ingest → process → store → expose.
Start by splitting the architecture into two common ingestion patterns: streaming (real-time) and batch (periodic/large-scale).
Streaming pipeline
- Ingest: real-time events arrive on Cloud Pub/Sub (durable, scalable messaging for event-driven architectures).
- Process: run streaming pipelines in Cloud Dataflow to perform enrichment, filtering, windowing, aggregation, and stateful transformations; Dataflow offers autoscaling, exactly-once semantics (with appropriate sinks), and unified stream/batch programming.
- Store: persist event or state data into Cloud Bigtable when you need low-latency lookups, high-throughput writes, and efficient time-series or event-indexed access.
- Ingest: export snapshots or change-data-capture (CDC) from on‑premises databases into files staged on Cloud Storage, or push batched events through Dataflow.
- Process: use Cloud Dataflow for unified streaming/batch transforms and Dataproc (Spark) for large-scale Spark workloads, ETL, and Spark‑based ML preprocessing.
- ML: run model training pipelines (for example, Spark ML on Dataproc or Dataflow-driven pipelines feeding training jobs) against the processed batch datasets.
- Warehouse: load aggregated and cleansed data into BigQuery for fast, cost-effective analytics and ad-hoc SQL queries.
- Visualization: analysts and BI tools (for example, Tableau and Looker Studio) connect directly to BigQuery for dashboards and reports.
- Notifications and actuation: publish processed results, alerts, or events back to Cloud Pub/Sub, or invoke compute services (App Engine, Cloud Run, GKE) to send mobile pushes, webhooks, or other downstream actions.
- Multiple consumers and sinks: route the same raw or processed streams to multiple endpoints—Bigtable for low-latency operational reads, BigQuery for analytics, Cloud Storage for archival, or external systems for notification and actuation.
- Observability and governance: integrate Cloud Monitoring, Cloud Logging, and Data Catalog (not shown in the diagram) to ensure traceability, SLA monitoring, and metadata governance.
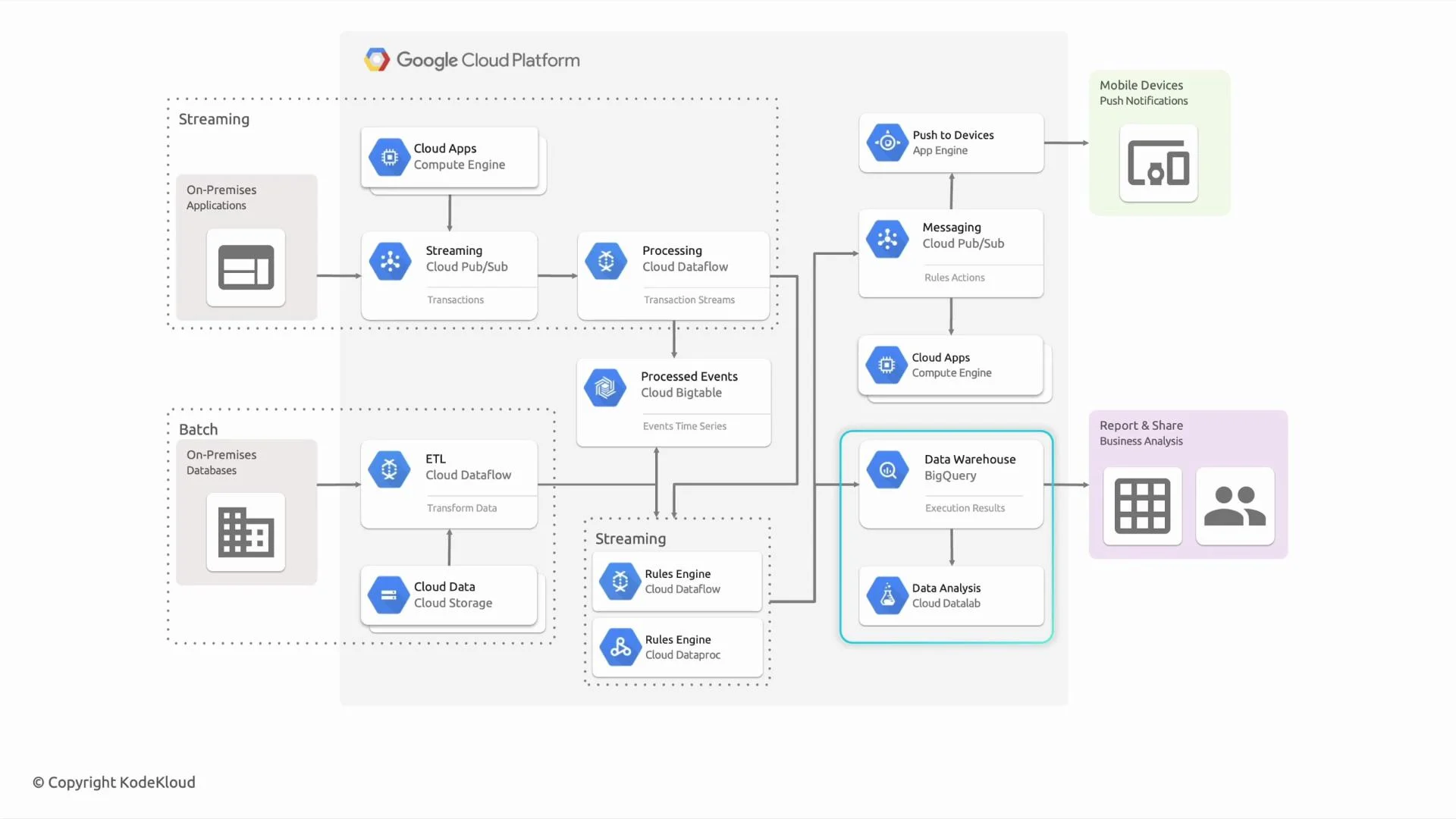
When describing this architecture in an interview, speak in logical blocks:
ingest → process → store → expose. For each service name it, summarize its responsibility in one sentence, and justify the choice briefly (for example: “Bigtable for low-latency time-series storage; BigQuery for analytical queries and dashboards”).