- What preemptible VMs are and their trade-offs
- Typical use cases where they make sense
- Cost example and potential savings
- Dataproc architecture recommendations and safe configurations
What are preemptible VMs?
Preemptible VMs are Google Cloud Compute instances offered at a significant discount in exchange for being short-lived and interruptible. They are ideal for workloads that tolerate interruptions, retries, or checkpointing. Key characteristics:- Short-lived: Google can terminate them at any time; maximum lifespan is 24 hours.
- Cost-effective: often up to ~70% cheaper than equivalent regular VMs.
- Ephemeral: instances can disappear unexpectedly, so applications must handle interruptions (retries, resumable tasks, or external durable storage).
Preemptible VMs are best for non-critical, fault-tolerant workloads. Google provides a brief shutdown notice (about 30 seconds) before preemption so your application can checkpoint or attempt a graceful shutdown.
When to use preemptible VMs
Preemptible VMs are most appropriate when your workload is tolerant of interruptions or non-time-critical. Common scenarios include:- Batch processing: analytics jobs or ETL pipelines that can be re-run or checkpointed.
- Testing and development: cost-conscious environments for experiments or CI tasks.
- Fault-tolerant jobs: distributed computations designed to recover from worker loss (e.g., Spark with external shuffle/storage).

Cost example
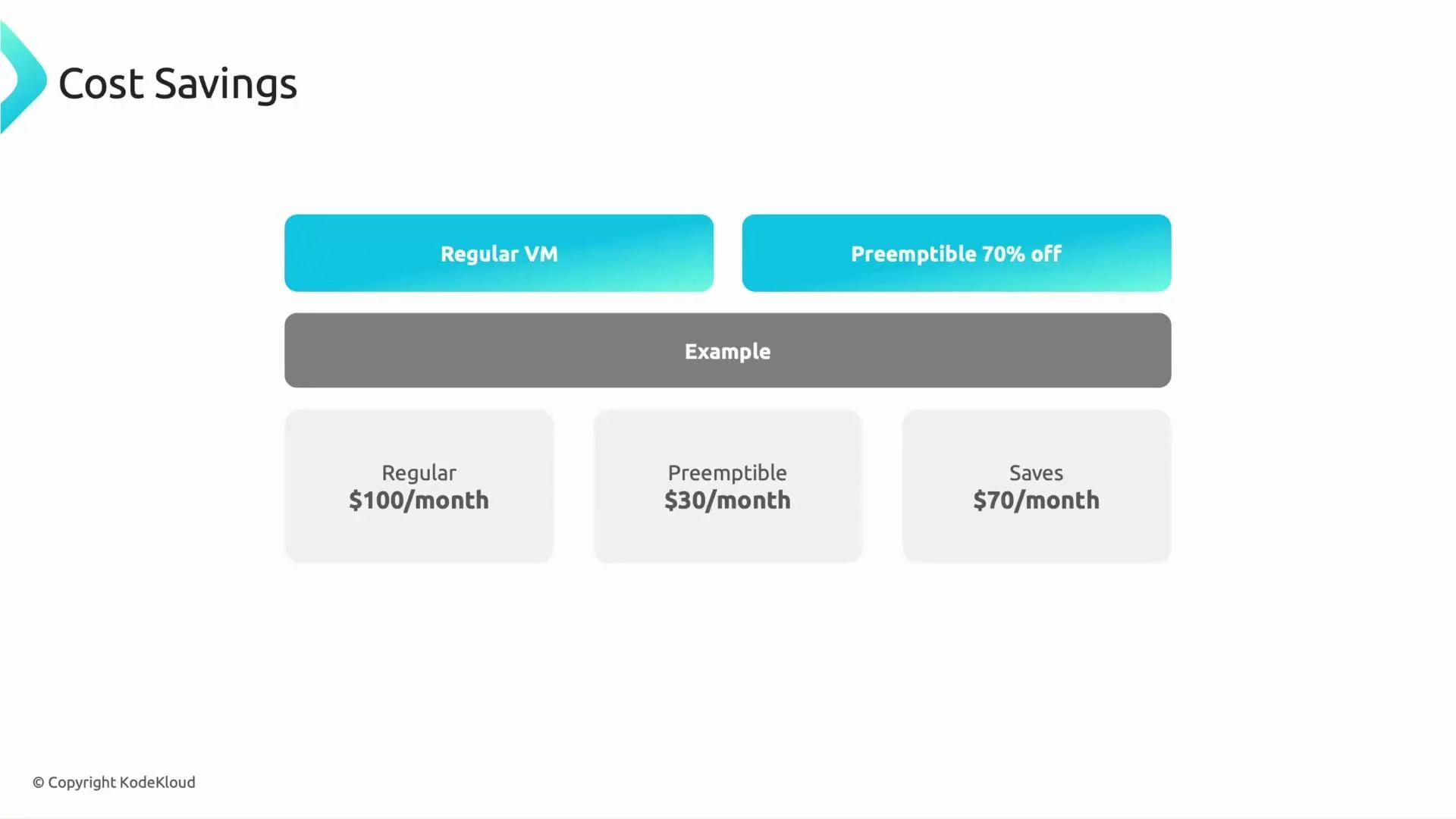
A simple illustration highlights the impact on cost:- Regular worker VM: $100/month
- Preemptible worker VM: $30/month (≈70% discount)
- Savings per instance: $70/month
Dataproc architecture and best practices
Design your Dataproc clusters with a mix of regular and preemptible VMs to balance reliability and cost. Recommendations:- Master nodes: always use regular (non-preemptible) VMs. Masters manage cluster metadata and services; losing a master can make the cluster unavailable.
- Worker nodes:
- If the cluster relies on HDFS or local-disk storage for primary data replicas, avoid making those nodes preemptible.
- If your workloads read/write to durable external storage (Cloud Storage, BigQuery), worker nodes can be preemptible.
- Secondary/autoscaled workers: use preemptible instances to provide burst capacity for short-lived, compute-intensive periods.
- Use checkpointing, idempotent job design, or job retries so work can be resumed after preemption.
Do not run primary HDFS replicas on preemptible VMs. If HDFS data nodes are preempted, you risk data loss or long recovery due to re-replication. Prefer external durable storage (Cloud Storage, BigQuery) when using preemptible workers.

Practical tips
- Use managed services and external durable storage where possible to decouple compute from storage.
- Design Spark or Hadoop jobs to be idempotent or checkpoint progress so retries after preemption are efficient.
- Consider mixing instance types and zones to reduce the chance of simultaneous preemptions.
- Monitor preemption events and automate cluster rebalancing or worker replacement (Dataproc supports autoscaling and preemptible worker pools).