Common semi-structured formats
- JSON — JavaScript Object Notation; ubiquitous for web APIs and application payloads; supports nested objects and arrays.
- XML — Extensible Markup Language; tag-based and used in many enterprise integrations.
- YAML — Human-friendly configuration files and manifests.
- Avro — Compact binary format with explicit schema; widely used in streaming and batch pipelines; supports schema evolution.
- Parquet — Columnar on-disk format optimized for analytical queries and compression.

Example: a typical JSON document
The following JSON illustrates nested objects and arrays commonly found in semi-structured application data:JSON/JSONB column types — but mapping nested or variable documents to normalized tables can be cumbersome and may not reflect the application’s read/write patterns. For highly variable schemas, document-style lookups, or very high write throughput across diverse record shapes, purpose-built semi-structured stores are often a better fit.
Cloud SQL supports
JSON/JSONB columns. Use relational JSON support for occasional semi-structured fields or when you need strong relational guarantees. For primary document storage and flexible schema patterns, consider a document or wide-column store instead.Why use semi-structured data?
- Flexible schema: records can differ in fields without schema migrations.
- Faster iteration: no need to design and migrate strict schemas up front.
- Self-describing: keys and nested structures travel with the data, simplifying client-side usage.
Semi-structured formats at a glance
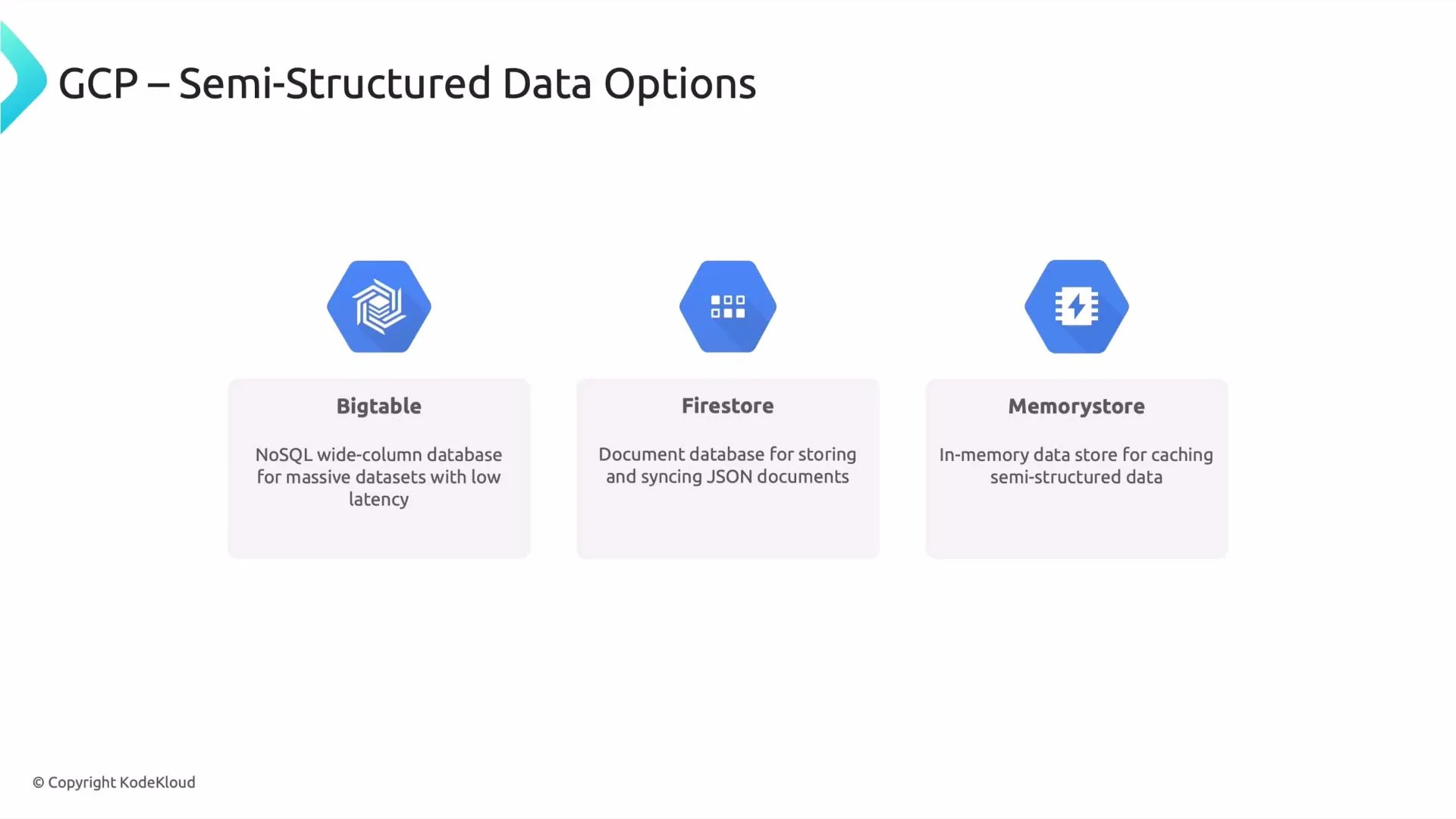
GCP services that handle semi-structured data
Below are commonly used Google Cloud services and when to choose each. For detailed docs, see links in the table.Memorystore (Redis/Memcached) is designed for caching and ephemeral state. Do not rely on it as the sole durable store for critical or long-lived data.
Analytics and big-data workflows
For analytic workloads, combine on-disk semi-structured formats (Avro, Parquet, newline-delimited JSON) with query engines such as BigQuery or data pipelines via Dataflow. A common pattern is:- Write Avro/Parquet to Cloud Storage for compact, schema-aware storage.
- Use BigQuery to run SQL analytics over those files (BigQuery can query Parquet/Avro/JSON directly).
- Use Dataflow or Dataproc for ETL, transforms, or streaming ingestion.