- Storage options that fit Dataproc workloads (HDFS, Google Cloud Storage, Local SSD, Persistent Disk).
- How to compare storage by cost, performance, and durability.
- A four-phase migration plan with practical steps and example commands.
Storage choices (summary)
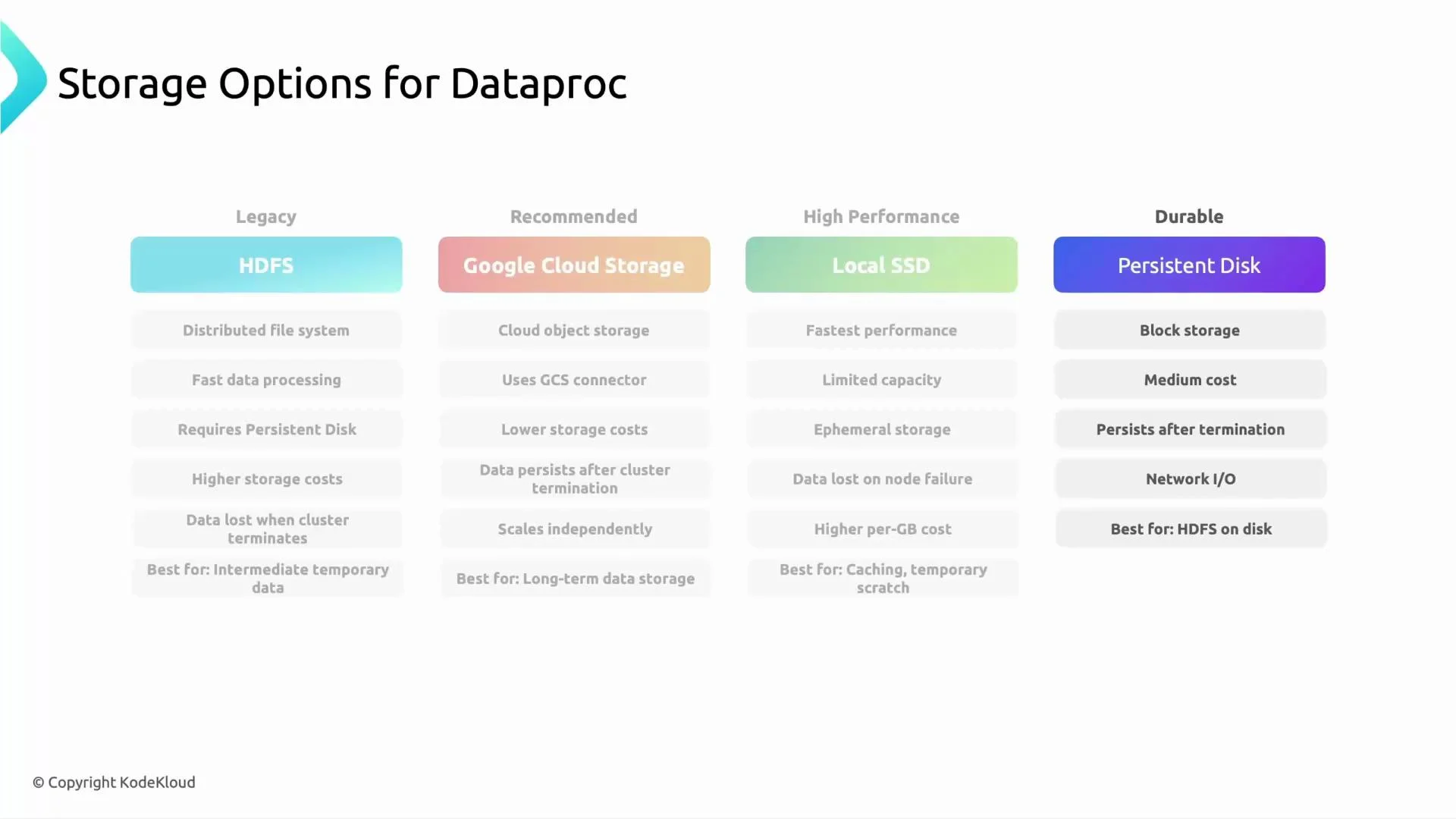
Below are common storage options used with Dataproc, their characteristics, and typical use cases.HDFS (Hadoop Distributed File System)
- Block-based distributed filesystem used by on-prem Hadoop clusters.
