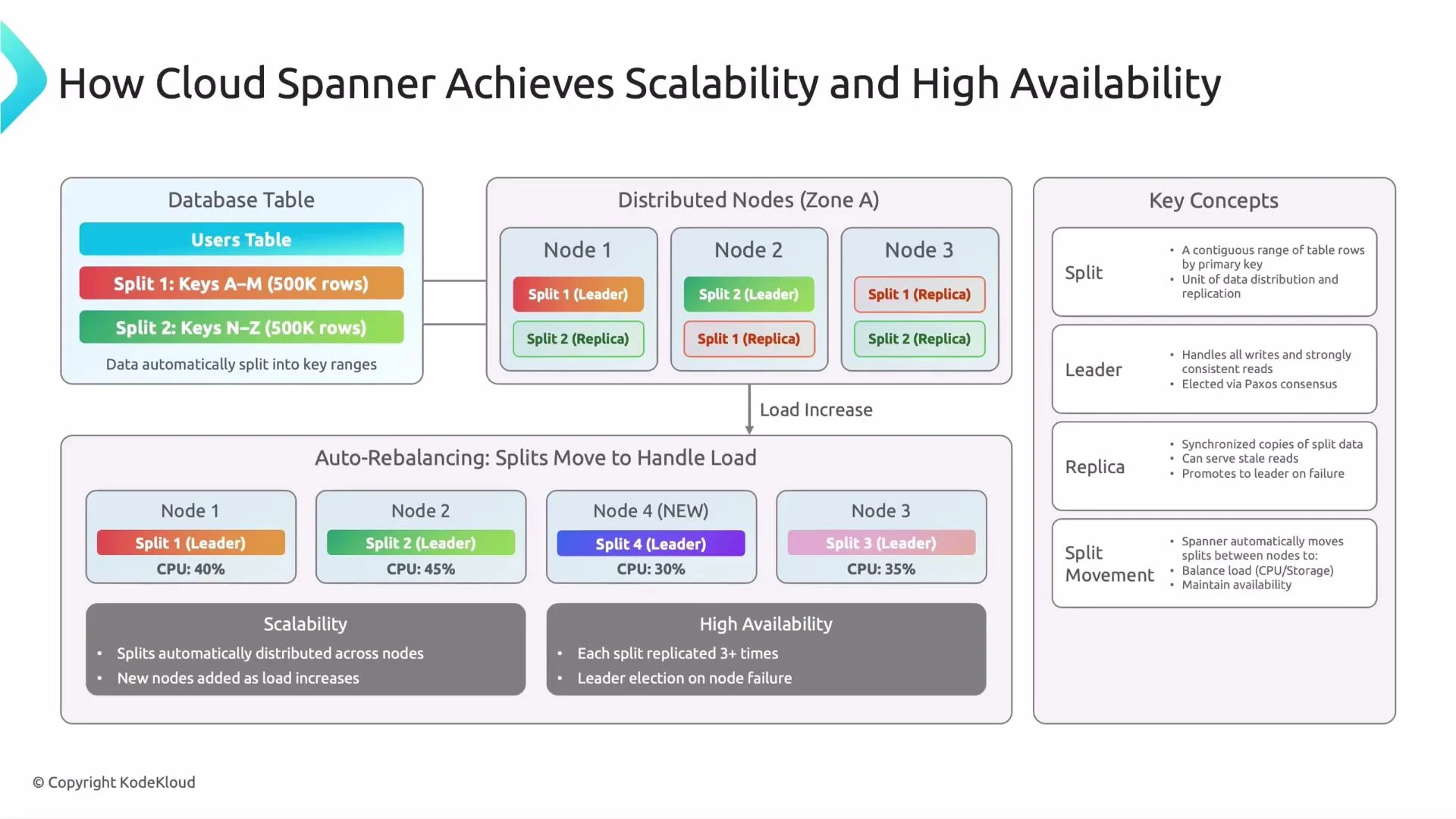
Single-table growth and automatic splitting
Consider a single table (for example,Users) that grows to millions of rows. Spanner automatically partitions the table along the primary key into contiguous key ranges called splits (also called ranges or shards). Splits are created and managed by Spanner — no application-side sharding is required.
Example splits:
- Split 1: keys from A to M
- Split 2: keys from N to Z
Distributing splits across nodes
Splits are distributed across nodes so work can be processed in parallel. Each split has multiple replicas and exactly one leader replica elected for that split:- Leader: Coordinates writes and serves strongly consistent reads for that split. The leader maintains the authoritative state and coordinates replication.
- Followers/Replicas: Serve read traffic (depending on read configuration) and act as failover copies.
Handling hotspots and automatic rebalancing
If traffic concentrates on a particular key range (a “hot” split), Spanner reacts automatically:- Split the hot range into smaller ranges.
- Move ranges between nodes to spread CPU and I/O load.
- Add nodes to the instance and redistribute ranges for capacity growth.
Split, replication, and leader election
Key concepts to remember:- A split is the unit of distribution and replication.
- Leaders handle writes and ensure strong consistency.
- Replicas are synchronized copies that protect availability and serve reads.
- Leader election and replica promotion are automatic (Spanner uses Paxos for replication and leader election).
High availability
Replicas continuously protect availability. If a leader fails, follower replicas can be promoted to leader automatically. When deployed across zones or regions, this replication and automatic failover support strong availability SLAs for multi-region instances. Spanner’s combination of synchronous replication (within a Paxos group), automatic leader election, and cross-region configuration enables both low-latency reads and robust failover behavior.Use Cloud Spanner when you need horizontally scalable, strongly consistent relational storage across regions — for example, global transactions, high throughput, and high availability. For many simpler relational workloads, managed alternatives such as Cloud SQL may be more cost-effective.
Cloud Spanner is a fully managed, specialized service. Evaluate costs, operational requirements, and your need for global strong consistency before choosing Spanner over other managed databases.
Quick reference
When to use Cloud Spanner
Choose Cloud Spanner if your application needs:- Global strongly consistent transactions
- Horizontal scale for high throughput and large datasets
- Low-latency reads and robust cross-region availability
Related topics and references
- TrueTime and global ordering: how Spanner uses TrueTime to produce externally consistent ACID transactions — see Google TrueTime.
- Paxos: the consensus algorithm Spanner uses for leader election and replication — see Paxos on Wikipedia.
- Cloud Spanner documentation: https://cloud.google.com/spanner/docs