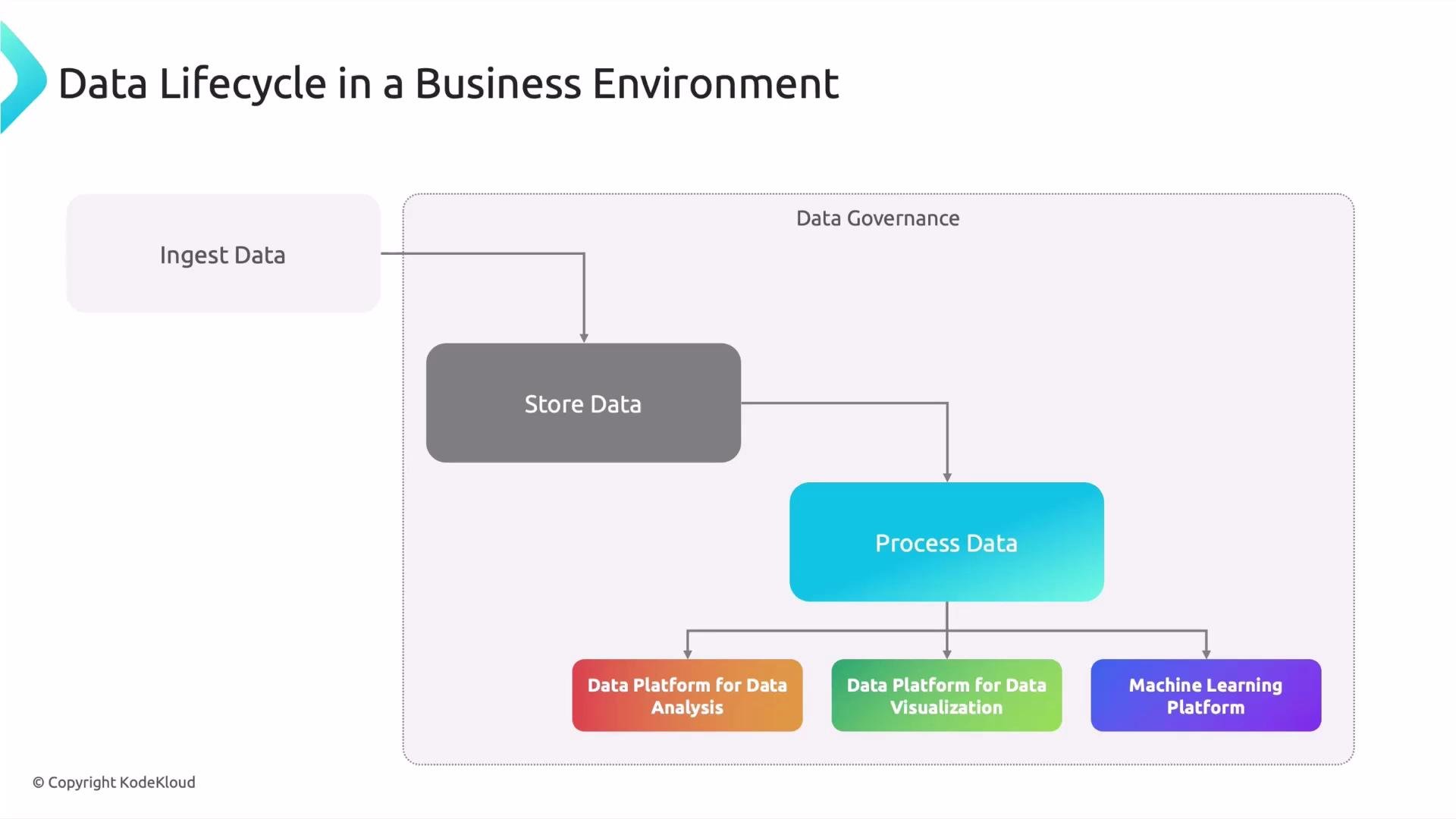
Ingesting data
Ingestion is the entry point where raw data enters your systems. Typical sources include web and mobile activity, IoT sensor streams, transactional systems, and third-party feeds. Two common ingestion patterns:
Design trade-offs at this stage affect system complexity, cost, and timeliness of insights. Consider throughput, retention, ordering, and exactly-once vs at-least-once semantics when selecting an ingestion strategy.
Storing data
After ingestion, persist data in systems designed for durability, discoverability, and appropriate access patterns:
Apply schema design, partitioning, and lifecycle policies (retention, tiering) so downstream consumers can efficiently find and process the data.
Processing data
Processing transforms raw streams and files into reliable datasets for analytics and ML:- Cleaning: remove corrupt records, normalize formats, deduplicate.
- Enrichment: join lookup tables (user attributes, product catalogs) and add derived fields.
- Transformation: aggregations, filtering, reshaping (wide → narrow), and feature engineering for ML.
- Validation: schema checks, completeness checks, and anomaly detection to catch issues early.
Connecting data to business platforms
Processed data is consumed by multiple platforms, each with different shape and freshness requirements:- Data analysis: ad hoc queries for discovery and hypothesis testing.
- Data visualization: dashboards/reports for business users and leadership (e.g., Looker, Tableau, Looker Studio).
- Machine learning: training datasets and serving features for models (recommendation, forecasting, anomaly detection).
Data governance (the umbrella)
Governance ensures that data is secure, compliant, and trustworthy across the entire lifecycle:- Access controls and encryption: prevent unauthorized access and data leaks.
- Lineage and metadata: trace data provenance and transformations for auditability.
- Policies: retention, masking, and privacy controls aligned with regulations.
- Monitoring and observability: pipeline health, SLA alerts, and data-quality dashboards.
Apply automated quality checks and monitoring early in the pipeline. It’s far cheaper to detect and fix data issues during processing than to debug problems after they appear in production dashboards or models.
Best practices (summary)
- Define clear SLAs for freshness and availability per use case.
- Instrument pipelines with metrics: latency, throughput, error rates.
- Use immutable raw stores for reproducibility and replayability.
- Maintain a canonical metadata catalog and record lineage for auditability.
- Tailor storage formats and partitioning to query patterns (e.g., columnar formats for analytics).
Recap
- Data typically flows: ingestion → storage → processing → consumption (analytics, visualization, ML).
- Governance, monitoring, and automated quality checks should span the entire lifecycle to ensure reliable, compliant insights.
- Choose the right ingestion pattern and storage architecture based on latency, cost, and access requirements.