- Runs on disks attached to cluster nodes (on GCP often Persistent Disks).
- Very fast for locality-optimized workloads, but data is tied to cluster lifecycle unless disks are preserved.
- Best for temporary data or workloads that rely on HDFS semantics.
- Considered legacy for cloud-native deployments; prefer object storage for long-term storage on GCP.
Google Cloud Storage (GCS) — recommended
- Object storage, addressed with
gs://URIs. Data persists independently of Dataproc clusters. - Low cost at scale, virtually unlimited capacity, and simple management.
- Integrates with Dataproc via the GCS connector; recommended for long-term analytics storage (input/output datasets, checkpoints, artifacts).
- Good performance for many analytics workloads; watch out for small-file overhead—partition and compact files appropriately.
Google Cloud Storage (GCS) is the most cloud-native option for long-term analytics data with Dataproc. Use HDFS or Local SSD only for temporary, performance-sensitive data inside the running cluster.
Local SSD
- Ephemeral, physically attached to the VM instance.
- Highest IOPS and lowest latency — useful for temporary caches or shuffle-heavy stages.
- Data is lost if the VM fails or is deleted. Use only for transient data.
Persistent Disk (PD)
- Durable block storage that persists independent of the VM lifecycle (unless explicitly deleted).
- Good general-purpose performance and durability at a moderate cost.
- Useful if you need HDFS-like performance with block-storage durability; can be zonal or regional.
Comparison: cost, performance, and persistence
Choose storage based on whether you prioritize speed, durability, or cost-efficiency. The table below summarizes typical trade-offs and recommended usage patterns.
Common architecture pattern:
- Store long-lived datasets in GCS.
- Use HDFS or Local SSD inside Dataproc for temporary caching, intermediate shuffle files, or performance-sensitive stages.
- Use PD when you need durable block storage with predictable I/O.

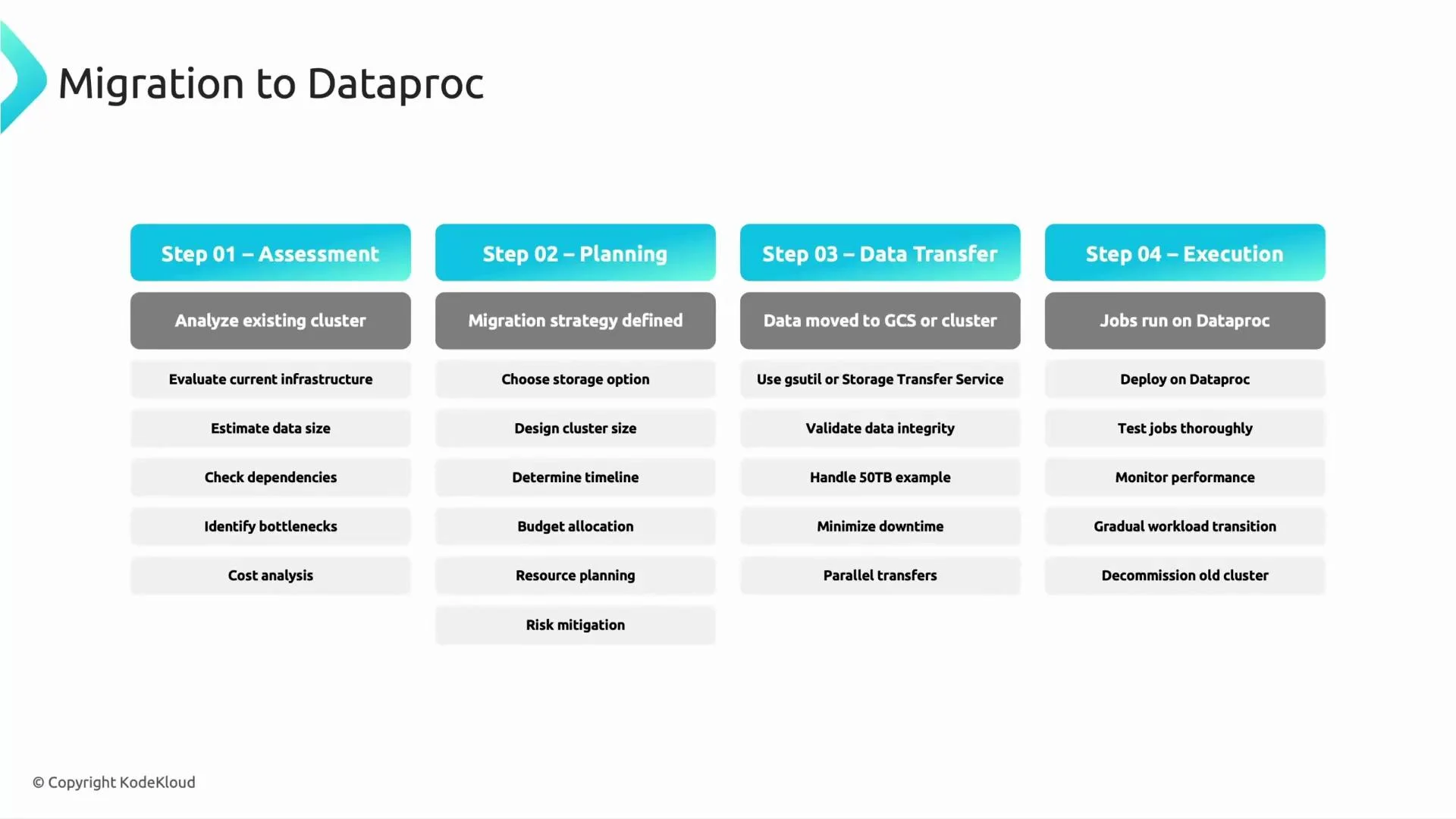
Migration to Dataproc — phased approach
Use a phased migration to reduce risk and validate each step. Below is a practical four-step plan commonly used when moving Hadoop/Spark workloads to Dataproc.
Step details and practical tips:
- Assessment
- Create a catalog of datasets, job DAGs, triggers, libraries, and third-party connectors.
- Identify jobs with heavy shuffles, joins, or small-file patterns — these influence storage and cluster design.
