, marketing, finance). Think of a lake as the top-level scope for governance and ownership.
- Zone: Subdivisions within a lake that represent lifecycle or quality stages (for example,
raw,curated,sandbox). Zones help prevent accidental use of inappropriate data. - Asset: A pointer to the underlying storage location (for example, a Cloud Storage prefix or a BigQuery dataset). Dataplex operates on assets to scan, collect metadata, apply policies, and run quality checks — without moving the data.
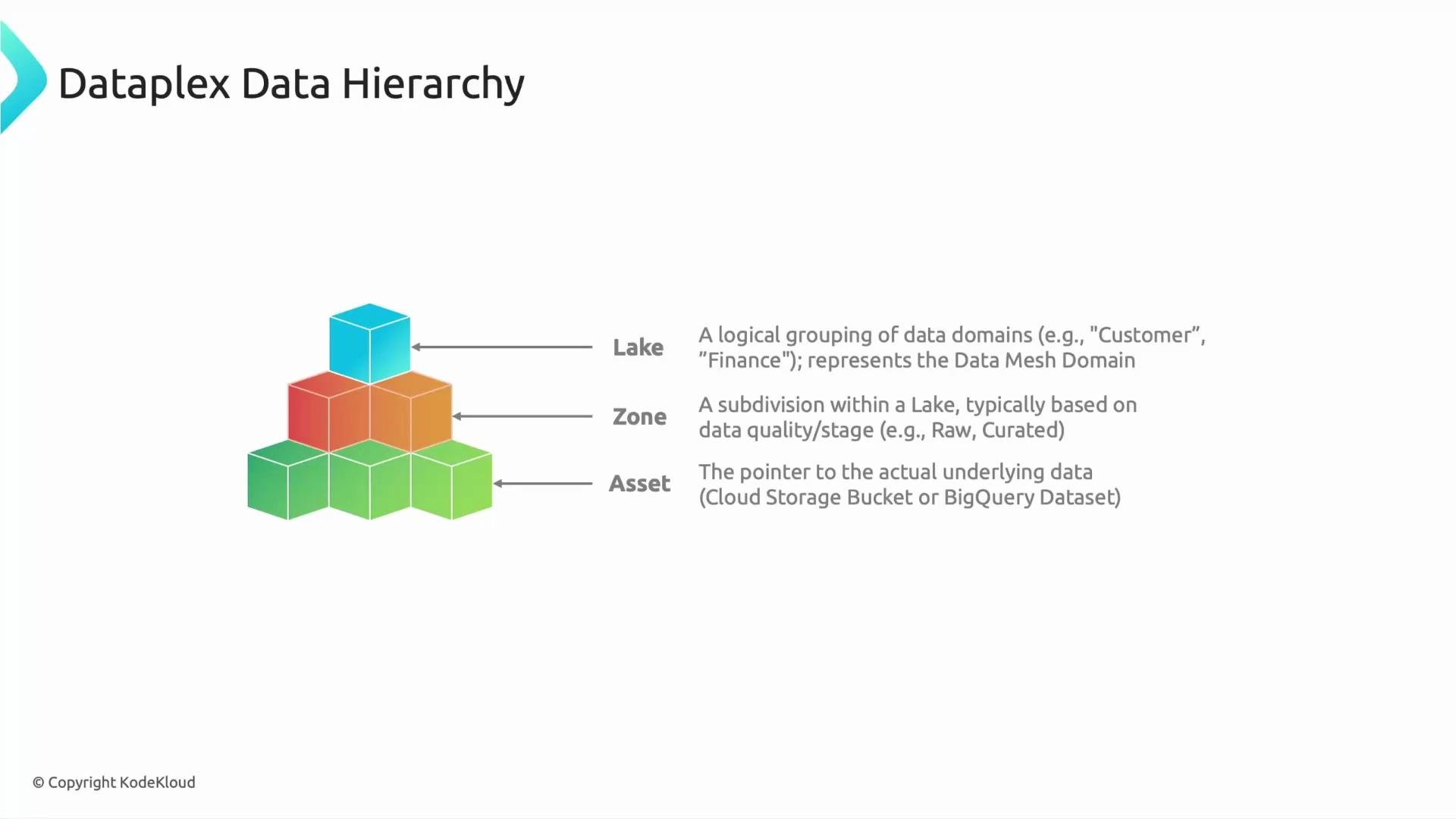
Because Dataplex manages assets (pointers), governance actions — scans, IAM enforcement, metadata collection, quality checks — apply to the underlying data sources in-place. This enables incremental adoption, reduces operational disruption, and preserves existing pipelines and downstream consumers.
Dataplex governance capabilities
Structure alone doesn’t make data usable — governance does. Dataplex provides a consolidated set of governance features designed to make data discoverable, trusted, and secure across your Google Cloud environment.
