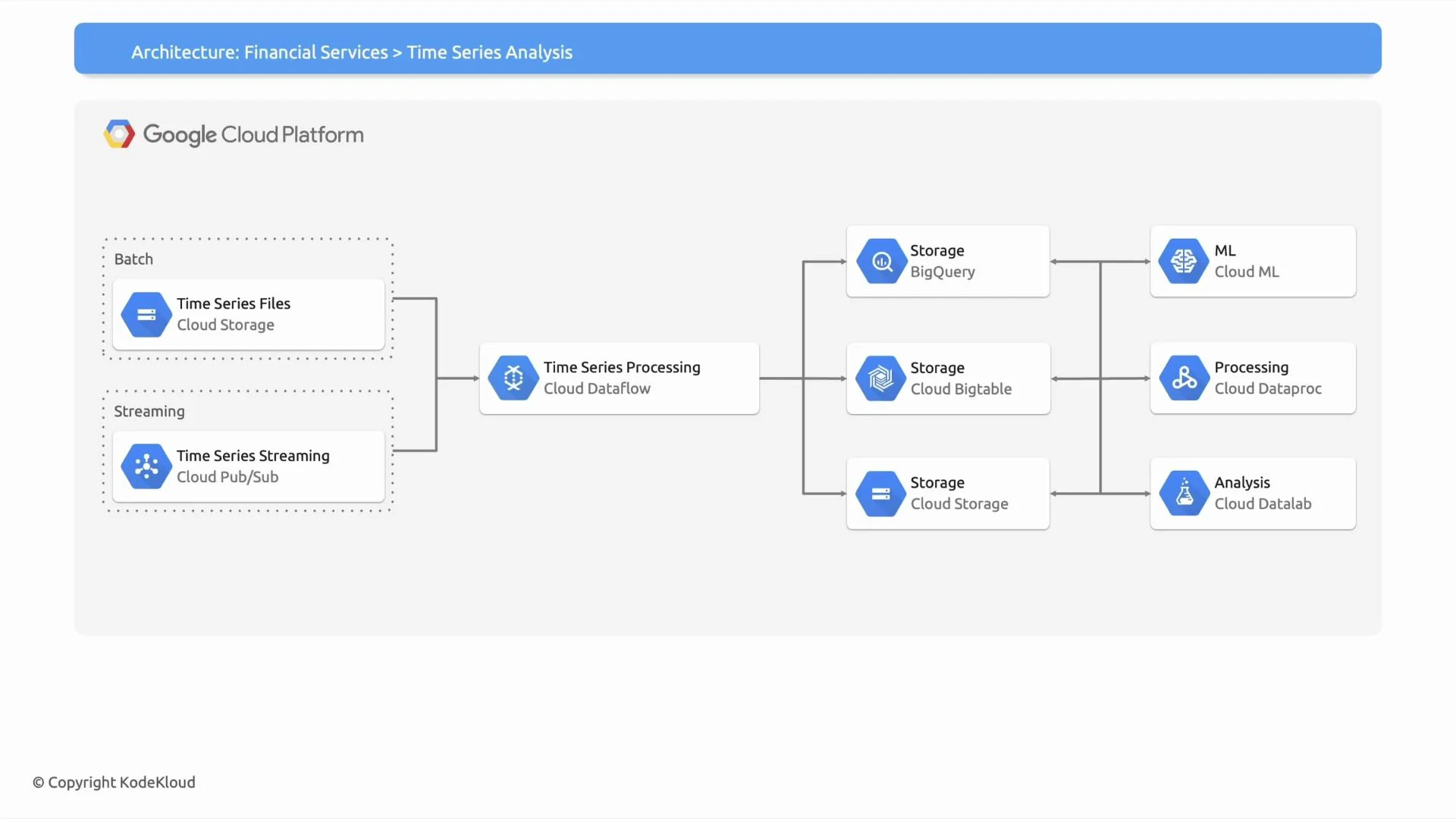
Use case and ingestion
- Use case: internal time-series analysis (monitoring, IoT, metrics, financial ticks, etc.).
- Ingestion patterns: both streaming (near real-time) and batch (file-based) data arrive into the system.
Storage choice: Cloud Storage vs Cloud Bigtable
Choosing between Cloud Storage and Cloud Bigtable depends on access patterns, latency requirements, and operational goals.Start with Cloud Storage for raw/batch files to reduce cost and complexity. Adopt Cloud Bigtable when your workload demands low-latency point reads/writes, sustained high throughput, and you can design efficient row keys for time-window access patterns.
If you choose Cloud Bigtable, plan your row-key carefully. Poor row-key design can lead to hotspotting and degraded performance for time-series workloads.
Processing layer
This architecture uses Cloud Dataflow (Apache Beam) for unified stream and batch processing. Dataflow is a serverless, managed service providing autoscaling, windowing, session handling, and built-in connectors to Pub/Sub, Cloud Storage, BigQuery, and Bigtable. When to consider alternatives:- Use Dataproc (Spark) if you have existing Spark jobs or need specific Spark libraries, notebooks, or custom cluster management.
- Prefer Dataflow when you want a unified programming model for streaming and batch with minimal operational overhead.
Outputs and downstream analysis
Processed outputs typically flow to one or more destinations depending on query patterns and downstream consumers:- Cloud Storage — store raw, windowed, or aggregated files; archive snapshots and large batch outputs.
- Cloud Bigtable — store time-series rows for sub-millisecond lookups and high-throughput point queries.
- BigQuery — store denormalized or aggregated tables for interactive, ad-hoc analytics and reporting.
- Vertex AI / Cloud AI for model training and serving.
- Dataproc (Spark) for specialized heavy analytics or legacy Spark workloads.
- Notebooks and notebook services for experimentation and exploratory analysis.
How to think about service selection
When evaluating components ask:- Which service minimizes operational burden while meeting functional needs?
- Which service will provide the required features at scale and over time?
- Do we need serverless autoscaling and unified semantics (Dataflow), or specific Spark features (Dataproc)?
- Are low-latency point reads required (Bigtable) or are batch/analytical queries more important (BigQuery/Cloud Storage)?
- Start: Ingest files to Cloud Storage, streams to Pub/Sub, process with Dataflow.
- If you need interactive analytics and SQL, push aggregates to BigQuery.
- If you need low-latency, high-throughput row access, move processed time-series rows to Bigtable.
- For specialized Spark work or migration, use Dataproc.