- Capture historical job resource usage to size cluster instances and autoscaling rules.
- Planning
- Convert HDFS paths to
gs://URIs for long-term datasets; use PD or Local SSD for temporary disks where you need block-level performance. - Plan IAM and credentials (service accounts, bucket policies) and any required VPC/peering for secure data access.
- Estimate monthly storage and compute cost; include network egress if cross-region transfers are required.
- Data transfer
- Use
gsutilfor many migrations or Storage Transfer Service for large or scheduled transfers. - Example gsutil commands:
- For very large or offline transfers, consider Transfer Appliance or the Storage Transfer Service. Use checksums or object metadata to validate integrity after transfer.
Always validate transferred data (checksums, row counts) and run representative jobs on Dataproc before decommissioning legacy clusters. Small-file patterns and schema differences are common migration pitfalls.
- Execution
- Provision test Dataproc clusters sized for your peak workloads, using initialization actions if you need extra libraries.
- Update job configuration to reference
gs://paths and test end-to-end. - Measure runtime and I/O characteristics; iterate on partitioning, shuffle behavior, and executor sizing.
- After validation, schedule a cutover: run final incremental sync if needed, switch production jobs to Dataproc, and decommission old clusters.
Final notes and best practices
- Prefer GCS for long-term analytics datasets on Dataproc. It decouples storage from compute and reduces lifecycle management overhead.
- Use ephemeral HDFS or Local SSD for shuffle or temporary caches only while the cluster is running.
- Keep Persistent Disks for workloads that need durable block storage.
- Apply a phased migration (assess → plan → transfer → execute) and validate at each phase.
- Monitor costs and performance post-migration; tune partition sizes and file formats (Parquet/Avro) to reduce small-file overhead.
Links and references
- Dataproc: https://cloud.google.com/dataproc
- GCS connector and Dataproc: https://cloud.google.com/dataproc/docs/concepts/connectors/cloud-storage
- gsutil: https://cloud.google.com/storage/docs/gsutil
- Storage Transfer Service: https://cloud.google.com/storage-transfer-service
- Transfer Appliance: https://cloud.google.com/transfer-appliance
- Signed URLs for ingestion: https://cloud.google.com/storage/docs/access-control/signed-urls