Dataplex’s governance stack focuses on:
- Access control and IAM propagation
- Automated profiling and data quality checks
- Centralized metadata and discovery via the catalog
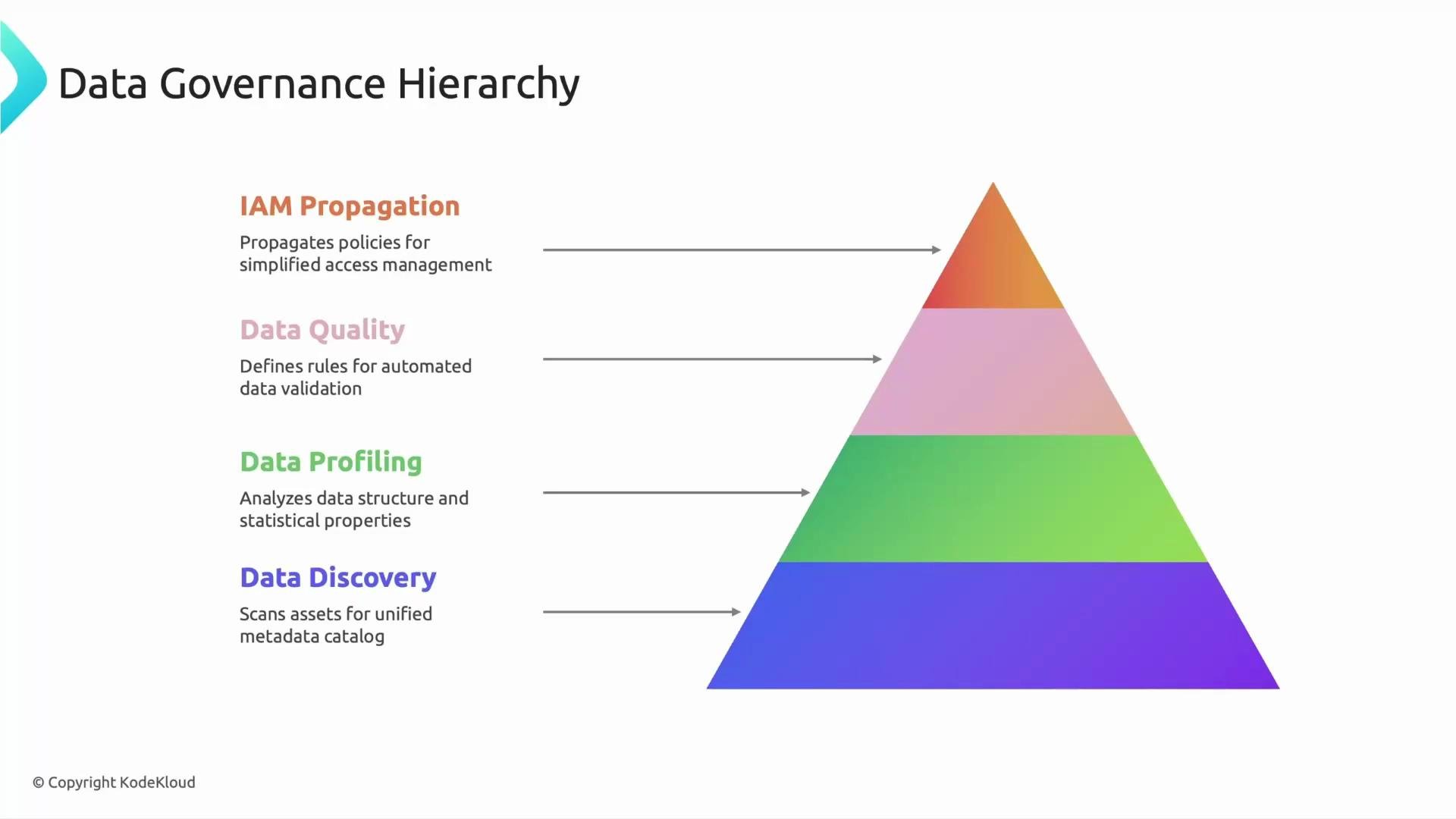
Asset pointers enable centralized governance without moving data. Use lakes for domains, zones for lifecycle/quality stages, and assets to reference storage locations so governance can be applied consistently and non-invasively.
Next steps
Now that you have a solid foundation in how Dataplex organizes and governs data, the next deep dive will examine Dataplex’s data catalog: how discovery, classification, and metadata management work together to surface trusted datasets for analytics and ML.Links and references
- Dataplex product page: https://cloud.google.com/dataplex
- Google Cloud Storage: https://cloud.google.com/storage
- BigQuery: https://cloud.google.com/bigquery
- Data Catalog: https://cloud.google.com/data-catalog
- Data mesh principles (background reading): https://martinfowler.com/articles/data-mesh-principles.html