What is Datastream?
Datastream is a serverless, real-time data replication service on Google Cloud that continuously captures changes from supported source databases and delivers them to configured destinations. It reads database transaction logs (binlog/WAL/redo logs), converts those changes into events, and streams them to targets with minimal impact on the source systems. Why this matters for data engineers- Keeps analytics and downstream systems up to date with minimal latency.
- Transfers only changes (inserts, updates, deletes) rather than full database dumps, reducing load, storage, and network costs.
- Enables event-driven architectures, real-time analytics, and near-real-time ETL pipelines.
Exam tip: Datastream supports MySQL, PostgreSQL, and Oracle as source databases. Use it to stream change events to BigQuery, Cloud Storage, or Pub/Sub for downstream processing.
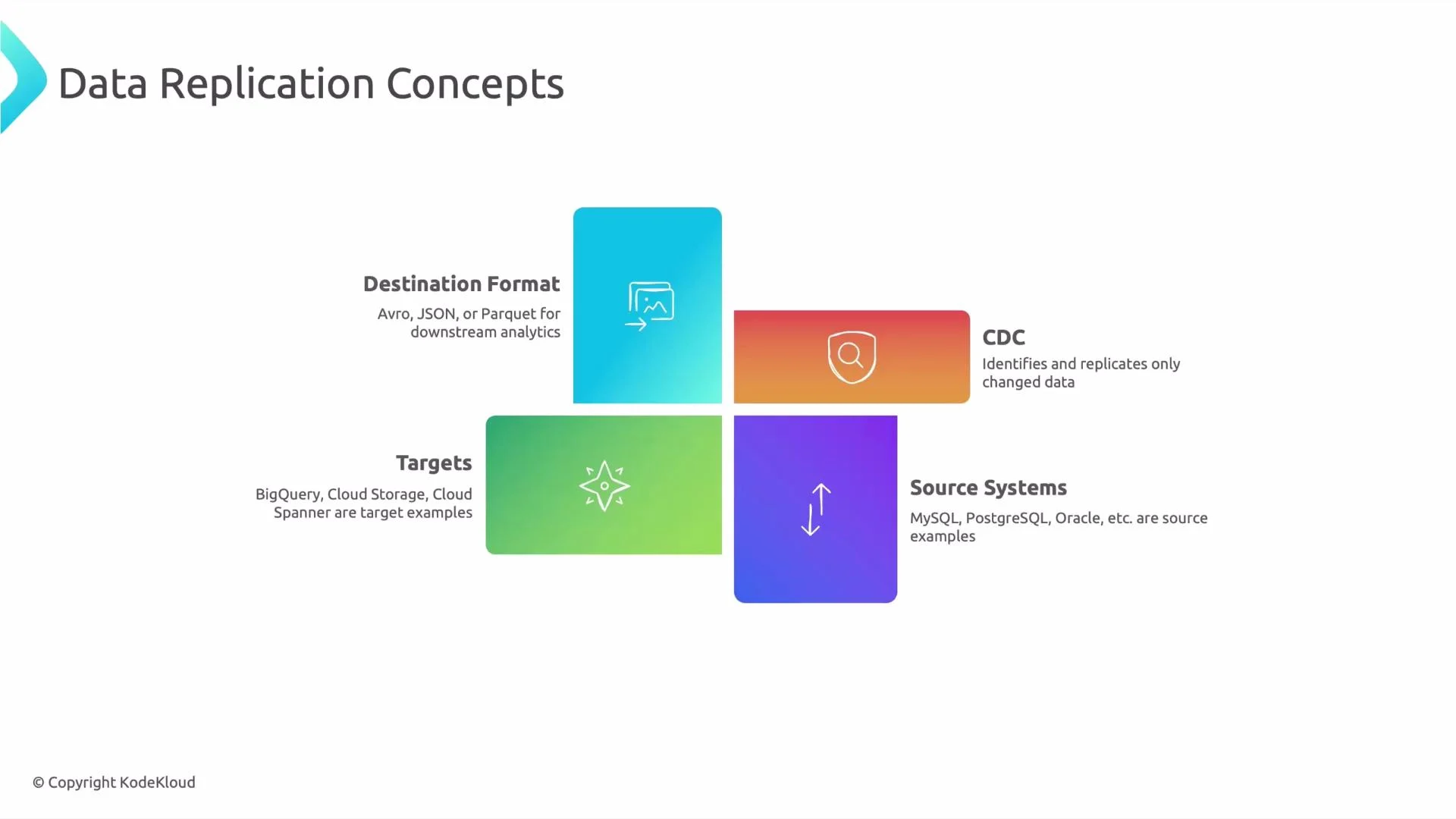
How Datastream works (high level)
- Application writes data to the source database (inserts/updates/deletes).
- Datastream monitors database transaction logs (e.g., MySQL binlog, PostgreSQL WAL, Oracle redo logs) to capture changes in order.
- The CDC engine parses and optionally filters events (by table, schema, column, or operation).
- Datastream writes change events to the configured destination (BigQuery, Cloud Storage, Pub/Sub, etc.) in the chosen format (commonly Avro or JSON).
- Downstream consumers process, transform, or analyze those change events in near real time.
Core components and recommended configurations
Supported sources and typical targets
Lifecycle of a change inside Datastream
- Log capture: Datastream reads the database transaction log to capture a reliable, ordered sequence of changes.
- Parse & filter: Logs are parsed into structured change events; filters (tables, columns, or operation types) can be applied to reduce noise.
- Delivery: Events are written to the destination in the configured format.
- Ordering & duplicates: Ordering is preserved as captured from transaction logs. Deduplication and exact delivery semantics depend on destination and consumer-side logic.
Important: CDC requires database transaction logging (e.g., MySQL binlog or PostgreSQL WAL), which may be disabled by default. Ensure transaction logs are enabled and that Datastream has network access and the necessary permissions to read them. Coordinate changes with your DBA or infra team before creating streams.
Practical checklist before creating a Datastream stream
- Enable transaction logs on the source:
- MySQL: enable
binlog - PostgreSQL: enable
WALand logical replication settings - Oracle: enable redo logs and supplemental logging
- MySQL: enable
- Ensure network connectivity:
- VPC peering, private IP, or public connectivity with proper firewall rules
- Service account permissions:
- Grant Datastream and any downstream services the needed IAM roles
- Define scope:
- Choose tables/schemas to replicate, and whether to include DDL or only DML
- Choose output format and destination:
- Avro or JSON for change events; convert to Parquet later for analytics if needed
- Plan for ordering & de-duplication:
- Implement idempotent consumers or deduplication logic where required
Example real-world scenario
E-commerce platform: Orders are created in a transactional database. Datastream captures new order inserts and updates, writes change events to Pub/Sub and Cloud Storage, and streams orders into BigQuery (via Dataflow or a native connector) for dashboards, fraud detection, and shipment workflows. This keeps downstream systems up to date without impacting OLTP performance.When to use Datastream
- Need low-latency replication of database changes with minimal source impact
- Want a managed CDC solution integrated with Google Cloud destinations
- Building event-driven architectures, streaming ETL, or real-time analytics
Further reading and references
- Datastream documentation: https://cloud.google.com/datastream
- Cloud Pub/Sub: https://cloud.google.com/pubsub
- BigQuery: https://cloud.google.com/bigquery
- Database CDC concepts: https://martinfowler.com/articles/201701-event-sourcing.html