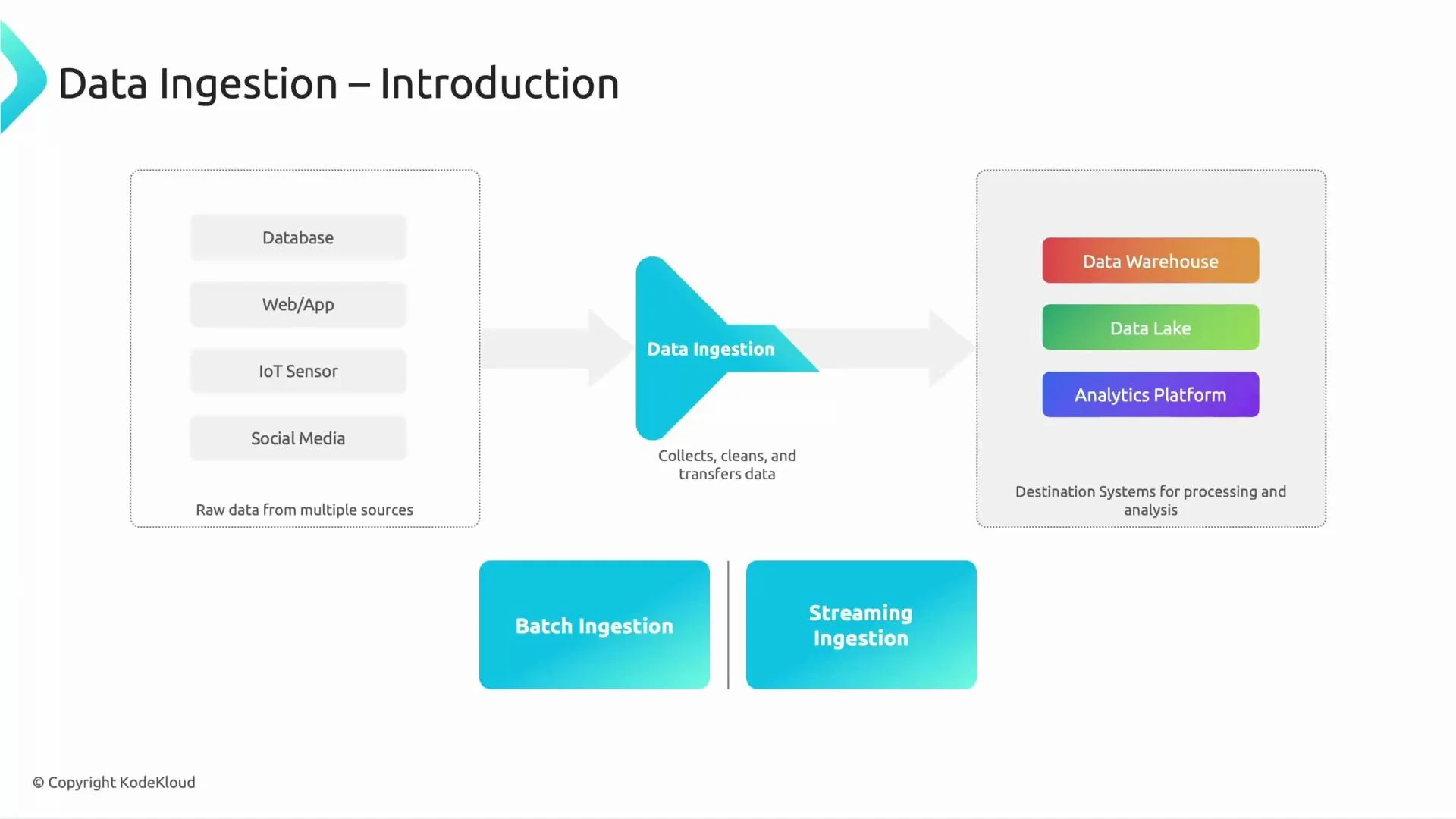
- Raw data sources
The original, unprocessed data from systems such as transactional databases, application logs, IoT sensors, or social media feeds. - Ingestion framework
The mechanisms or services that pull or receive data from sources: connectors, agents, APIs, or messaging systems (for example, change-data-capture connectors, log collectors, or Pub/Sub). - Staging / raw landing
Where ingested raw data is stored (often a data lake or staging bucket). This stage usually includes lightweight validation, schema tagging, and deduplication; heavier enrichment and joins occur later in processing. - Processing and transformation
Jobs or streaming processors that clean, normalize, and enrich data to create analysis-ready datasets. - Final storage and consumption
Processed datasets are written to destinations such as a data warehouse, curated data lake, or analytics platform for reporting, dashboards, or downstream ML pipelines.
Choosing the right ingestion approach affects latency, throughput, operational complexity, and how you handle ordering, duplicates, and failures. Consider business SLAs (latency vs. completeness), data volume, and toolchain maturity when designing your ingestion layer.
- The ingestion pattern determines end-to-end latency, resource usage, fault tolerance, and operational complexity.
- It affects the choice of tools and architecture (batch schedulers, stream processors, messaging systems, CDC tools).
- It drives design decisions for ordering, exactly-once or at-least-once semantics, duplicate handling, and state management.
-
Batch ingestion
- Moves data in discrete groups (batches) on a schedule (hourly, daily, nightly).
- Common use cases: nightly ETL that aggregates yesterday’s transactions; large backfills; bulk data movement to a data warehouse.
- Characteristics: higher end-to-end latency, simpler processing model, easier to reason about correctness for large bulk operations.
- Variants:
- Full loads (replace entire dataset)
- Incremental loads (only new or changed rows)
- Change data capture (
CDC) for near-real-time incremental loads - Micro-batching (small batches at high frequency) as a hybrid to reduce latency
-
Streaming ingestion
- Continuously ingests and processes events in near real time as they are produced.
- Common use cases: live user-event analytics, real-time monitoring, fraud detection, anomaly detection, feature pipelines for online ML.
- Characteristics: low latency, event-driven, often requires windowing semantics, state management, idempotency, and careful handling of event-time vs processing-time.
- Considerations: event ordering, backpressure, checkpointing, retention, and duplicate event handling. Guarantees vary by platform (at-least-once, exactly-once).
Both patterns can coexist in a modern data platform: use batch for large-scale transformations and historical reprocessing, and streaming for low-latency analytics and timely alerts. Hybrid architectures (e.g., streaming ingestion with periodic micro-batch reprocessing) are common.
This lesson examines available GCP services for both batch and streaming ingestion and dives deeper into their technical trade-offs. Common GCP building blocks include Cloud Storage, Cloud Pub/Sub, Dataflow, Dataproc, and BigQuery for different stages of ingestion and processing:
- Ingestion: Cloud Pub/Sub, Transfer Service, direct connector agents, Cloud Storage uploads
- Processing: Dataflow (stream & batch), Dataproc (batch Spark/Hadoop), Cloud Run/Cloud Functions (light-weight ingestion)
- Storage & consumption: Cloud Storage (raw landing), BigQuery (analytics), BigTable/Firestore (low-latency lookups)
Be careful with ordering and deduplication. Streaming systems often deliver at-least-once by default; implement idempotent writes or deduplication windows in sinks to avoid data inflation. When exact ordering matters, design with partition keys and windowing semantics in mind.
- Google Cloud Pub/Sub documentation
- Google Cloud Dataflow documentation
- BigQuery ingestion best practices
- Change Data Capture (CDC) patterns